在MySQL中最好所有数据都用英文表示,中文实在搞不成功!!!
数据库的三种类型:层次模型,网状模型,关系模型。
数据类型
关系数据库支持的标准数据类型包括数值、字符串、时间等

操作数据库的能力
DDL:Data Definition Language
DDL允许用户定义数据,也就是创建表、删除表、修改表结构这些操作。通常,DDL由数据库管理员执行。
DML:Data Manipulation Language
DML为用户提供添加、删除、更新数据的能力,这些是应用程序对数据库的日常操作。
DQL:Data Query Language
DQL允许用户查询数据,这也是通常最频繁的数据库日常操作。
语法特点
SQL语言关键字不区分大小写!!!但是,针对不同的数据库,对于表名和列名,有的数据库区分大小写,有的数据库不区分大小写。同一个数据库,有的在Linux上区分大小写,有的在Windows上不区分大小写。
关系模型
表的每一行称为记录(Record),记录是一个逻辑意义上的数据。
表的每一列称为字段(Column),同一个表的每一行记录都拥有相同的若干字段。
字段定义了数据类型(整型、浮点型、字符串、日期等),以及是否允许为NULL。注意NULL表示字段数据不存在。一个整型字段如果为NULL不表示它的值为0,同样的,一个字符串型字段为NULL也不表示它的值为空串’ ‘。
通常情况下,字段应该避免允许为NULL。不允许为NULL可以简化查询条件,加快查询速度,也利于应用程序读取数据后无需判断是否为NULL。
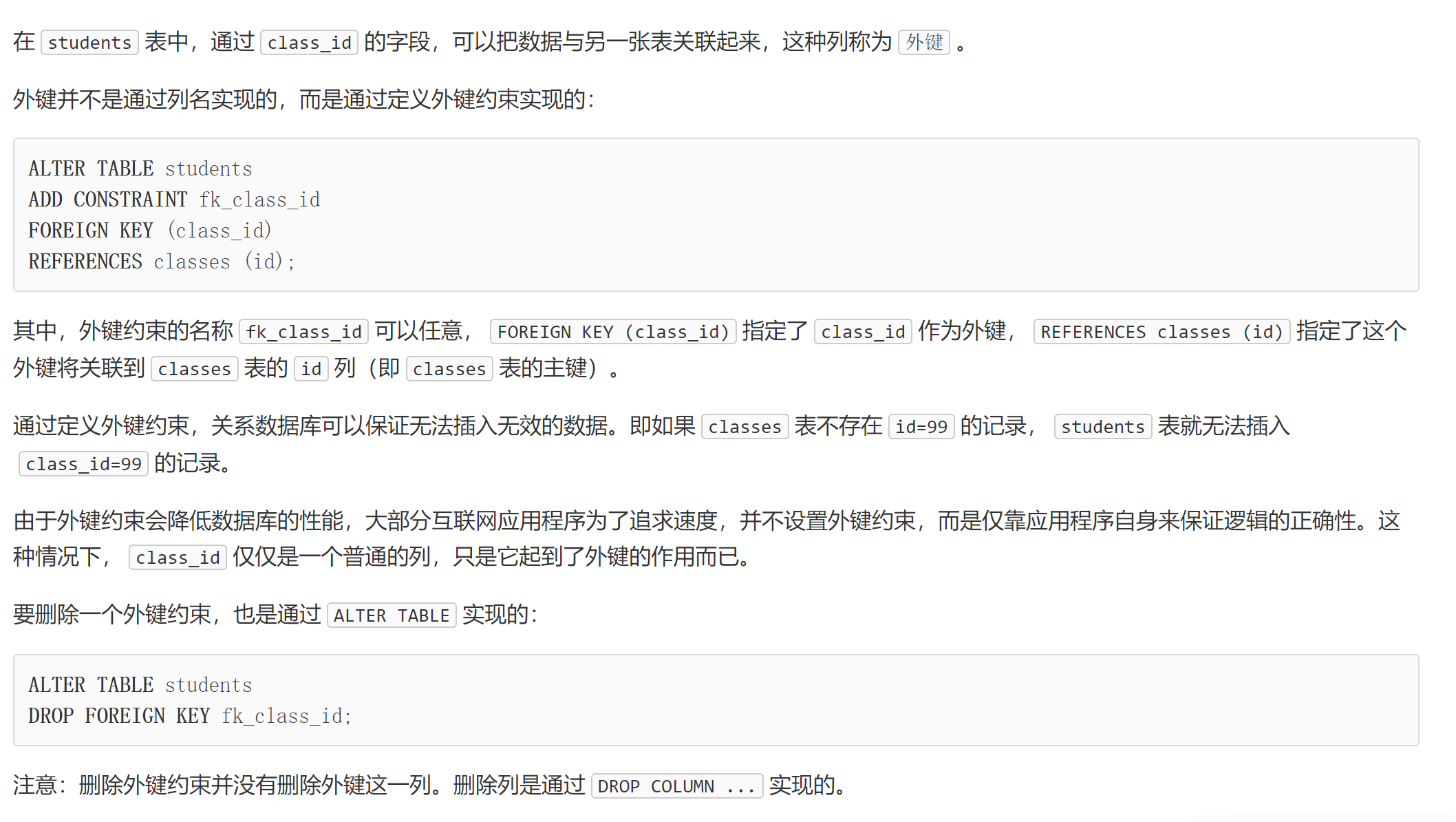
在关系数据库中,关系是通过主键和外键来维护的。
主键
对于关系表,有个很重要的约束,就是任意两条记录不能重复。不能重复不是指两条记录不完全相同,而是指能够通过某个字段唯一区分出不同的记录,这个字段被称为主键。(主键不能够一样)
对主键的要求,最关键的一点是:记录一旦插入到表中,主键最好不要再修改,因为主键是用来唯一定位记录的,修改了主键,会造成一系列的影响。
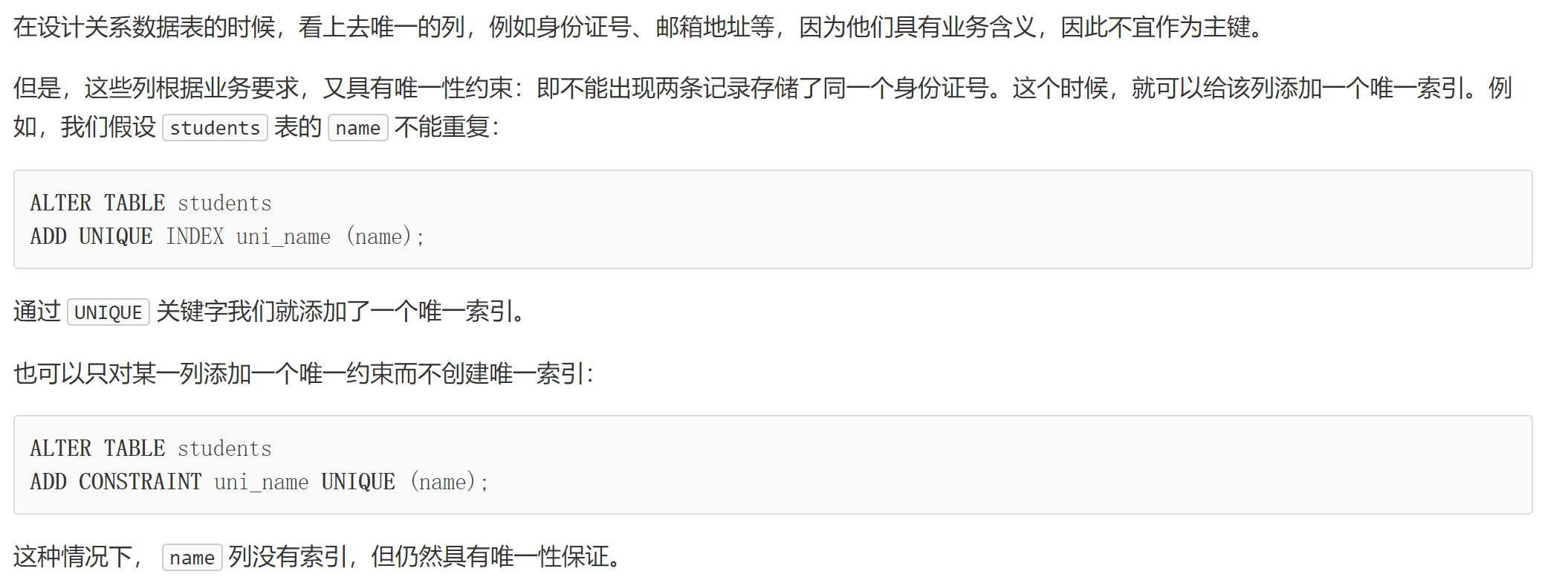
选取主键的一个基本原则是:不使用任何业务相关的字段作为主键。(手机号码,身份证号码,邮箱地址皆不行)
主键的字段一般命名为id,常见可做id字段类型的类型有:
1.自增整数类型:数据库会在插入数据时自动为每一条记录分配一个自增整数,这样我们就完全不用担心主键重复,也不用自己预先生成主键;
2.全局唯一GUID类型:使用一种全局唯一的字符串作为主键。
联合主键:关系数据库实际上还允许通过多个字段唯一标识记录,即两个或更多的字段都设置为主键
对于联合主键,允许一列有重复,只要不是所有主键列都重复即可。(一般不使用联合主键,避免更加复杂)
外键
多对多
通过一个表的外键关联到另一个表,我们可以定义出一对多关系。有些时候,还需要定义“多对多”关系。例如,一个老师可以对应多个班级,一个班级也可以对应多个老师,因此,班级表和老师表存在多对多关系。
多对多关系实际上是通过两个一对多关系实现的,即通过一个中间表,关联两个一对多关系,就形成了多对多关系:

一对一
一对一关系是指,一个表的记录对应到另一个表的唯一一个记录。
总的:关系数据库通过外键可以实现一对多、多对多和一对一的关系。外键既可以通过数据库来约束,也可以不设置约束,仅依靠应用程序的逻辑来保证。
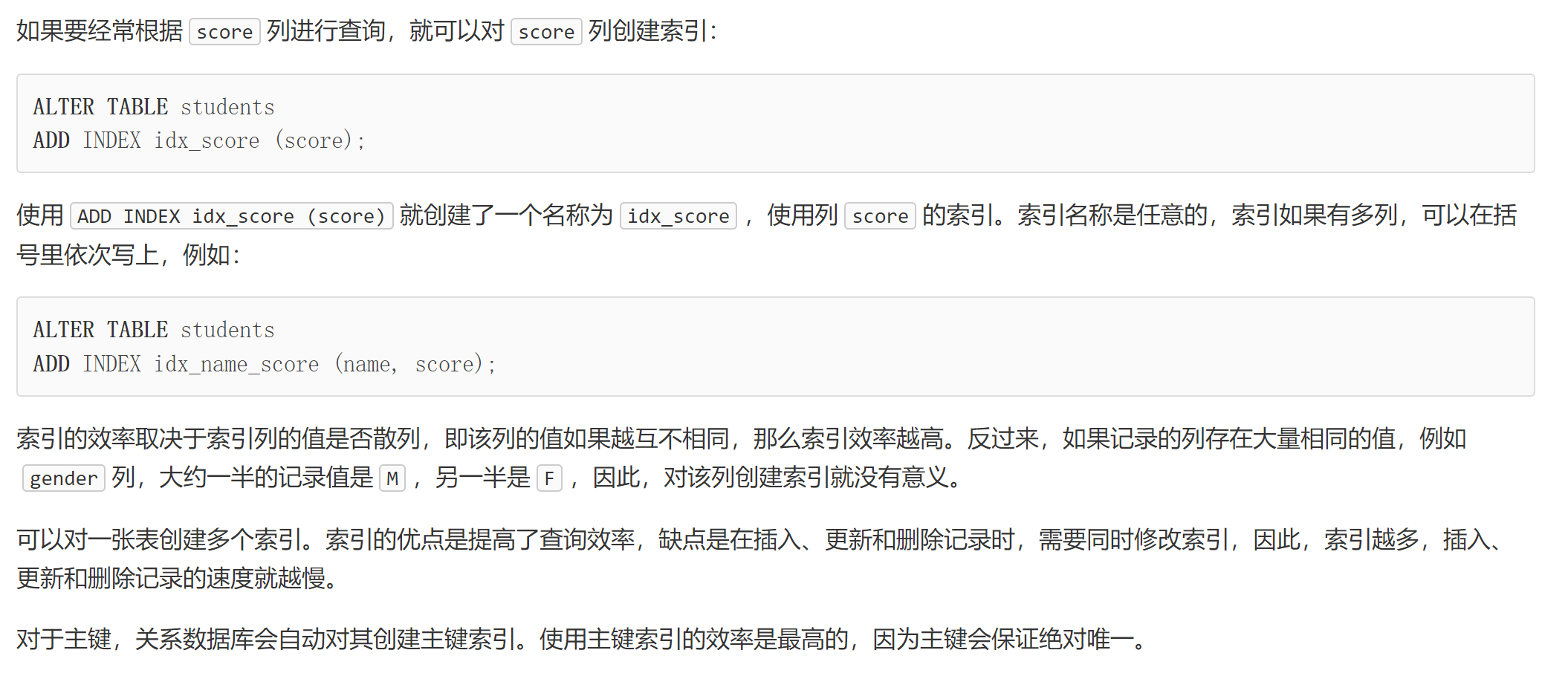
索引
索引是关系数据库中对某一列或多个列的值进行预排序的数据结构。
唯一索引
导入数据
先创建database(例子:create database 文件名;)
然后 sorce 文件路径;例子:source C:\Users\BD\MySQLwenjian\bilibili.sql;注意路径中不要有中文
只看表的结构
desc <表名>;
查询数据
基本查询
查询数据库表的数据:SELECT * FROM 表名;
SELECT 也可以用于计算(例如:SELECT 100 + 200;)
条件查询
基本
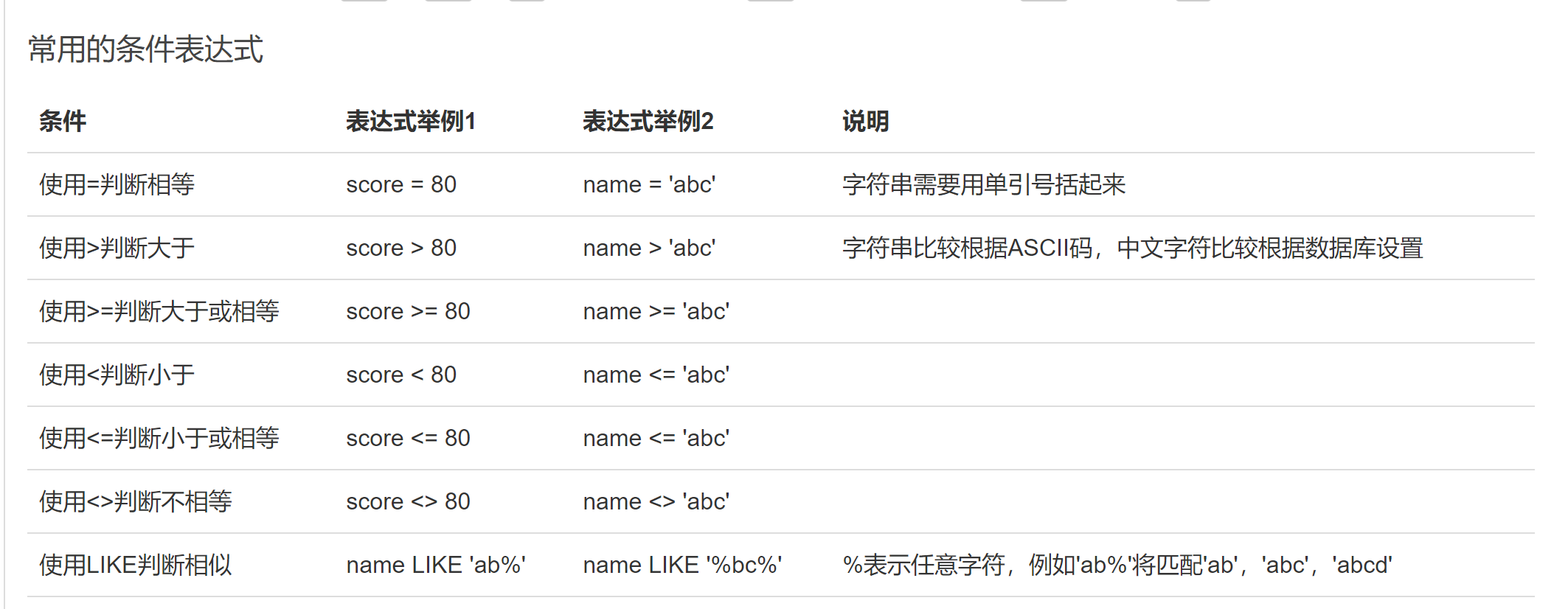
SELECT语句通过WHERE条件来设定查询条件:SELECT * FROM <表名> WHERE <条件表达式>
(例如:SELECT * FROM students WHERE score>=80;)
条件表达式:1.**<条件1> AND <条件2>**表达满足条件1并且满足条件2
2.**<条件1> OR <条件2>**表示满足条件1或者满足条件2
3**. NOT <条件>**,表示“不符合该条件”的记录(例如:写一个“不是2班的学生”这个条件:NOT class_id = 2:)
要组合三个或者更多的条件,就需要用小括号()表示如何进行条件运算
(例:SELECT * FROM students WHERE (score < 80 OR score > 90) AND gender = ‘M’;)
如果不加括号,条件运算按照NOT、AND、OR的优先级进行,即NOT优先级最高,其次是AND,最后是OR
模糊查询
like;支持%或下划线匹配
%匹配任意多个字符;下划线是任意一个字符
例子:SELECT ename from emp where ename like'%o%';(表示名字中间含’O’的)
SELECT ename from emp where ename like'%T';(表示名字以’T’结尾)
SELECT ename from emp where ename like'_A%';(表示第二个字母是’A’)
子查询
where中的子查询
例子:找出比最低工资高的员工
SELECT ename,sal FROM emp WHERE sal>(SELECT min(sal) FROM emp);
from子句中的子查询
from后面的子查询,可以将子查询的查询结果当作一张临时表(技巧)
例子:找出每个岗位的平均工资的薪资等级
SELECT
t,s.grade
from
(select job,avg(sal) avgsal from emp group by job) t
join
salgrade s
on
t.avgsal between s.losal and s.hisal;
select后的子查询
了解了解就好
注意:对于select后面的子查询来说,这个子查询只能一次返回一条结果,多余一条就会报错
投影查询
如果我们只希望返回某些列的数据,而不是所有列的数据,我们可以用SELECT 列1, 列2, 列3 FROM …,让结果集仅包含指定列。这种操作称为投影查询。(例:SELECT id,name,score FROM students;)
使用SELECT 列1, 列2, 列3 FROM …时,还可以给每一列起个别名,这样,结果集的列名就可以与原表的列名不同。它的语法是SELECT 列1 别名1, 列2 别名2, 列3 别名3 FROM …
投影查询同样可以接WHERE条件,实现复杂的查询
总的应用一下:SELECT id, score points, name FROM students WHERE gender = 'M';
排序
如果要按我们自己的排序而不是按主键排序则加上ORDER语句
SELECT id, name, gender, score FROM students ORDER BY score;
如果要反过来,按照成绩从高到底排序,我们可以加上DESC表示“倒序”(DESC加在score后面),如果score列有相同的数据那么可以继续添加列名
如果有WHERE子句,那么ORDER BY子句要放到WHERE子句后面
SELECT id, name, gender, score FROM students WHERE class_id = 1 ORDER BY score DESC;(多个字段排序字段之间加’,’ ,前面起主导作用)
分页查询
使用SELECT查询时,如果结果集数据量很大,比如几万行数据,放在一个页面显示的话数据量太大,不如分页显示,每次显示100条。
要实现分页功能,实际上就是从结果集中显示第1100条记录作为第1页,显示第101200条记录作为第2页,以此类推。
语句:LIMIT <N-M> OFFSET <M>(
例子:SELECT id, name, gender, score
FROM students
ORDER BY score DESC
LIMIT 3 OFFSET 0;
LIMIT 3 OFFSET 0表示,对结果集从0号记录开始,最多取3条。注意SQL记录集的索引从0开始。
如果要查询第2页,那么我们只需要“跳过”头3条记录,也就是对结果集从3号记录开始查询,把OFFSET设定为3。
注意:OFFSET是可选的,如果只写LIMIT 15,那么相当于LIMIT 15 OFFSET 0;
在MySQL中,LIMIT 15 OFFSET 30还可以简写成LIMIT 30, 15;
OFFSET超过了查询的最大数量并不会报错,而是得到一个空的结果集。
聚合查询
对于统计总数、平均数这类计算,SQL提供了专门的聚合函数,使用聚合函数进行查询,就是聚合查询
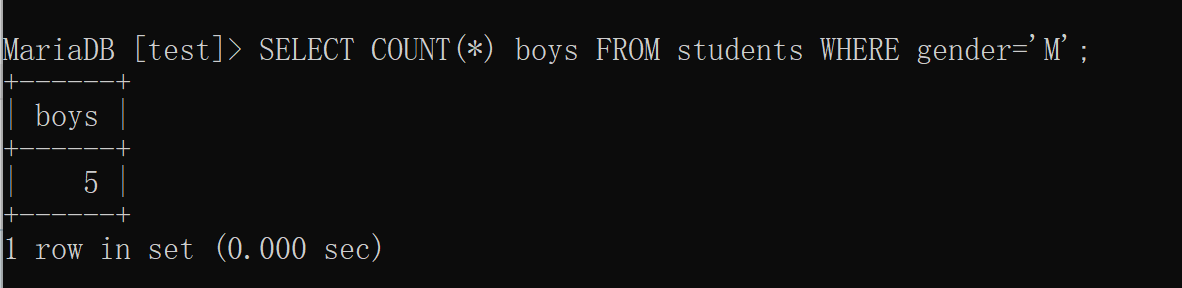
查询一个表中一共有多少条记录可以用COUNT()函数(SELECT COUNT(*) FROM students;)
使用聚合查询时,我们应该给列名设置一个别名,便于处理结果(SELECT COUNT(*) num FROM students;)
count(*)与count(具体字段)的区别:前一个统计总行数,后一个统计该字段下所有不为NULL的元素总和
聚合查询同样可以使用WHERE条件
其他聚合函数
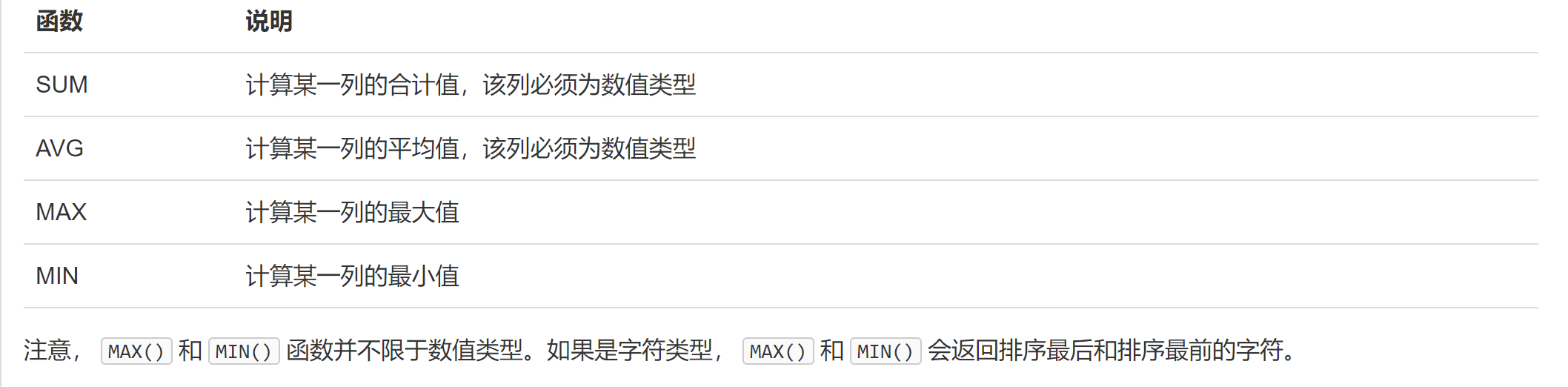
AVG:SELECT AVG(score) average FROM students WHERE gender = 'M';
注意:聚合函数自动忽略NULL
聚合函数不能直接用在WHERE子句中,因为聚合函数在使用时必须先分组才能使用
如果聚合查询的WHERE条件没有匹配到任何行,COUNT()会返回0,而SUM()、AVG()、MAX()和MIN()会返回NULL
每页3条记录,如何通过聚合查询获得总页数:SELECT CEILING(COUNT(*) / 3) FROM students;
多表查询
语法::SELECT * FROM <表1>, <表2>
这种一次查询两个表的数据,查询的结果也是一个二维表,它是students表和classes表的“乘积”,即students表的每一行与classes表的每一行都两两拼在一起返回。结果集的列数是students表和classes表的列数之和,行数是students表和classes表的行数之积
上述查询的结果集有两列id和两列name,两列id是因为其中一列是students表的id,而另一列是classes表的id,但是在结果集中,不好区分。两列name同理;要解决这个问题,我们仍然可以利用投影查询的“设置列的别名”来给两个表各自的id和name列起别名
例子:
1 | `SELECT` |
FROM子句给表设置别名的语法是FROM <表名1> <别名1>, <表名2> <别名2>(使得投影查询更加的简洁)
连接查询
连接查询是另一种类型的多表查询。连接查询对多个表进行JOIN运算,简单地说,就是先确定一个主表作为结果集,然后,把其他表的行有选择性地“连接”在主表结果集上。
笛卡尔积现象:当两张表进行连接查询且没有任何条件限制的时候,最终的查询条数是两张表条数的乘积
内连接——INNER JOIN
查询写法:1、先确定主表,仍然使用FROM <表1>的语法;
2、再确定需要连接的表,使用INNER JOIN <表2>的语法;
3、 然后确定连接条件,使用ON <条件…>,这里的条件是s.class_id = c.id,表示students表的class_id列 与 classes表的id列相同的行需要连接;
4、可选:加上WHERE子句、ORDER BY等子句。
等值连接:
1 | SELECT s.id, s.name, s.class_id, c.name class_name, s.gender, s.score |
INNER JOIN只返回同时存在于两张表的行数据,由于students表的class_id包含1,2,3,classes表的id包含1,2,3,4,所以,INNER JOIN根据条件s.class_id = c.id返回的结果集仅包含1,2,3。
非等值连接:条件不是一个等量关系
例子:员工工资在这个工资范围内
1 | SELECT |
自连接:一个表里面自己对应,技巧是一张表看成两张表
例子:找出员工及对应的领导
SELECT -> a.ename yuangong,b.ename leader -> FROM -> emp a -> INNER JOIN -> emp b -> ON -> a.mgr=b.empno;(员工领导编号等于员工编号)
外连接–OUTER JOIN
右外连接:RIGHT OUTER JOIN返回右表都存在的行。如果某一行仅在右表存在,那么结果集就会以NULL填充剩下的字段。
左外连接:LEFT OUTER JOIN则返回左表都存在的行。
FULL OUTER JOIN,它会把两张表的所有记录全部选择出来,并且,自动把对方不存在的列填充为NULL。
例子:SELECT s.id, s.name, s.class_id, c.name class_name, s.gender, s.scoreFROM students sRIGHT OUTER JOIN classes c(outer可以省略)ON s.class_id = c.id;
多个表进行连接
select.....
from a
join b
on a和b的连接条件
join c
on a和c的连接条件
join d
on a和d的连接条件
一条SQL中内连接和外连接可以混合
DISTINCT
作用:查询结果去除重复记录,但原表记录不会被修改
基础语法:SELECT DISTINCT 字段 FROM <表名>;
DINSTINCT只能出现在所有字段的最前方
例子:SELECT DISTINCT job,number FROM <表名>;表示job,number两个同时去重
分组查询
select…from…where…group by…order by…执行顺序是from,where,group by,select,order by
分组语句:GROUP BY(例:SELECT COUNT(*) num FROM students GROUP BY class_id;)
也可以使用多个列进行分组
(SELECT class_id, gender, COUNT(*) num FROM students GROUP BY class_id, gender;)
(注意:在一条select语句当中,如果有grorup by语句的话,select后面只能跟参加分组的字段,以后分组函数,其他的一律不能跟。
例子:SELECT deptno,max(sal) from emp group by deptno;)
使用having可以对分完组之后的数据进一步过滤,其必须和group by一起用
例子:找出每个部门最高薪资并且要求显示最高薪资大于3000的数据
SELECT deptno,max(sal) FROM emp group by deptno having max(sal)>3000;
WHERE实在没办法了再用having
(例子:找出每个部门的平均薪资,要求显示平均薪资高于2500的)
修改数据
INSERT
当我们需要向数据库表中插入一条新记录时,就必须使用INSERT语句。
语法:INSERT INTO <表名> (字段1, 字段2, …) VALUES (值1, 值2, …);
例子:我们向students表插入一条新记录,先列举出需要插入的字段名称,然后在VALUES子句中依次写出对应字段的值
INSERT INTO students (class_id, name, gender, score) VALUES (2, '大牛', 'M', 80);
可以一次性添加多条记录,只需要在VALUES子句中指定多个记录值,每个记录是由**(…)**包含的一组值,中间用 , 隔开
UPDATE
语法:UPDATE <表名> SET 字段1=值1, 字段2=值2, ... WHERE ...;
例子:UPDATE students SET name='大牛', score=66 WHERE id=1;(WHERE后面是需要更新的行的筛选条件)
UPDATE语句的WHERE条件和SELECT语句的WHERE条件其实是一样的,因此完全可以一次更新多条记录
在UPDATE语句中,更新字段时可以使用表达式
例子:UPDATE students SET score=score+10 WHERE score<80;
注意如果WHERE条件没有匹配到任何记录,UPDATE语句不会报错,也不会有任何记录被更新
要特别小心的是,UPDATE语句可以没有WHERE条件,这个时候整个表的数据都会被更新!!!
DELETE
基本语法:DELETE FROM <表名> WHERE ...;
DELETE语句也可以一次删除多条记录(例:DELETE FROM students WHERE id>=5 AND id<=7;)
与UPDATE语句类似WHERE条件没有匹配到任何记录,DELETE语句不会报错,也不会有任何记录被删除
和UPDATE类似,不带WHERE条件的DELETE语句会删除整个表的数据
在执行DELETE语句时也要非常小心,最好先用SELECT语句来测试WHERE条件是否筛选出了期望的记录集,然后再用DELETE删除。
数据处理函数
又被称为单行处理函数,特点是一个输入对应一个输出
LOWER(转换成小写)
语法:SELECT LOWER(字段) FROM <表名>;
UPPER
转化成大写;语法:SELECT UPPER(字段) FROM <表名>;
SUBSTR
取字符串;基本语法:SUBSTR(截取的字符串,起始下标,截取的长度)(注意:起始下标从1开始)
例子:SELECT SUBSTR(name,1,1) ename from students;
例子:SELECT ename from emp where SUBSTR(ename,1,1)='A';(找出第一个字母是A的人)
LENGTH
取长度;语法:SELECT LENGTH(字段) FROM <表名>;
例子:SELECT LENGTH(name) namelength FROM students;
TRIM
去除前后空白
例子:SELECT * FROM emp WHERE ename=TRIM(' King');(可以试试去除这个函数会发生什么)
ROUND
四舍五入;例子:SELECT round(1234.567,0) result FROM emp;(0表示保留到整数位;-1表示保留到十位数)
RAND
表示生成随机数:SELECT RAND() FROM emp; 例子: SELECT ROUND(RAND()*100,0) FROM emp;(100以内随机数)
IFNULL
可以将NULL转换成一个具体值;基础语法:INFULL(数据,被当作哪个值);
所有数据库中有NULL参与的数学运算最后结果都为NULL,为避免这个现象需要使用IFNULL函数
例子:计算每个员工的年薪: SELECT ename,(sal+IFNULL(comm,0))*12 as yearsal from emp;
(试试去掉IFNULL函数会发生什么)
CASE..WHEN..THEN..WHEN..THEN..ELSE..END
不会修改数据库
例子:当员工为MANAGER的时候工资上调10%,当员工为SALESMAN的时候工资上调50%
SELECT -> ename, -> job, -> (case job when'MANAGER' then sal*1.1 when 'SALESMAN' then sal*1.5 else sal end) newsal -> from emp;
表格相关内容
创建表格
的通用语法:CREATE TABLE <表名>(
列名1 数据类型2,
列名2 数据类型2,
……
列名n 数据类型n
);
数据库类型:
1. int:整数类型
age int,
2. double:小数类型
score double(5,2)
3. date:日期,只包含年月日,yyyy-MM-dd
4. datetime:日期,包含年月日时分秒 yyyy-MM-dd HH:mm:ss
5. timestamp:时间错类型 包含年月日时分秒 yyyy-MM-dd HH:mm:ss
如果将来不给这个字段赋值,或赋值为null,则默认使用当前的系统时间,来自动赋值
6. varchar:字符串
name varchar(20):姓名最大20个字符
zhangsan 8个字符 张三 2个字符
例子:create table student( id int, name varchar(32), age int , score double(4,1), birthday date, insert_time timestamp );
复制表:CREATE table 表名 like 被复制的表名;
查询某个数据库中所有的表名称: show tables; 查询表结构:desc 表名;
修改
- 修改表名
alter table 表名 rename to 新的表名;
2. 修改表的字符集
alter table 表名 character set 字符集名称;
3. 添加一列
alter table 表名 add 列名 数据类型;
4. 修改列名称 类型
alter table 表名 change 列名 新列别 新数据类型;
alter table 表名 modify 列名 新数据类型;
5. 删除列
alter table 表名 drop 列名;
删除
语法:drop table 表名;