python基础
数据类型转换
int() 强制转换为整型
float() 强制转换为浮点型
str() 强制转换为字符串类型
1 | x = str("s1") # x 输出结果为 's1' |
整型和字符串类型进行运算,就可以用强制类型转换来完成
1 | num_int = 123 |
运算符
python位运算符
按位运算符是把数字看作二进制来进行计算的
假设a=60,b=13二进制格式为:a = 0011 1100;b = 0000 1101
| 运算符 | 描述 | 实测 |
|---|---|---|
| & | 按位与运算符:参与运算的两个值,如果两个相应位都为1,则该位的结果为1,否则为0 | (a & b) 输出结果 12 ,二进制解释: 0000 1100 |
| | | 按位或运算符:只要对应的二个二进位有一个为1时,结果位就为1 | (a|b)输出结果 61 ,二进制解释: 0011 1101 |
| ^ | 按位异或运算符:当两对应的二进位相异时,结果为1 | (a ^ b) 输出结果 49 ,二进制解释: 0011 0001 |
| ~ | 按位取反运算符:对数据的每个二进制位取反,即把1变为0,把0变为1。**~x** 类似于 -x-1 | (~a ) 输出结果 -61 ,二进制解释: 1100 0011, 在一个有符号二进制数的补码形式。 |
| << | 左移动运算符:运算数的各二进位全部左移若干位,由”<<”右边的数指定移动的位数,高位丢弃,低位补0。 | a << 2 输出结果 240 ,二进制解释: 1111 0000 |
| >> | 右移动运算符:把”>>”左边的运算数的各二进位全部右移若干位,”>>”右边的数指定移动的位数 | a >> 2 输出结果 15 ,二进制解释: 0000 1111 |
逻辑运算符
a=10,b=20
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔”与” - 如果 x 为 False,x and y 返回 x 的值,否则返回 y 的计算值 | (a and b) 返回 20。 |
| or | x or y | 布尔”或” - 如果 x 是 True,它返回 x 的值,否则它返回 y 的计算值。 | (a or b) 返回 10。 |
| not | not x | 布尔”非” - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 | not(a and b) 返回 False |
成员运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回 False | x 在 y 序列中 , 如果 x 在 y 序列中返回 True |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False | x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True |
1 | a = 10 |
身份运算符
身份运算符用于比较两个对象的存储单元(就是地址)
| 运算符 | 描述 | 实例 |
|---|---|---|
| is | is 是判断两个标识符是不是引用自一个对象 | x is y, 类似 id(x) == id(y) , 如果引用的是同一个对象则返回 True,否则返回 False |
| is not | is not 是判断两个标识符是不是引用自不同对象 | x is not y , 类似 **id(x) != id(y)**。如果引用的不是同一个对象则返回结果 True,否则返回 False |
id()函数用于获取对象内存地址
数字
数学函数
随机数函数
三角函数
数学常量
| 常量 | 描述 |
|---|---|
| pi | 数学常量 pi(圆周率,一般以π来表示) |
| e | 数学常量 e,e即自然常数(自然常数) |
字符串
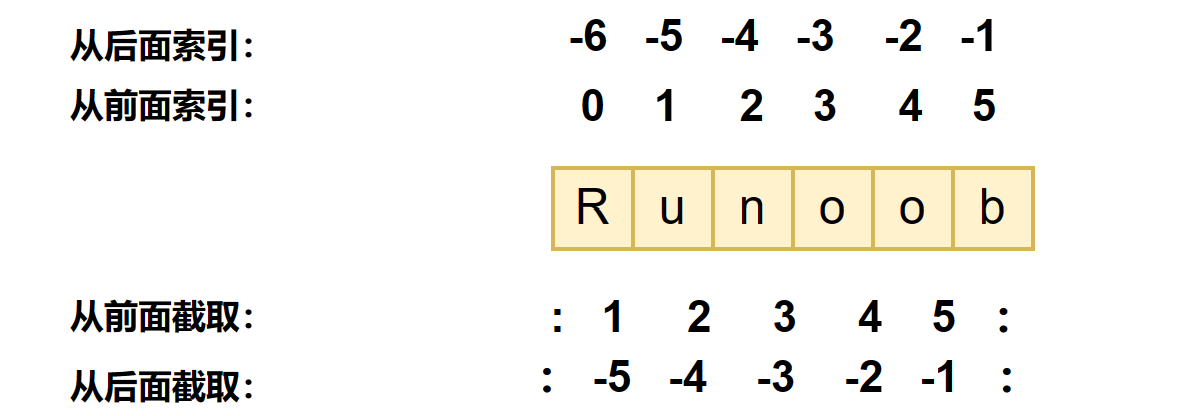
python中访问子字符串,可以使用方括号 []来截取字符串,格式为:变量[头下标:尾下标];索引值索引值以 0 为开始值,**-1** 为从末尾的开始位置
(注意:截取的字符串内容不包括尾下标;切片的规则是始终从左到右进行)
1 | var1 = 'Hello World!' |
也可以截取字符串的一部分并与其他字段拼接
1 | var1 = 'Hello World!' |
转义字符
三引号
python三引号允许一个字符串跨多行,字符串中可以包含换行符、制表符以及其他特殊字符
1 | para_str = """这是一个多行字符串的实例 |
字符串内建函数
好多,具体见下面链接
f-string
f-string 格式化字符串以 f 开头,后面跟着字符串,字符串中的表达式用大括号 {} 包起来,它会将变量或表达式计算后的值替换进去
1 | >>> name = 'Runoob' |
这种方法更简单,不用判断用%s还是,%d。
列表
可以使用 append() 方法来添加列表项
1 | list1 = ['Google', 'Runoob', 'Taobao'] |
可以使用 del 语句来删除列表中的元素
1 | list = ['Google', 'Runoob', 1997, 2000] |
列表脚本操作符
列表对 + 和 * 的操作符与字符串相似。+ 号用于组合列表,* 号用于重复列表
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| len([1, 2, 3]) | 3 | 长度 |
| [1, 2, 3] + [4, 5, 6] | [1, 2, 3, 4, 5, 6] | 组合 |
| [‘Hi!’] * 4 | [‘Hi!’, ‘Hi!’, ‘Hi!’, ‘Hi!’] | 重复 |
| 3 in [1, 2, 3] | True | 元素是否存在于列表中 |
| for x in [1, 2, 3]: print(x, end=” “) | 1 2 3 | 迭代 |
嵌套列表
在列表里面创建其它列表
1 | >>> a = ['a', 'b', 'c'] |
列表函数&方法
| 方法 | 描述 |
|---|---|
| list.append(x) | 把一个元素添加到列表的结尾,相当于 a[len(a):] = [x]。 |
| list.extend(L) | 通过添加指定列表的所有元素来扩充列表,相当于 a[len(a):] = L。 |
| list.insert(i, x) | 在指定位置插入一个元素。第一个参数是准备插入到其前面的那个元素的索引,例如 a.insert(0, x) 会插入到整个列表之前,而 a.insert(len(a), x) 相当于 a.append(x) 。 |
| list.remove(x) | 删除列表中值为 x 的第一个元素。如果没有这样的元素,就会返回一个错误。 |
| list.pop([i]) | 从列表的指定位置移除元素,并将其返回。如果没有指定索引,a.pop()返回最后一个元素。元素随即从列表中被移除。(方法中 i 两边的方括号表示这个参数是可选的,而不是要求你输入一对方括号,你会经常在 Python 库参考手册中遇到这样的标记。) |
| list.clear() | 移除列表中的所有项,等于del a[:]。 |
| list.index(x) | 返回列表中第一个值为 x 的元素的索引。如果没有匹配的元素就会返回一个错误。 |
| list.count(x) | 返回 x 在列表中出现的次数。 |
| list.sort() | 对列表中的元素进行排序。 |
| list.reverse() | 倒排列表中的元素。 |
| list.copy() | 返回列表的浅复制,等于a[:]。 |
把列表当作堆栈使用
列表方法使得列表可以很方便的作为一个堆栈来使用,堆栈作为特定的数据结构,最先进入的元素最后一个被释放(后进先出)。用 append() 方法可以把一个元素添加到堆栈顶。用不指定索引的 pop() 方法可以把一个元素从堆栈顶释放出来
1 | stack = [3, 4, 5] |
元组(tuple)
元组使用小括号 **( )**,列表使用方括号 **[ ]**。
元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可
元组中只包含一个元素时,需要在元素后面添加逗号 ,否则括号会被当作运算符使用
元组中的元素值是不允许修改的,但我们可以对元组进行连接组合,例子如下:
1 | tup1 = (12, 34.56) |
删除元组
元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元组
1 | tup = ('Google', 'Runoob', 1997, 2000) |
内置函数
所谓元组的不可变指的是元组所指向的内存中的内容不可变
1 | >>> tup = ('r', 'u', 'n', 'o', 'o', 'b') |
从以上实例可以看出,重新赋值的元组 tup,绑定到新的对象了,不是修改了原来的对象
字典
字典是另一种可变容器模型,且可存储任意类型对象。
字典的每个键值 key=>value 对用冒号 : 分割,每个对之间用逗号(,)分割,整个字典包括在花括号 {} 中 ,格式如下所示:
1 | d = {key1 : value1, key2 : value2, key3 : value3 } |
键必须是唯一的,但值则不必。
值可以取任何数据类型,但键必须是不可变的,如字符串,数字。
创建空字典
使用 {} 创建空字典
1 | # 使用大括号 {} 来创建空字典 |
也可以使用内建函数 dict() 创建字典:emptydic=dict()
访问字典里面的值
把相对应的键放入方括号中
1 | tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'} |
修改字典
向字典添加新内容的方法是增加新的键值对,修改或删除已有键值对
显式删除一个字典用del命令
1 | tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'} |
注意事项
1.不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住
1 | tinydict = {'Name': 'Runoob', 'Age': 7, 'Name': '小菜鸟'}//后面那个会被记住 |
2.键必须不可变,所以可以用数字,字符串或元组充当,而用列表就不行
遍历技巧
在字典中遍历时,关键字和对应的值可以使用 items() 方法同时解读出来:
1 | knights = {'gallahad': 'the pure', 'robin': 'the brave'} |
序列中遍历时,索引位置和对应值可以使用 enumerate() 函数同时得到:
1 | for i, v in enumerate(['tic', 'tac', 'toe']): |
同时遍历两个或更多的序列,可以使用 zip() 组合:
1 | questions = ['name', 'quest', 'favorite color'] |
要反向遍历一个序列,首先指定这个序列,然后调用 reversed() 函数
要按顺序遍历一个序列,使用 sorted() 函数返回一个已排序的序列,并不修改原值:
1 | basket = ['apple', 'orange', 'apple', 'pear', 'orange', 'banana'] |
集合
集合(set)是一个无序的不重复元素序列
集合中的元素不会重复,并且可以进行交集、并集、差集等常见的集合操作
可以使用大括号 { } 创建集合,元素之间用逗号 , 分隔, 或者也可以使用 set() 函数创建集合
1 | parame = {value01,value02,...}或者set(value) 比如: |
注意:创建一个空集合必须用 set() 而不是 **{ }**,因为 { } 是用来创建一个空字典
1 | >>> basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'} |
添加元素
语法格式:s.add(x) //将元素 x 添加到集合 s 中,如果元素已存在,则不进行任何操作。
另一种方法:s.update(x) //参数可以是列表,元组,字典等例子如下:
1 | thisset.update({1,3})或者 thisset.update([1,4],[5,6]) |
移除元素
语法格式:s.remove(x) //将元素 x 从集合 s 中移除,如果元素不存在,则会发生错误
另一种方法:s.discard(x) //移除集合中的元素,且如果元素不存在,不会发生错误
s.pop():随机删除集合中的一个元素
len(s):计算集合 s 元素个数
s.clear():清空集合 s
x in s:判断元素 x 是否在集合 s 中,存在返回 True,不存在返回 False
[集合内置方法完整列表](Python3 集合 | 菜鸟教程 (runoob.com))
条件控制
语法格式:
1 | if condition_1: |
- 每个条件后面要使用冒号 **:**,表示接下来是满足条件后要执行的语句块。
- 2、使用缩进来划分语句块,相同缩进数的语句在一起组成一个语句块。
- 3、在 Python 中没有 switch…case 语句,但在 Python3.10 版本添加了 match…case,功能也类似
嵌套语句
1 | if 表达式1: |
match…case
1 | match subject: |
case _: 类似于 C 和 Java 中的 **default:**,当其他 case 都无法匹配时,匹配这条,保证永远会匹配成功
循环语句
while循环:注意冒号和缩进
1 | while 判断条件(condition): |
可以通过设置条件表达式永远不为 false 来实现无限循环,可以使用 CTRL+C 来退出当前的无限循环。
无限循环在服务器上客户端的实时请求非常有用。
while循环使用else语句
在while的条件为false的条件下else从句才会执行
1 | while <expr>: |
下面为斐波那契数列的例子:
1 | a, b = 0, 1 |
for循环
for 循环可以遍历任何可迭代对象,如一个列表或者一个字符串;当循环执行完毕后,会执行 else 子句中的代码,如果在循环过程中遇到了 break 语句,则会中断循环,此时不会执行 else 子句。格式如下:
1 | for <variable> in <sequence>: |
可以拿来打印单词里的每一个字符
1 | word = 'runoob' |
range函数
需要遍历数字序列,可以使用内置 range() 函数。它会生成数列:for i in range(5)
可以使用 range() 指定区间的值:for i in range(5,9) :print(i)
也可以使 range() 以指定数字开始并指定不同的增量(甚至可以是负数,有时这也叫做’步长’):for i in range(0, 10, 3) 3为步长
可以使用 range() 函数来创建一个列表:list(range(5))
可以结合 range() 和 len() 函数以遍历一个序列的索引
pass语句
pass是空语句,是为了保持程序结构的完整性。pass 不做任何事情,一般用做占位语句,语法如下:
1 | >>>while True: |
例子:
1 | for letter in 'Runoob': |
推导式
列表推导式
格式如下:
1 | [表达式 for 变量 in 列表] |
- out_exp_res:列表生成元素表达式,可以是有返回值的函数。
- for out_exp in input_list:迭代 input_list 将 out_exp 传入到 out_exp_res 表达式中。
- if condition:条件语句,可以过滤列表中不符合条件的值
1 | names = ['Bob','Tom','alice','Jerry','Wendy','Smith'] |
更复杂一点的例子:
1 | >>> vec1 = [2, 4, 6] |
字典推导式
格式如下:
1 | { key_expr: value_expr for value in collection } |
例子如下:
1 | dict = {x: x**2 for x in (2,4,6)}//三个数字的平方 |
集合推导式
1 | { expression for item in Sequence } |
例子如下:
1 | a = {x for x in 'abkxjbaugxidyskn' if x not in 'abcd'} |
元组推导式(生成器表达式)
元组推导式返回的结果是一个生成器对象
1 | (expression for item in Sequence ) |
例子如下:
1 | >>> a = (x for x in range(1,10)) |
迭代器与生成器
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
迭代器有两个基本的方法:iter() 和 **next()**。迭代器对象可以使用常规for语句进行遍历
字符串,列表或元组对象都可用于创建迭代器
1 | list=[1,2,3,4] |
创造一个迭代器
Python 的构造函数为 init(), 它会在对象初始化的时候执行
把一个类作为一个迭代器使用需要在类中实现两个方法 iter() 与 next()
iter() 方法返回一个特殊的迭代器对象, 这个迭代器对象实现了 next() 方法并通过 StopIteration 异常标识迭代的完成。
next() 方法会返回下一个迭代器对象
1 | class MyNumbers: |
StopIteration 异常用于标识迭代的完成,防止出现无限循环的情况,在 next() 方法中我们可以设置在完成指定循环次数后触发 StopIteration 异常来结束迭代
1 | class MyNumbers: |
生成器
使用了 yield 的函数被称为生成器(generator)。
yield 是一个关键字,用于定义生成器函数,生成器函数是一种特殊的函数,可以在迭代过程中逐步产生值,而不是一次性返回所有结果。
跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
当在生成器函数中使用 yield 语句时,函数的执行将会暂停,并将 yield 后面的表达式作为当前迭代的值返回。
然后,每次调用生成器的 next() 方法或使用 for 循环进行迭代时,函数会从上次暂停的地方继续执行,直到再次遇到 yield 语句。这样,生成器函数可以逐步产生值,而不需要一次性计算并返回所有结果。
调用一个生成器函数,返回的是一个迭代器对象
1 | def countdown(n): |
函数
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号 **()**。
- 任何传入参数和自变量必须放在圆括号中间,圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
- 函数内容以冒号 : 起始,并且缩进。
- return [表达式] 结束函数,选择性地返回一个值给调用方,不带表达式的 return 相当于返回 None。
1 | def 函数名(参数列表): |
python 函数的参数传递:
不可变类型:类似 C++ 的值传递,如整数、字符串、元组。如 fun(a),传递的只是 a 的值,没有影响 a 对象本身。如果在 fun(a) 内部修改 a 的值,则是新生成一个 a 的对象。
1
2
3
4
5
6
7
8def change(a):
print(id(a)) # 指向的是同一个对象
a=10
print(id(a)) # 一个新对象
a=1
print(id(a))
change(a)#地址变了
print(a)#这里的地址还是原来的地址可变类型:类似 C++ 的引用传递,如 列表,字典。如 fun(la),则是将 la 真正的传过去,修改后 fun 外部的 la 也会受影响
python 中一切都是对象,严格意义我们不能说值传递还是引用传递,我们应该说传不可变对象和传可变对象
1 | # 可写函数说明 |
关键字参数和函数调用关系紧密,函数调用使用关键字参数来确定传入的参数值
1 | def printme( str ): |
可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,和上述 2 种参数不同,声明时不会命名。基本语法如下:
1 | def functionname([formal_args,] *var_args_tuple ): |
加了星号 ***** 的参数会以元组(tuple)的形式导入,存放所有未命名的变量参数
1 | def printinfo( arg1, *vartuple ): |
加了两个星号 ** 的参数会以字典的形式导入
1 | def printinfo( arg1, **vardict ): |
如果单独出现星号 *****,则星号 ***** 后的参数必须用关键字传入
lambda(匿名函数)
使用 lambda 来创建匿名函数。
lambda 函数是一种小型、匿名的、内联函数,它可以具有任意数量的参数,但只能有一个表达式。
匿名函数不需要使用 def 关键字定义完整函数。
lambda 函数通常用于编写简单的、单行的函数,通常在需要函数作为参数传递的情况下使用,例如在 map()、filter()、reduce() 等函数中。
lambda 函数特点:
- lambda 函数是匿名的,它们没有函数名称,只能通过赋值给变量或作为参数传递给其他函数来使用。
- lambda 函数通常只包含一行代码,这使得它们适用于编写简单的函数。
lambda 语法格式:
1 | lambda arguments: expression |
lambda是 Python 的关键字,用于定义 lambda 函数。arguments是参数列表,可以包含零个或多个参数,但必须在冒号(:)前指定。expression是一个表达式,用于计算并返回函数的结果。
1 | f = lambda: "Hello World!" |
lambda 函数也可以设置多个参数,参数使用逗号 , 隔开
1 | x = lambda a, b : a * b |
通常与内置函数如 map()、filter() 和 reduce() 一起使用,以便在集合上执行操作
1 | numbers = [1, 2, 3, 4, 5] |
File
读写文件
open将打开一个文件对象:open(filename, mode)如果该文件无法被打开,会抛出 OSError
- filename:包含了你要访问的文件名称的字符串值。
- mode:决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。
| 模式 | 描述 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
文件对象的方法
假设已经创建了一个称为 f 的文件对象,使用下面那些函数都需要先打开一个文件:f = open("/tmp/foo.txt", "r")
f.read()
为了读取一个文件的内容,调用 f.read(size), 这将读取一定数目的数据, 然后作为字符串或字节对象返回。
size 是一个可选的数字类型的参数。 当 size 被忽略了或者为负, 那么该文件的所有内容都将被读取并且返回
f.readline()
会从文件中读取单独的一行。换行符为 ‘\n’。f.readline() 如果返回一个空字符串, 说明已经已经读取到最后一行
f.readlines()
f.readlines() 将返回该文件中包含的所有行。如果设置可选参数 sizehint, 则读取指定长度的字节, 并且将这些字节按行分割
f.write()
f.write(string) 将 string 写入到文件中, 然后返回写入的字符数
1 | f = open("/tmp/foo.txt", "w") |
如果要写入一些不是字符串的东西, 那么将需要先进行转换
1 | f = open("/tmp/foo1.txt", "w") |
f.tell()
f.tell() 用于返回文件当前的读/写位置(即文件指针的位置)。文件指针表示从文件开头开始的字节数偏移量。f.tell() 返回一个整数,表示文件指针的当前位置
f.seek()
如果要改变文件指针当前的位置, 可以使用 f.seek(offset, from_what) 函数。
f.seek(offset, whence) 用于移动文件指针到指定位置。
offset 表示相对于 whence 参数的偏移量,from_what 的值, 如果是 0 表示开头, 如果是 1 表示当前位置, 2 表示文件的结尾,例如:
- seek(x,0) : 从起始位置即文件首行首字符开始移动 x 个字符
- seek(x,1) : 表示从当前位置往后移动x个字符
- seek(-x,2):表示从文件的结尾往前移动x个字符
from_what 值为默认为0,即文件开头
f.close()
在文本文件中 (那些打开文件的模式下没有 b 的), 只会相对于文件起始位置进行定位。
当你处理完一个文件后, 调用 f.close() 来关闭文件并释放系统的资源,如果尝试再调用该文件,则会抛出异常
当处理一个文件对象时, 使用 with 关键字是非常好的方式。在结束后, 它会帮你正确的关闭文件
1 | >>> with open('/tmp/foo.txt', 'r') as f: |
异常处理
try…except
try 语句按照如下方式工作;
- 首先,执行 try 子句(在关键字 try 和关键字 except 之间的语句)。
- 如果没有异常发生,忽略 except 子句,try 子句执行后结束。
- 如果在执行 try 子句的过程中发生了异常,那么 try 子句余下的部分将被忽略。如果异常的类型和 except 之后的名称相符,那么对应的 except 子句将被执行。
- 如果一个异常没有与任何的 except 匹配,那么这个异常将会传递给上层的 try 中。
一个 try 语句可能包含多个except子句,分别来处理不同的特定的异常。最多只有一个分支会被执行。
一个except子句可以同时处理多个异常,会被放在一个括号里成为一个元组:except (RuntimeError, TypeError, NameError)
最后一个except子句可以忽略异常的名称,它将被当作通配符使用 except:
try…except…else
语句还有一个可选的 else 子句,该子句必须放在所有的 except 子句之后。else子句将在 try 子句没有发生任何异常的时候执行
try…finally
无论是否发生异常finally 语句都将执行最后的代码,finally语句在else的后面
抛出异常
使用raise语句:raise [Exception [, args [, traceback]]]
1 | x = 10 |
预定义清理行为
一些对象定义了标准的清理行为,无论系统是否成功的使用了它,一旦不需要它了,那么这个标准的清理行为就会执行
关键词 with 语句就可以保证诸如文件之类的对象在使用完之后一定会正确的执行他的清理方法
1 | with open("myfile.txt") as f: |
以上这段代码执行完毕后,就算在处理过程中出问题了,文件 f 总是会关闭
对象
类有一个名为 init() 的特殊方法(构造方法),该方法在类实例化时会自动调用
类的方法
在类的内部,使用 def 关键字来定义一个方法,与一般函数定义不同,类方法必须包含参数 self, 且为第一个参数,self 代表实例
1 | class people: |
类的继承
单继承
class DerivedClassName(BaseClassName):或者 class DerivedClassName(modname.BaseClassName):
1 | class student(people): |
多继承
1 | 多继承的类定义:class DerivedClassName(Base1, Base2, Base3): |
需要注意圆括号中父类的顺序,若是父类中有相同的方法名,而在子类使用时未指定,python从左至右搜索 即方法在子类中未找到时,从左到右查找父类中是否包含方法
类的私有属性
__private_attrs:两个下划线开头,声明该属性为私有,不能在类的外部被使用或直接访问。在类内部的方法中使用时 self.__private_attrs。
类的私有方法
__private_method:两个下划线开头,声明该方法为私有方法,只能在类的内部调用 ,不能在类的外部调用。self.__private_methods。
命名空间
命名空间提供了在项目中避免名字冲突的一种方法。各个命名空间是独立的,没有任何关系的,所以一个命名空间中不能有重名,但不同的命名空间是可以重名而没有任何影响。
我们举一个计算机系统中的例子,一个文件夹(目录)中可以包含多个文件夹,每个文件夹中不能有相同的文件名,但不同文件夹中的文件可以重名。
一般有三种命名空间:
- 内置名称(built-in names), Python 语言内置的名称,比如函数名 abs、char 和异常名称 BaseException、Exception 等等。
- 全局名称(global names),模块中定义的名称,记录了模块的变量,包括函数、类、其它导入的模块、模块级的变量和常量。
- 局部名称(local names),函数中定义的名称,记录了函数的变量,包括函数的参数和局部定义的变量。(类中定义的也是)
假设我们要使用变量 runoob,则 Python 的查找顺序为:局部的命名空间 -> 全局命名空间 -> 内置命名空间
global 和 nonlocal 关键字
当内部作用域想修改外部作用域的变量时,就要用到 global 和 nonlocal 关键字了
1 | num = 1 |
如果要修改嵌套作用域(enclosing 作用域,外层非全局作用域)中的变量则需要 nonlocal 关键字了
1 | def outer(): |
爬虫
requests模块
基础的知识可以直接上网搜到,这边就不一一列举了
爬取豆瓣电影的排行榜:
1 | #!/usr/bin/env python |
Flask
Hello World
1 | from flask import Flask |
- 引入Flask类
1 | from flask import Flask |
2.创建Flask对象,我们将使用该对象进行应用的配置和运行:
1 | app = Flask(__name__) |
name 是Python中的特殊变量,如果文件作为主程序执行,那么__name__变量的值就是__main__,如果是被其他模块引入,那么__name__的值就是模块名称。
- 编写主程序
在主程序中,执行run()来启动应用:
1 | if __name__ =="__main__": |
改名启动一个本地服务器,默认情况下其地址是localhost:5000,在上面的代码中,我们使用关键字参数port将监听端口修改为8080。
- 路由
使用app变量的route()装饰器来告诉Flask框架URL如何触发我们的视图函数:
1 | @app.route('/') |
上面的标识,访问网站的根路径 ‘/‘ ,将转为对hello_world()函数的调用。
Flask使用Jinja 2模板
先在写代码的目录下面再创一个名为 templates 的文件夹,在其中存放模板文件,以便在应用时使用 Jinja 2 模板引擎渲染动态内容
如果您愿意,您也可以在创建 Flask 应用程序时自定义模板文件夹的名称,具体的做法是在创建应用程序实例时,通过传递 template_folder 参数来指定模板文件夹的路径,例如:
1 | app = Flask(__name__, template_folder='my_templates') |
这样就会将模板文件夹命名为 my_templates,而不是默认的 templates
下面举一个简单的例子:
1 | from flask import Flask, render_template |
,render_template 函数用于渲染名为 index.html 的模板,并且将 greeting 变量传递给模板,以便在模板中使用。
接下来,创建一个名为 index.html 的模板文件:
1 |
|
使用了双花括号 {{ }} 来包含需要在模板中渲染的变量或表达式。在这里,{{ greeting }} 就是在 Flask 视图函数中传递的 greeting 变量的值。
运行这个 Flask 应用程序后,当您访问根路径 / 时,将会显示 ‘Hello, World!’ 字样
再来一个比较复杂的使用了 Jinja 2 模板引擎的语法的html代码:
1 | <html> |
{% if name %}`: 这是一个 Jinja 2 的模板标签,用于开始一个条件语句。它表示如果 `name` 变量存在且不为空,则执行下面的代码块 - `{% else %}`: 这是一个 Jinja 2 的模板标签,用于指定条件语句中的“否则”部分。如果条件不满足(即 `name` 不存在或为空),则执行下面的代码块 - `{% endif %}: 这是一个 Jinja 2 的模板标签,用于结束条件语句的部分
表单(实例)
先来两个模板文件:收集用户资料和显示用户资料的
第一个为收集用户资料的:
1 |
|
第二个为显示用户资料的:
1 |
|
接下来就是python文件,在之前的基础上继续增加的:
1 | from flask import Flask, render_template, request, redirect, url_for |
redirect: 这是 Flask 中的一个重定向函数,用于将用户重定向到指定的 URL 地址。url_for('showbio', username=username, age=age, email=email, hobbies=hobbies): 这是 Flask 中的一个 URL 构建函数,用于构建指定视图函数的 URL 地址。其中,'showbio'是要构建 URL 的视图函数的名称,结果会返回与名为'showbio'的视图函数关联的 URL 地址,并将后面的参数作为查询参数添加到该 URL 中request.args.get()方法来获取 URL 查询字符串中的参数值。具体来说,
request.args是一个字典对象,包含了 URL 查询字符串中的所有参数。而request.args.get()方法则用于从这个字典中获取指定参数的值