引用
安装thinphp8.0
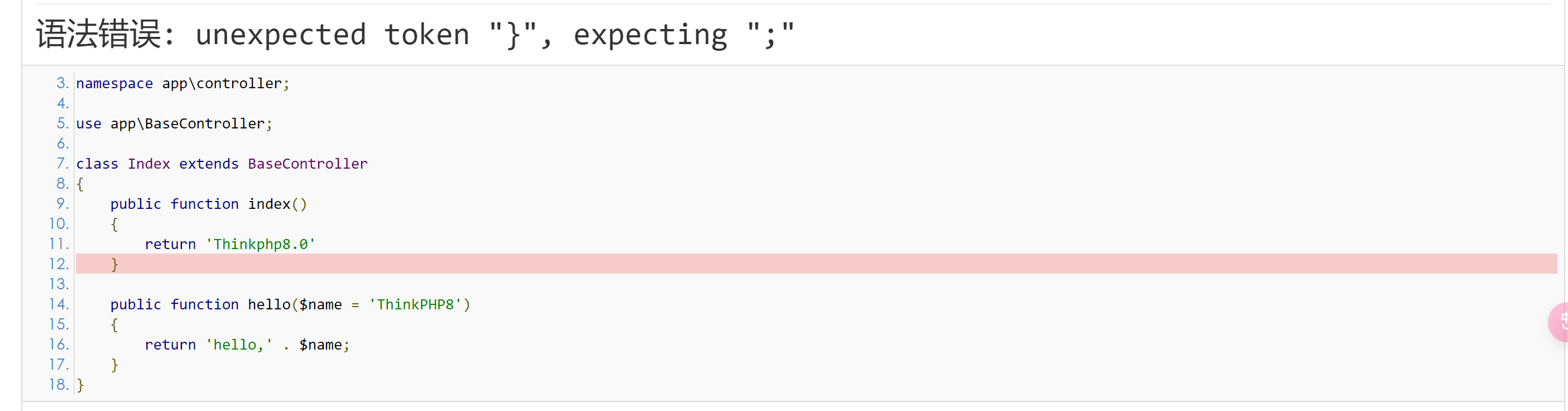
1 | <!--1、访问网址下载安装composer--> |
在第三步创建tk项目时候有报错是正常的,因为有依赖项无法安装的问题(我安装时候的PHP解释器版本是8.2.9),所以需要切换到tk项目目录下执行命令解决依赖项无法安装的问题
基础
目录结构
单应用模式
默认安装后的目录结构就是单应用目录结构
1 | www WEB部署目录(或者子目录) |
多应用模式
详见官方手册
默认应用文件
默认安装后,app目录下会包含下面的文件。
1 | ├─app 应用目录 |
BaseController.php、Request.php 和ExceptionHandle.php三个文件是系统默认提供的基础文件,位置你可以随意移动,但注意要同步调整类的命名空间。如果你不需要使用Request.php 和ExceptionHandle.php文件,或者要调整类名,记得必须同步调整provider.php文件中的容器对象绑定。
配置
- 默认情况下,程序出错会显示:页面出错!请稍候再试~
- 这种情况,一般是应用部署好后,万一出错给用户看的;
- 如果我们自己在开发阶段,需要开启调试模式,来提示具体的错误信息:
- 在根目录有一个文件:.example.env,改成 .env ,也就是去掉点前面;(环境变量文件)
- 然后在配置信息的第一行:APP_DEBUG = true 即可,false则不开启。
开启后会如下所示:
- 调试模式开启后,可以发现右下角会出现trace调试工具小图标:
- 包含了丰富的调试内容:具体自点查看。
架构
HTTP请求流程
对于一个HTTP应用来说,从用户发起请求到响应输出结束,大致的标准请求流程如下:
- 载入
Composer的自动加载autoload文件 - 实例化系统应用基础类
think\App - 获取应用目录等相关路径信息
- 加载全局的服务提供
provider.php文件 - 设置容器实例及应用对象实例,确保当前容器对象唯一
- 从容器中获取
HTTP应用类think\Http - 执行
HTTP应用类的run方法启动一个HTTP应用 - 获取当前请求对象实例(默认为
app\Request继承think\Request)保存到容器 - 执行
think\App类的初始化方法initialize - 加载环境变量文件
.env和全局初始化文件 - 加载全局公共文件、系统助手函数、全局配置文件、全局事件定义和全局服务定义
- 判断应用模式(调试或者部署模式)
- 监听
AppInit事件 - 注册异常处理
- 服务注册
- 启动注册的服务
- 加载全局中间件定义
- 监听
HttpRun事件 - 执行全局中间件
- 执行路由调度(
Route类dispatch方法) - 如果开启路由则检查路由缓存
- 加载路由定义
- 监听
RouteLoaded事件 - 如果开启注解路由则检测注解路由
- 路由检测(中间流程很复杂 略)
- 路由调度对象
think\route\Dispatch初始化 - 设置当前请求的控制器和操作名
- 注册路由中间件
- 绑定数据模型
- 设置路由额外参数
- 执行数据自动验证
- 执行路由调度子类的
exec方法返回响应think\Response对象 - 获取当前请求的控制器对象实例
- 利用反射机制注册控制器中间件
- 执行控制器方法以及前后置中间件
- 执行当前响应对象的
send方法输出 - 执行HTTP应用对象的
end方法善后 - 监听
HttpEnd事件 - 执行中间件的
end回调 - 写入当前请求的日志信息
入口文件
ThinkPHP8.0采用单一入口模式进行项目部署和访问,一个应用都有一个统一(但不一定是唯一)的入口。如果采用自动多应用部署的话,一个入口文件还可以自动对应多个应用。
应用入口文件
默认的应用入口文件位于public/index.php,如果你没有特殊的自定义需求,无需对入口文件做任何的更改。入口文件位置的设计是为了让应用部署更安全,请尽量遵循public目录为唯一的web可访问目录,其他的文件都可以放到非WEB访问目录下面
控制台入口文件
除了应用入口文件外,系统还提供了一个控制台入口文件(即位于项目根目录的think文件)
控制台入口文件用于执行控制台指令,例如:
1 | php think version |
系统内置了一些常用的控制台指令,如果你安装了额外的扩展,也会增加相应的控制台指令,都是通过该入口文件执行的。
多应用模式
详见官方手册
URL访问
单应用URL
1 | http://serverName/index.php/控制器/操作/参数/值… |
注意:这里服务器启动是 php think run 的内置服务器,下节课会探讨外置服务器;
结构分析:
serverName就是我们的:
127.0.0.1:8000;index.php 是入口文件,带上
/;控制器是app\controller\Index.php中的 Index 这个名称,也就是类名;
操作是类里面的方法名,比如:index(默认方法),hello(普通方法);
默认方法可以省略,会直接方法,其他普通方法需要键入方法名:
http://127.0.0.1:8000/index.php/Index(默认执行index操作)http://127.0.0.1:8000/index.php/Index/index(完整路径)http://127.0.0.1:8000/index.php/Index/test(普通方法,必须完整路径)
系统默认自带的hello方法,是针对后续路由的,在路由文件设置过导致无效;
我们在config/app.php中将路由关闭:
"with_route" => false,http://127.0.0.1:8000/index.php/Index/hello(执行默认参数值)http://127.0.0.1:8000/index.php/Index/hello/name/World(修改参数值)
参数不够直观,尤其多参数的时候,也是支持传统方案的:
http://127.0.0.1:8000/index.php/Index/hello?name=World(问号键值对)
URL重写
可以通过URL重写隐藏应用的入口文件index.php(也可以是其它的入口文件,但URL重写通常只能设置一个入口文件),下面是相关服务器的配置参考:
[ Apache ]
httpd.conf配置文件中加载了mod_rewrite.so模块AllowOverride None将None改为All- 把下面的内容保存为
.htaccess文件放到应用入口文件的同级目录下
1 | <IfModule mod_rewrite.c> |
[ Nginx ]
在Nginx低版本中,是不支持PATHINFO的,但是可以通过在Nginx.conf中配置转发规则实现:
1 | location / { // …..省略部分代码 |
其实内部是转发到了ThinkPHP提供的兼容URL,利用这种方式,可以解决其他不支持PATHINFO的WEB服务器环境。
外置服务器,比如phpEnv,省略了入口文件,则出现如下问题:
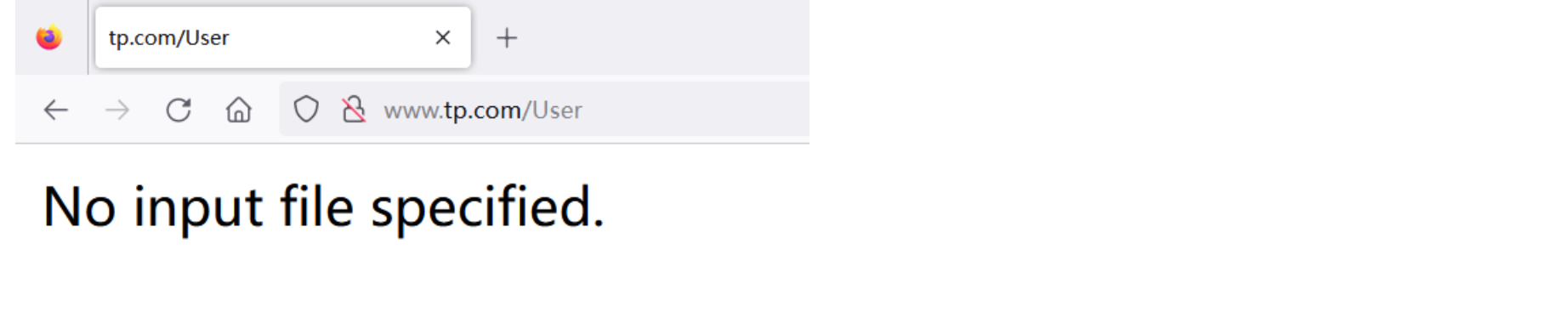
查看手册,根据它URL重写的修改方案(Apache),需要修改.htaccess最后一行:
1 | #RewriteRule ^(.*)$ index.php/$1 [QSA,PT,L] Apache替换成下面一行 |
控制器
定义
控制器:顾名思义MVC中的C,即逻辑控制定义;
默认在app\controller下编写对应的控制器类文件,如果想改默认目录,在/config/route.php中进行修改:
1
2// 访问控制器层名称
"controller_layer" => "controller",类名和文件名大小写保持一致,并采用驼峰式(首字母大写);
1
2
3
4
5
6
7
8
9
10
11
12
13
namespace app\controller;
class User
{
public function index(){
return "用户!";
}
public function login($name = 'city'){
return "登陆成功!".$name;
}
}- User类创建两个方法 index(默认)和 login,访问 URL 如下:
http://127.0.0.1:8000/index.php/user/http://127.0.0.1:8000/index.php/user/loginhttp://127.0.0.1:8000/index.php/User/login?name = Mancity
那么如果创建的是双字母组合,比如 class HelloWorld,访问 URL 如下:
http://127.0.0.1:8000/Index.php/helloworldhttp://127.0.0.1:8000/Index.php/Hello_World1
2
3
4
5
6
7
8
9
10
namespace app\controller;
class HelloWorld
{
public function index(){
return "Hello world!";
}
}
基础和空控制器
基础控制器
一般来说,创建控制器后,推荐继承基础控制器来获得更多的功能方法;
基础控制器仅仅提供了控制器验证功能,并注入了think\App和think\Request;
1
2
3
4
5
6
7
8
9
10
11
12
13namespace app\controller;
use app\BaseController;
class User extends BaseController
{
public function index()
{
// 返回实际路径
return $this->app->getBasePath();
// 返回当前方法名
return $this->request->action();
}
}
空控制器
空控制器一般用于载入不存在的控制器时,进行错误提示;
1
2
3
4
5
6
7class Error
{
public function __call(string $name, array $arguments)
{
return "当前控制器不存在!";
}
}
数据库
创建数据库及表
我这边使用navicat软件配合phpstudy进行创建的,这边我就不详细说明了
连接数据库和查询
连接数据库
我们可以在 config\database.php 配置文件中设置与数据库的连接信息:
如果是一般性数据库连接,在 ‘’connections‘’ 配置区设置即可;
如果是本地测试,它会优先读取 .env 配置,然后再读取 database.php 的配置;
1
2
3
4
5
6
7
8
9
10
11
12# .env文件,部署服务器,请禁用我
APP_DEBUG = true
DB_TYPE = mysql
DB_HOST = 127.0.0.1
DB_NAME = demo
DB_USER = root
DB_PASS = 123456
DB_PORT = 3306
DB_CHARSET = utf8
DEFAULT_LANG = zh-cn如果禁用了 .env 配置,则会读取数据库连接的默认配置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// 数据库连接配置信息
"connections" => [
"mysql" => [
// 数据库类型
"type" => env("DB_TYPE", "mysql"),
// 服务器地址
"hostname" => env("DB_HOST", "127.0.0.1"),
// 数据库名
"database" => env("DB_NAME", "demo"),
// 用户名
"username" => env("DB_USER", "root"),
// 密码
"password" => env("DB_PASS", "123456"),
// 端口
"hostport" => env("DB_PORT", "3306"),
PHP获取数据
我们暂时没有详细学习此类语法,可以简单用一些了解一下即可:
1
2
3
4
5
6
7
8
9
10
11
12
13// 引入Db数据库类
use think\facade\Db;
class User extends BaseController
{
public function get()
{
// 连接user表,查询
$user = Db::table("users")->select();
// 输出数据
return json($user);
}
}
数据查询
table方法
Db类旗下有一个 table 静态调用的方法,参数为完整的表名(前缀都不能省略);
如果希望只查询一条数据,可以使用 find() 方法,需指定 where 条件:
1
2
3// 通过ID查询指定的数据
// find 方法查询结果不存在,返回 null,否则返回结果数组
$user = Db::table("user")->where("id", 1)->find();想要了解执行的原生SQL是什么,可以注释掉 return 直接通过 trace 查看;
使用 findOrEmpty() 方法也可以查询一条数据,但在没有数据时返回一个空数组:
1
2// 没有数据返回空数组
$user = Db::table("user")->where("id", 11)->findOrEmpty();使用 findOrFail() 方法同样可以查询一条数据,在没有数据时抛出一个异常:
1
2// 没有数据抛出异常
$user = Db::table("user")->where("id", 11)->findOrFail();想要获取多列数据,可以使用 select() 方法:
1
2// 查询所有数据
$user = Db::table("user")->select();select() 方法默认返回 Collection 对象的数据集,可以通过 toArray() 方法转换成数组:
1
2
3
4
5
6
7// 用中断函数,来检测返回值
$user = Db::table("user")->select();
halt($user);
// 转换成数组
$user = Db::table("user")->select()->toArray();
halt($user);多列数据也可以参与 where() 方法的筛选:
1
2// 多列筛选
$user = Db::table("user")->where("age", 14)->select();
链式查询
- 我们发现通过指向符号 “->” 多次连续调用方法称为:链式查询;
- 当 Db::table(“user”) 时,返回查询对象(Query),即可连缀数据库对应的方法;
- 当返回查询对象(Query)时,就可以继续调用链式方法,where() 也是链式方法;
- 而 where() 被调用后,依旧返回(Query),可以再次链式调用;
- 在手册 数据库 -> 查询构造器 -> 链式操作 可以了解所有可链式的方法:table、where等;
- 直到遇到 find() 或 select() 返回数组或数据集时,结束查询;
表达式查询
查询表达式支持大部分常用的 SQL 语句,语法格式如下:
1
where("字段名","查询表达式","查询条件");
所有的表达式,查阅手册 -> 查询表达式 中的表格即可;这里列出几个意思一下:
表达式 含义 快捷方式 = 等于 <= time 小于等于某个时间 whereTime EXP SQL表达式查询 whereExp [NOT] LIKE 模糊查询 whereLike [NOT] IN [非] IN 查询 whereIN
查询示例
条件判断类的,id大于4的;
1
2
3// 查询id大于4的数据
$user = Db::name("user")->where("id", ">", 4)->select();
return json($user);Like模糊查询,姓王的;
1
2
3
4// 查询姓王的用户
$user = Db::name("user")->where("name", "like", "王%")->select();
// like快捷方式
$user = Db::name("user")->whereLike("name", "王%")->select();IN区间查询,根据id;
1
2
3
4
5
6
7
8
9// 区间查询,支持not in
$user = Db::name("user")->where("id", "in", "1, 3, 5")->select();
// 语义更好一点
$user = Db::name("user")->where("id", "in", [1,3,5])->select();
// IN快捷查询,两种均可,支持whereNotIn
$user = Db::name("user")->whereIn("id", [1, 2, 3])->select();
// Between,和IN一样 支持 not between
$user = Db::name("user")->where("id", "between", [2,5])->select();
// 快捷方式和IN一样:whereBetween和whereNotBetweenNULL查询;
1
2
3// NULL, null 或 not null:
$user = Db::name("user")->where("details", "not null")->select();
// 快捷方式:whereNull和whereNotNullEXP查询,自定义SQL片段;
1
2
3
4// EXP查询,自定义SQL
$user = Db::name("user")->where("id", "EXP", "<> 8 and id >5")->select();
// 快捷查询
$user = Db::name("user")->whereExp("id","<> 8 and id >5")->select();
表前缀之扩展查询
表前缀
一般来说,为了保持表名统一性和防止冲突,都会给表加上一个前缀,以下划线结束;
比如:tp_user,这里的 tp_ 就是表前缀,所有;
我们修改MySQL中表名,然后刷新程序,报错;
当然,你可以传递 **Db::table(“tp_user”)**,但没必要;
首先,我们可以来配置统一前缀:
在 .env 文件中 添加:
DB_PREFIX = tp_如果部署环境 database.php 中 设置
1
"prefix" => env("DB_PREFIX", "tp_"),
然后,使用 Db::name(“user”) 方法即可:
1
2// 此时,tp_ 表名的前缀可以省略
$user = Db::name("user")->select();
扩展查询
通过 value() 方法,可以查询指定字段的值(单个),没有数据返回 null ;
1
2// value() 方法查询单个列值
$user = Db::name("user")->where("id", 3)->value("name");通过 colunm() 方法,可以查询指定列的值(多个),没有数据返回空数组;
1
2
3
4// colunm() 方法查询多个列值
$user = Db::name("user")->column("name");
// 通过id 作为索引
$user = Db::name("user")->column("name,age", "id");当大量数据需要 批处理 时,比如给所有用户更新数据,就不能一次性全取出来,一批一批的来;
1
2
3
4
5
6
7
8
9
10// 批量处理
Db::name("user")->chunk(2, function ($users) {
foreach ($users as $user) {
dump($user);
}
echo 1;
});
// 通过获取最后的SQL语句,发现用的是LIMIT 2
return Db::getLastSql();另一种处理大量数据:游标查询,为了解决内存开销,每次读取一行,并返回到下一行再读取;
1
2
3
4
5
6
7// 批量处理2
$users = Db::name("user")->cursor();
// PHP生成器
// halt($user);
foreach ($users as $user) {
dump($user);
}
添加数据
单条新增
使用 insert() 方法可以向数据表添加一条数据,更多的字段采用默认;
1
2
3
4
5
6
7
8
9
10
11public function add(){
// 数据
$data = [
"name" => "张麻子",
"age" => 28,
"gender" => "男"
];
// 单条新增,成功返回1
return Db::name("user")->insert($data);
}如果想强行新增抛弃不存在的字段数据,则使用 strick(false) 方法,忽略异常;
1
2
3
4
5
6
7
8
9
10// 数据
$data = [
"name" => "马邦德",
"age" => 30,
"gender" => "男",
"deta" => "我脸上没有麻子!"
];
// 单条新增,成功返回1
return Db::name("user")->strict(false)->insert($data);如果我们采用的数据库是 mysql,可以支持 replace 写入;
insert 和 replace insert 写入的区别,前者表示表中存在主键相同则报错,后者则修改;
1
2// 新增数据时,主键冲突时,直接修改这条记录
Db::name("user")->replace()->insert($data);使用 insertGetId() 方法,可以在新增成功后返回当前数据 ID;
1
2// 返回自增ID
return Db::name("user")->replace()->insertGetId($data);
多条新增
使用 insertAll() 方法,可以批量新增数据,但要保持数组结构一致;
1
2
3
4
5
6
7
8
9
10
11
12
13
14// 数据
$data = [[
"name" => "林克",
"age" => 19,
"gender" => "男",
"details" => "先收集999个呀哈哈!"
],[
"name" => "普尔亚",
"age" => 100,
"gender" => "女",
"details" => "我先来个返老还童,再快速长大!"
]];
return Db::name("user")->insertAll($data);insertAll() 方法 也支持 replace 写入,如果添加数据量大,可以通过 -> limit() 方法限制添加数量;
1
Db::name("user")->replace()->limit(100)->insertAll($data);
更新,删除以及save方法
数据修改
使用 update() 方法来修改数据,修改成功返回影响行数,没有修改返回 0;
1
2
3
4
5
6
7
8// 修改的数据
$data = [
"name" => "王三狗",
"age" => "13",
];
// 执行修改并返回
return Db::name("user")->where("id", 4)->update($data);如果修改数据包含了主键信息,比如 id,那么可以省略掉 where 条件;
1
2
3
4
5
6
7
8
9// 修改的数据
$data = [
"id" => 4,
"name" => "王三狗",
"age" => "13",
];
// 执行修改并返回
return Db::name("user")->update($data);如果想让一些字段修改时执行 SQL 函数操作,可以使用 exp() 方法实现;
1
2// 让details字段内的英文大写
return Db::name("user")->exp("details", "UPPER(details)")->update($data);如果要自增/自减某个字段,可以使用 inc/dec 方法,并支持自定义步长;
1
2
3
4
5
6// 修改时,让age自增和自减,默认1,要去掉$data里面age字段的修改,不然冲突
return Db::name("user")->inc("age")->dec("age", 2)->update($data);
// 派生自字段,延迟执行,毫秒
setInc("age", 1, 600)
setDec("age", 2, 600)使用 Db::raw() 来设置每个字段的特殊需求,灵活且清晰:
1
2
3
4
5
6// 使用Db::raw 更加清晰灵活
Db::name("user")->where("id", 4)->update([
"details" => Db::raw("UPPER(details)"),
"age" => Db::raw("age-2")
]);
return Db::getLastSql();save() 方法是一个通用方法,可以自行判断是新增还是修改(更新)数据;
1
2// 包含主键,即修改;否则,新增
return Db::name("user")->save($data);
数据删除
极简删除可以根据主键直接删除,删除成功返回影响行数,否则 0;
1
2// 根据主键删除
Db::name("user")->delete(8);根据主键,还可以删除多条记录;
1
2// 根据主键删除多条
Db::name("user")->delete([48,49,50]);正常情况下,通过 where()方法来删除;
1
2// 条件删除
Db::name("user")->where("id", 47)->delete();
其他各种查询方式
字符串条件
whereRaw 可以直接写入多条件:
1
2// 多条件字符串
$user = Db::name("user")->whereRaw("age > 15 AND gender="女"")->select();包含变量的多条件查询:
1
2
3
4
5
6
7
8// 变量
$age = 15;
$gender = "女";
// 预处理机制
$user = Db::name("user")->whereRaw("age>:age AND gender=:gender", [
"age" => $age,
"gender" => $gender
])->select();
field()字段筛选
使用 field() 方法,可以指定要查询的字段;
1
2
3// 字段筛选
$user = Db::name("user")->field("id, age, gender")->select();
$user = Db::name("user")->field(["id, age, gender"])->select();使用 field() 方法,给指定的字段设置别名;
1
2
3// 字段别名
$user = Db::name("user")->field("id, gender as sex")->select();
$user = Db::name("user")->field(["id", "gender"=>"sex"])->select();在 fieldRaw() 方法里,可以直接给字段设置 MySQL 函数;
1
2
3
4// 直接SQL函数
$user = Db::name("user")->fieldRaw("id, UPPER(details)")->select();
$user = Db::name("user")->field(true)->select(); // 推荐
return Db::getLastSql();使用 withoutField() 方法中字段排除,可以屏蔽掉想要不显示的字段;
1
2// 排除字段
$user = Db::name("user")->withoutField("details")->select();使用 field() 方法在新增时,验证字段的合法性;
1
2// 排除新增字段
Db::name("user")->field("name,age,gender")->insert($data);
常用链式方法
使用 alias() 方法,给数据库起一个别名;
1
2
3
4
5// 给数据库起个别名
Db::name("user")->alias("a")->select();
return Db::getLastSql();
// 起别名最主要是和另一张表进行关联,这里看手册好了,没表测试
alias("a")->join()使用 limit() 方法,限制获取输出数据的个数;
1
2// 显示前5条
$user = Db::name("user")->limit(5)->select();分页模式,即传递两个参数,比如从第 3 条开始显示 5 条 limit(2,5);
1
2
3
4// 从第2个位置,也就是第3条开始,显示5条
$user = Db::name("user")->limit(2,5)->select();
// 查询第一页数据,1至10条
$user = Db::name("user")->page(1,10)->select();使用 order() 方法,可以指定排序方式,没有指定第二参数,默认 asc;
1
2// 按id倒序排列
$user = Db::name("user")->order("id", "desc")->select();支持数组的方式,对多个字段进行排序;
1
2
3// 按多个字段规则排序
$user = Db::name("user")->order(["age"=>"asc", "id"=>"desc"])->select();
//支持 orderRaw() 方法,可以传入SQL函数,和前面各类Raw一样,不再赘述使用 group() 方法,给性别不同的人进行 age 字段的总和统计;
1
2
3// 统计性别的年龄总和
$user = Db::name("user")->fieldRaw("gender, SUM(age)")
->group("gender")->select();使用 group() 分组之后,再使用 having() 进行筛选;
1
2
3
4// 统计性别的年龄总和,筛选大于100的
$user = Db::name("user")->fieldRaw("gender, SUM(age)")
->group("gender")
->having("SUM(age) > 100")->select();
时间查询
可以使用 >、<、>=、<= 来筛选匹配时间的数据;
1
2
3// 传统时间筛选
$user = Db::name("user")->where("create_time", ">", "2022-1-1")->select();
$user = Db::name("user")->where("create_time", "between", ["2020-1-1", "2023-1-1"])->select();快捷方式 whereTime:
1
2
3
4
5// 使用快捷方式查询
$user = Db::name("user")->whereTime("create_time", ">=", "2022-1-1")->select();
// 默认是 > 可以省略
$user = Db::name("user")->whereTime("create_time", "2022-1-1")->select();区间查询快捷方式 whereBetweenTime:
1
2// 区间查询,包含 whereNotBetweenTime
$user = Db::name("user")->whereBetweenTime("create_time", "2020-1-1", "2023-1-1")->select();使用 whereYear 查询今年的数据、去年的数据和某一年的数据;
1
2
3
4
5
6// 查询今年
$user = Db::name("user")->whereYear("create_time")->select();
// 查询去年
$user = Db::name("user")->whereYear("create_time", "last year")->select();
// 查询某一年
$user = Db::name("user")->whereYear("create_time", "2019")->select();使用 whereMonth 查询当月的数据、上月的数据和某一个月的数据;
1
2
3Db::name("user")->whereMonth("create_time")->select();
Db::name("user")->whereMonth("create_time", "last month")->select();
Db::name("user")->whereMonth("create_time", "2020-6")->select();使用 whereDay 查询今天的数据、昨天的数据和某一个天的数据;
1
2
3Db::name("user")->whereDay("create_time")->select();
Db::name("user")->whereDay("create_time", "last day")->select();
Db::name("user")->whereDay("create_time", "2020-6-27")->select();查询指定时间的数据,比如两小时内的;
1
2// 两小时内的
$user = Db::name("user")->whereTime("create_time", "-2 hours")->select();查询两个时间字段时间有效期的数据,比如活动开始到结束的期间;
比如创建两个字段:start_time,end_time,注册后,分别写入对应时间表明它的有效期;
1
2
3// 直接这么写,不太好理解,看手册的另一种普通写法很容易理解
// 实战中,字段丰富的时候再演示
$user = Db::name("user")->whereBetweenTimeField("start_time", "end_time")->select();
聚合查询
使用 count() 方法,可以求出所查询数据的数量;
1
2// 获取记录数
$user = Db::name("user")->count();count() 可设置指定 id,比如有空值(Null)的 details,不会计算数量;
1
2// 值NULL不计数
$user = Db::name("user")->count("details");使用 max() 方法,求出所查询数据字段的最大值;
1
2// 求最大年龄
$user = Db::name("user")->max("age");如果 max() 方法,求出的值不是数值,则通过第二参数强制转换;
1
2// 如果最大值不是数值,false关闭强制转换
$user = Db::name("user")->max("name", false);使用 min() 方法,求出所查询数据字段的最小值,也可以强制转换;
1
2// 求最小值
$user = Db::name("user")->min("age");使用 avg() 方法,求出所查询数据字段的平均值;
1
2// 求平均值
$user = Db::name("user")->avg("age");使用 sum() 方法,求出所查询数据字段的总和;
1
2// 求总和
$user = Db::name("user")->sum("age");
子查询
使用 fetchSql() 方法,传递参数true时,可以设置不执行 SQL,直接返回SQL语句;
1
2// 子查询语句
$user = Db::name("user")->fetchSql(true)->select();使用 buildSql() 方法,也是返回 SQL 语句,不需要再执行 select(),且有括号;
1
2// 第二种子查询
$subQuery = Db::name("user")->buildSql(true);结合以上方法,我们实现一个子查询;
1
2
3// 子查询样式
$subQuery = Db::name("user")->field("id")->where("age",">", 18)->buildSql();
$user = Db::name("user")->whereExp("id", "IN ".$subQuery)->select();使用闭包的方式执行子查询;
1
2
3
4// 采用闭包构建子查询
$user = Db::name("user")->where("id", "IN", function ($query) {
$query->name("user")->field("id")->where("age",">", 18);
})->select();
原生查询
使用 query() 方法,进行原生 SQL 查询,适用于读取操作,SQL 错误返回 false;
1
2// 原生SQL
$user = Db::query("SELECT * FROM tp_user");使用 execute 方法,进行原生 SQL 更新写入等,SQL 错误返回 false;
1
2// 原生更新写入
$user = Db::execute("update tp_user set details="快快快来救我!" where id=5");
列字段快捷查询
之前用过诸如:whereIn、whereExp、whereLike等等快捷查询;
所有快捷查询列表的手册位置:数据库 -> 查询构造器 -> 高级查询中,找到快捷查询表格;
whereColumn() 方法,比较两个字段的值,符合的就筛选出来;
1
2
3
4// 字段比较,id大于age
$user = Db::name("user")->whereColumn("id", ">", "age")->select();
// 如果是 等于判断 可以简化
->whereColumn("id", "age")whereFieldName() 方法,查询某个字段的值,注意 FileName 是字段名;
1
2
3
4
5// 获取所有性别为:男
$user = Db::name("user")->whereGender("男")->select();
// 获取名字叫王二狗的信息
$user = Db::name("user")->whereName("王二狗")->find();getByFieldName() 方法,查询某个字段的值,注意只能查询一条,不需要 **find()**;
1
2// 单条数据
$user = Db::name("user")->getByName("王二狗");getFieldByFieldName() 方法,通过查询得到某个指定字段的单一值;
1
2// 查询单条并返回单列,找出王二狗的年龄
$user = Db::name("user")->getFieldByName("王二狗", "age");
条件查询
when() 可以通过条件判断,执行闭包里的分支查询;
1
2
3
4
5
6
7
8// 条件判断
$user = Db::name("user")->when(false, function ($query) {
// 满足条件执行这段SQL
$query->where("id", ">", 5);
}, function ($query) {
// 不满足条件执行这段SQL
$query->where("id", "<=", 5);
})->select();
第一个参数 false 是条件,如果该条件为 true,则执行第一个匿名函数,否则执行第二个匿名函数。
事务
数据库的表引擎需要是 InnoDB 才可以使用,如果不是调整即可;
事务处理,需要执行多个 SQL 查询,数据是关联恒定的;
如果成功一条查询,改变了数据,而后一条失败,则前面的数据回滚;
比如:银行取钱,银行ATM扣了1000,但入口被卡住,你没拿到,这时需要事务处理;
系统提供了两种事务处理的方式,第一种是自动处理,出错自动回滚;
1
2
3
4
5// 出现异常回滚
Db::transaction(function () {
Db::name("user")->delete(12);
Db::name("user")->findOrFail(13);
});手动处理,基本和原生处理类似,可以自行输出错误信息;
1
2
3
4
5
6
7
8
9
10
11
12// 启动事务
Db::startTrans();
try {
Db::name("user")->delete(12);
Db::name("user")->findOrFail(13);
//提交事务
Db::commit();
} catch (\Exception $e) {
echo "执行SQL失败!";
// 回滚
Db::rollback();
}
获取器
获取器的意思就是:将数据的字段进行转换处理再进行操作;
比如在获取数据列表的时候,将获取到的详情字段全部大写;
1
2
3
4
5
6
7// 获取器改变字段值
$user = Db::name("user")->withAttr("details", function ($value, $data) {
// NULL 不处理
if ($value != null) {
return strtoupper($value);
}
})->select();withAttr也是支持JSON字段的,具体参考手册 查询构造器 -> 获取器;
高级查询
索引关联
where 方法的数组查询:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27// 性别男,年龄大于15岁,常规做法
$user = Db::name("user")->where("age", ">", 15)
->where("gender", "男")->select();
// 索引数组方式,二维数组,返回的SQL 是一条 AND 并列关系
$user = Db::name("user")->where([
["age", ">", "15"],
["gender","=", "男"]
])->select();
// 如果是等于,可以直接用关联数组,一维
$user = Db::name("user")->where([
"age" => 15,
"gender" => "男"
])->select();
// 两种模式结合起来,
$user = Db::name("user")->where([
["age", ">", "15"],
"gender" => "男"
])->select();
// 搜索条件独立管理,这里=号写全
$map[] = ["age", ">", "15"];
$map[] = ["gender","=", "男"];
$user = Db::name("user")->where($map)->select();
拼装查询
使用 |(OR) 或 &(AND) 来实现 where 条件的高级查询,where 支持多个连缀;
1
2
3
4
5
6
7// or和and 拼装查询
$user = Db::name("user")->where("name|details", "like", "%王%")
->where("id&create_time", ">", 0)
->select();
// 拼装返回的SQL
SELECT * FROM `tp_user` WHERE ( `name` LIKE "%王%" OR `details` LIKE "%王%" ) AND ( `id` > 0 AND `create_time` > "0" )索引数组方式,可以在 where 进行多个字段进行查询;
1
2
3
4
5
6
7
8
9
10// 索引数组拼装
$user = Db::name("user")->where([
["id", ">", "5"],
["gender", "=", "女"],
["age", "<=", 15],
["details", "like", "%我%"]
])->select();
// 拼装返回的SQL
SELECT * FROM `tp_user` WHERE `id` > 5 AND `gender` = "女" AND `age` <= 15 AND `details` LIKE "%我%"条件字符串复杂组装,比如使用 exp 了,就使用 raw() 方法;
1
2
3
4
5
6
7
8// exp 拼装
$user = Db::name("user")->where([
["gender", "=", "男"],
["age", "exp", Db::raw(">=10 AND id<5")]
])->select();
// 拼装返回的SQL
SELECT * FROM `tp_user` WHERE `gender` = "男" AND ( `age` >=10 AND id<5 )如果有多个where,并需要控制优先级,那么可以在需要的部分加上中括号;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20// 下面的代码无法控制优先级
$user = Db::name("user")->where([
["gender", "=", "男"],
["age", "exp", Db::raw(">=10 AND id<5")]
])->where("details", "like", "%我%")->select();
// 外加一个中括号
->where([[
...
]])
// 拼装返回的SQL
SELECT * FROM `tp_user` WHERE ( `gender` = "男" AND ( `age` >=10 AND id<5 ) ) AND `details` LIKE "%我%"
// 推荐用变量代替
$map =[
["gender", "=", "男"],
["age", "exp", Db::raw(">=10 AND id<5")]
];
->where([$map])如果,条件中有多次出现一个字段,并且需要 OR 来左右筛选,可以用 whereOr;
1
2
3
4
5
6
7
8
9
10
11
12
13
14// 多条件重复字段 OR 选项
$map1 = [
["name", "like", "%王%"],
["details", "=", null]
];
$map2 = [
["gender", "=", "女"],
["details", "exp", Db::raw("IS NOT NULL")]
];
$user = Db::name("user")->whereOr([$map1, $map2])->select();
// 拼装返回的SQL
SELECT * FROM `tp_user` WHERE ( `name` LIKE "%王%" AND `details` IS NULL ) OR ( `gender` = "女" AND ( `details` IS NOT NULL ) )
模型
定义
定义模型
为了避免被前面课程中控制器的类名干扰,删除或改名都行:
1
2// UserBak.php,目前不存在任何地方的User.php了
class UserBak extends BaseController定义一个和数据库表相匹配的模型,可在app应用目录下创建model文件夹;
1
2
3
4
5
6
7namespace app\model;
use think\Model;
class User extends Model
{
}模型会自动对应数据表,并且有一套自己的命名规则;
模型类需要去除表前缀(tp_),采用驼峰式命名,并且首字母大写;
1
2tp_user(表名) => User
tp_user_type(表名) => UserType在控制器段创建一个任意名称的类,当然有语义更好,但为了教学理解起名为:TestUser.php;
1
2
3
4
5
6
7
8
9
10
11namespace app\controller;
use app\model\User;
// 注意:类名不限制
class TestUser
{
public function index()
{
return json(User::select());
}
}
模型设置
系统会自动识别 模型类名 对应 表名,User.php 对应 user 表(不含前缀);
但如果你的模型类名不是按照规则对应表名,则需要通过成员字段去设置;
1
2
3
4
5
6
7class Abc extends Model
{
// 设置表名
protected $name = "user";
}
// 使用$table时,指定表时需要完整的表名:tp_user系统也会默认id为你的主键名,如果不是id,则需要设置;
1
2// 设置主键
protected $pk = "uid";模型支持初始化功能,需要设置静态方法,并只在第一次实例化的时候执行,且只执行一次;
1
2
3
4protected static function init()
{
echo "初始化";
}
新增和删除
新增操作
用模型新增数据,首先要实例化模型,开发工具会补全use,非集成工具别忘了;
1
2
3
4use app\model\User;
// 手册new User,这里括号是工具补全的,都可以
$user = new User();使用实例化的方式添加一条数据,并使用 save() 方法进行保存;
注意:使用模型时,会自动给时间字段 create_time,update_time(要有该字段)写入当前时间;
1
2
3
4
5
6
7
8$user = new User();
$user->name = "李白";
$user->age = 28;
$user->gender = "男";
$user->details = "床前明月光,好诗!";
// 成功返回true,失败抛异常,其它看手册
$user->save();也可以通过 save() 传递数据数组的方式,来新增数据;
1
2
3
4
5
6$user->save([
"name" => "杜甫",
"age" => 19,
"gender" => "男",
"details" => "一行白鹭上青天,好诗!"
]);使用 allowField() 方法,允许要写入的字段,其它字段就无法写入了;
1
2
3
4
5
6$user->allowField(["name","age","gender"])->save([
"name" => "蒲松龄",
"age" => 25,
"gender" => "男",
"details" => "十里平湖霜满天,好诗!"
]);模型新增也提供了 replace() 方法来实现 REPLACE into 新增;
1
2
3
4
5
6
7$user->replace()->save([
"id" => 15,
"name" => "蒲松龄",
"age" => 25,
"gender" => "男",
"details" => "十里平湖霜满天,好诗!"
]);当新增成功后,使用 $user->id ,可以获得自增 ID(主键需是 id);
1
return $user->id;
使用 saveAll()方法,可以批量新增数据,返回批量新增的数组;
1
2
3
4
5
6
7
8
9
10
11
12
13return $user->saveAll([
[
"name" => "赵六",
"age" => 19,
"gender"=> "男"
],
[
"name" => "钱七",
"age" => 22,
"gender"=> "男",
"details" => "我很有钱,排行老七!"
]
]);使用 ::create() 静态方法,来创建要新增的数据;
1
2
3
4
5
6
7
8
9
10
11
12$user = User::create([
"name" => "李逍遥",
"age" => 18,
"gender"=> "男",
"details" => "我是一代主角!"
], ["name", "age", "gender", "details"], false);
//参数 1 是新增数据数组,必选
//参数 2 是允许写入的字段,可选
//参数 3 为是否 replace 写入,可选,默认 false 为 Insert 写入
return $user->id;
删除操作
使用 find() 方法,通过主键 (id) 查询到想要删除的数据;
然后再通过 delete()方法,将数据删除,返回布尔值;
1
2
3// 根据主键值,删除数据
$user = User::find(20);
return $user->delete();也可以使用静态方法调用 destroy()方法,通过主键(id)删除数据;
1
2
3
4
5
6// 单条删除
return User::destroy(21);
// 批量删除
return User::destroy([22, 33, 44]);
// 条件删除
return User::where("id", ">", 15)->delete();(返回删除的条目数)destroy() 方法,使用闭包的方式进行删除;
1
2
3
4// 闭包模式
User::destroy(function ($query) {
$query->where("id", ">", 15);
});
更新
数据更新
使用 find()方法获取数据,然后通过 save()方法保存修改,返回布尔值;
1
2
3$user = User::find(19);
$user->details = "我是一代主角!";
return $user->save();通过 where()方法结合 find()方法的查询条件获取的数据,进行修改;
1
2
3$user = User::where("name", "李逍遥")->find();
$user->details = "我想做二代主角!";
return $user->save();save()方法只会更新变化的数据,如果提交的修改数据没有变化,则不更新;
但如果你想强制更新数据,即使数据一样,那么可以使用 force()方法;
1
2// 如何验证被强制了,查看update_time字段是否更新了
$user->force()->save();Db::raw()执行 SQL 函数的方式,同样在这里有效;
1
$user->age = Db::raw("age + 2");
关于验证过滤,后续学习Request再说,手册中 模型 -> 更新 里也有说明:
1
$user->allowField(["name","age"])->save(...)
通过 saveAll()方法,可以批量修改数据,返回被修改的数据集合;
1
2
3
4
5
6$user = new User;
return $user->saveAll([
["id"=>17, "gender"=>"女"],
["id"=>18, "gender"=>"女"],
["id"=>19, "gender"=>"女"],
]);使用静态方法::update()更新,返回的是对象实例;
1
2
3
4
5return User::update(["id"=>17, "gender"=>"男"]);
// ID放在后面,返回数据不含ID
return User::update(["gender"=>"男"], ["id"=>18]);
// 限制更新的内容,只允许gender被修改
return User::update(["gender"=>"男", "name"=>"可笑的人"], ["id"=>19], ["gender"]);
查询
其实和数据库的查询大差不差
模型的查询
模型的绝大部分语法基本都来自于 Db::name() 的查询:
在手册 模型 -> 查询 中可以查阅,这里就演示几个常用的意思一下:
find() 单个 和 select() 多个;
1
2
3$user = User::find(1);
$user = User::select();
$user = User::select([1, 3, 5]);也可以使用 where()方法进行条件筛选查询数据;
1
$user = User::where("id", "<", 5)->select();
1
$user = User::where('name', 'thinkphp')->find();
模型方法也可以使用 where 等连缀查询,和数据库查询方式一样;
1
$user = User::limit(3)->order("id", "desc")->select();
模型支持聚合查询:max、min、sum、count、avg 等;
1
$user = User::count();
模型也支持大量的快捷方式,这里演示一个:
1
$user = User::whereLike("name", "%王%")->select();
模型的字段设置
字段设置
模型的数据字段和表字段是对应关系,默认会自动获取,包括字段的类型;
自动获取会导致增加一次查询,如果在模型中配置字段信息,会减少内存开销;
可以在模型设置$schema 字段,明确定义字段信息,字段需要对应表写完整;
字段类型的定义可以使用PHP类型或者数据库的字段类型都可以,以便自动绑定类型;
1
2
3
4
5
6// 设置字段信息,需要写完整的数据表字段
protected $schema = [
"id" => "int",
"name" => "string",
...
];设置模型字段,只能对模型有效,对于 Db::name() 查询无法作用。
要让模型和Db查询都支持字段类型设置,分三步:
把上面的$schema先注释掉;
在 config/database.php 开启缓存字段;
1
2// 开启字段缓存
"fields_cache" => true,在根目录命令行执行命令:
1
php think optimize:schema
废弃字段
由于历史遗留问题,我们不再想使用某些字段,可以在模型里设置;
设置后,我们在查询和写入时将忽略这些字段;
1
2// 设置废弃字段
protected $disuse = ["age", "details"];
只读字段
只读字段用来保护某些特殊的字段值不被更改,这个字段的值一旦写入,就无法更改;
1
2// 设置只读字段
protected $readonly = ["age", "details"];然后在控制器端进行修改测试:
1
2// 修改查看只读字段
return User::update(["id"=>19, "age"=>22, "name"=>"李逍遥2", "details"=>"可笑"]);
获取器和修改器
获取器
获取器的作用是对模型实例的数据做出自动处理;
一个获取器对应模型的一个特殊方法,该方法为 public;
方法名的命名规范为:getFieldAttr();
举个例子,数据库表示状态 status 字段采用的是数值;
而页面上,我们需要输出 status 字段希望是中文,就可以使用获取器;
在 User 模型端,我创建一个对外的方法,如下:
1
2
3
4
5
6// 获取器,改变字段的值
public function getStatusAttr($value)
{
$status = [-1=>"删除", 0=>"冻结", 1=>"正常", 2=>"待审核"];
return $status[$value];
}控制器端,正常输出数据:
1
2
3
4
5public function attr()
{
$user = User::select();
return json($user);
}如果你定义了获取器,并且想获取原始值,可以使用 getData()方法;
1
2$user = User::find(1);
echo $user->getData("status");使用 withAttr 在控制器端实现动态获取器,比如让年龄+100岁;
1
2
3
4// 可以传入参数二 $data,获得所有数据,方便数据获取和判断
$user = User::select()->withAttr("age", function($value) {
return $value + 100;
});
修改器
模型修改器的作用,就是对模型设置对象的值进行处理;
比如,我们要新增数据的时候,对数据就行格式化、过滤、转换等处理;
模型修改器的命名规则为:setFieldAttr;
我们要设置一个新增,规定输入的年龄都自动+100岁,修改器如下:
1
2
3
4
5// 修改器,写入时改变字段的值
public function setAgeAttr($value)
{
return $value + 100;
}1
2
3
4
5
6return User::create([
"name" => "酒剑仙",
"age" => 58,
"gender"=> "男",
"details" => "我是隐藏主角!"
]);除了新增,会调用修改器,修改更新也会触发修改器;
模型修改器只对模型方法有效,调用数据库的方法是无效的,比如->insert();
搜索器和自动时间戳
搜索器
搜索器是用于封装字段(或搜索标识)的查询表达式,类似查询范围;
一个搜索器对应模型的一个特殊方法,该方法为 public;
方法名的命名规范为:**searchFieldAttr()**;
举个例子,我们要封装一个 name 字段的模糊查询,然后封装一个时间限定查询;
在 User 模型端,我创建两个对外的方法,如下:
1
2
3
4
5
6
7
8
9
10
11// 搜索器,模糊查找姓名
public function searchNameAttr($query, $value, $data)
{
$query->where("name", "like", "%".$value."%");
}
// 搜索器,限定时间
public function searchCreateTimeAttr($query, $value, $data)
{
$query->whereBetweenTime("create_time", $value[0], $value[1]);
}在控制器端,通过 withSearch()方法实现模型搜索器的调用;
1
2
3
4$user = User::withSearch(["name", "create_time"],[
"name" => "李",
"create_time" => ["2023-10-19", "2023-10-20 23:59:59"]
])->select();withSearch()中第一个数组参数,限定搜索器的字段,第二个则是表达式值;
如果想在搜索器查询的基础上再增加查询条件,直接使用链式查询即可;
1
User::withSearch(...)->where("gender", "女")->select();
在获取器和修改器都有一个 $data 参数,它的作用是什么?
1
2
3
4
5
6
7
8
9
10// 搜索器,模糊查找姓名
public function searchNameAttr($query, $value, $data)
{
//$halt($data);
$query->where("name", "like", "%".$value."%");
// 按年龄排序
if (isset($data["sort"])) {
$query->order($data["sort"]);
}
}
自动时间戳
如果你想全局开启,在 database.php 中,设置为 true;
此时,写入操作时,会自动对 create_time 和 update_time 进行写入;
1
"auto_timestamp" => true,
如果你只想设置某一个模型开启,需要设置特有字段;
1
protected $autoWriteTimestamp = true;
自动时间戳只能在模型下有效,数据库方法不可以使用;
如果创建和修改时间戳不是默认定义的,也可以自定义;
1
2protected $createTime = "create_at";
protected $updateTime = "update_at";如果业务中只需要 create_time 而不需要 update_time,可以关闭它;
1
protected $updateTime = false;
也可以动态实现不修改 update_time,具体如下:
1
$user->isAutoWriteTimestamp(false)->save();
软删除和事件
软删除
软删除也称为逻辑删除,只是给数据标记 “已删除” 的状态,不是真实的物理删除;
为何要对数据进行软删除,因为真实的物理删除,删了就没了呀。
在模型端设置软删除的功能,引入 SoftDelete,它是 trait;
1
2
3
4
5
6// 会自动引入SoftDelete
use think\model\concern\SoftDelete;
// 开启软删除,创建delete_time字段,并设置默认为 NULL
use SoftDelete;
protected $deleteTime = "delete_time";delete_time 默认设置的是 null,如果你想更改这个默认值,可以设置:
1
protected $defaultSoftDelete = 0;
由于我们之前演示过字段缓存,会导致无法软删除,你可以删除字段缓存,或者重新更新下:
1
php think optimize:schema
删除分为两种:destroy() 和 delete(),具体如下:
1
2
3
4
5
6
7
8
9
10// 软删除
User::destroy(1);
// 真实删除
User::destroy(1,true);
$user = User::find(1);
// 软删除
$user->delete();
// 真实删除
$user->force()->delete();软删除后,数据库内的数据只是被标记了删除时间,而搜索数据时,会自动屏蔽这些数据;
在开启软删除功能的前提下,使用 withTrashed() 方法取消屏蔽软删除的数据;
1
User::withTrashed()->select();
如果只想查询被软删除的数据,使用 onlyTrashed()方法即可;
1
User::onlyTrashed()->select()
如果想让某一条被软删除的数据恢复到正常数据,可以使用 restore()方法;
1
2$user = User::onlyTrashed()->find(23);
$user->restore();如果要将软删除后的数据库真实的物理删除,需要先将它恢复,再真实删除;
事件
模型事件是指在进行模型的查询和写入操作的时候触发的操作行为。
模型事件只在调用模型的方法生效,使用查询构造器操作是无效的
模型支持如下事件:
| 事件 | 描述 | 事件方法名 |
|---|---|---|
| after_read | 查询后 | onAfterRead |
| before_insert | 新增前 | onBeforeInsert |
| after_insert | 新增后 | onAfterInsert |
| before_update | 更新前 | onBeforeUpdate |
| after_update | 更新后 | onAfterUpdate |
| before_write | 写入前 | onBeforeWrite |
| after_write | 写入后 | onAfterWrite |
| before_delete | 删除前 | onBeforeDelete |
| after_delete | 删除后 | onAfterDelete |
| before_restore | 恢复前 | onBeforeRestore |
| after_restore | 恢复后 | onAfterRestore |
注册的回调方法支持传入一个参数(当前的模型对象实例),但支持依赖注入的方式增加额外参数。
如果
before_write、before_insert、before_update、before_delete事件方法中返回false或者抛出think\exception\ModelEventException异常的话,则不会继续执行后续的操作。
模型事件定义
最简单的方式是在模型类里面定义静态方法来定义模型的相关事件响应。
1 |
|
参数是当前的模型对象实例,支持使用依赖注入传入更多的参数。
写入事件
onBeforeWrite和onAfterWrite事件会在新增操作和更新操作都会触发.
具体的触发顺序:
1 | // 执行 onBeforeWrite |
注意:模型的新增或更新是自动判断的.
关联模型
入门
关联表
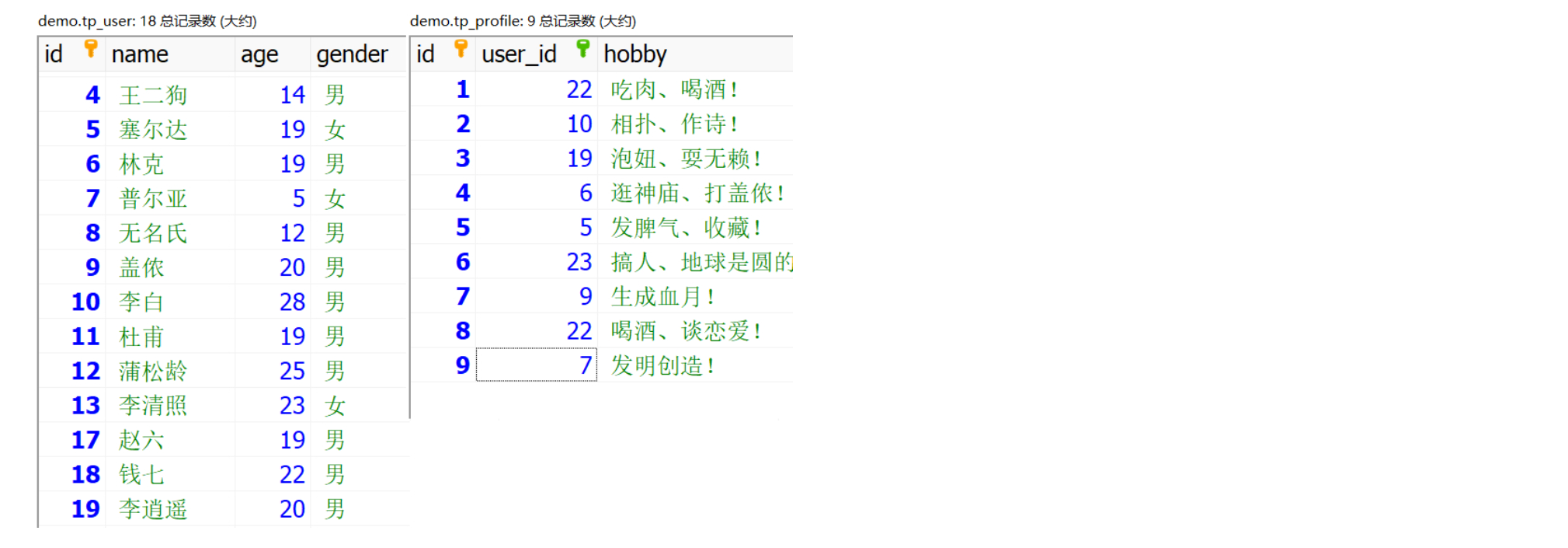
我们已经有了一张 tp_user 表,主键为:id;我们需要一个附属表,来进行关联;
附属表:tp_profile,建立两个字段:user_id 和 hobby,外键是 user_id;
关联查询
关联模型,顾名思义,就是将表与表之间进行关联和对象化,更高效的操作数据;
创建 User 模型和 Profile 模型,均为空模型;如果已有User,改名UserBak备份起来;
1
2
3
4namespace app\model;
use think\Model;
class User extends Model {}1
2
3
4namespace app\model;
use think\Model;
class Profile extends Model {}User 模型端,需要关联 Profile,具体方式如下:
1
2
3
4
5
6
7
8
9class User extends Model {
public function profile()
{
// 一对一关联,
// 参数1:关联的表模型
// 参数2:默认为 user_id (外键)
return $this->hasOne(Profile::class);
}
}创建一个控制器用于测试输出:Link.php;
1
2
3
4
5
6
7public function index()
{
// 主表
$user = User::find(19);
// 访问关联从表
return json($user->profile);
}
一对一关联查询
hasOne 模式
hasOne 模式,适合主表关联附表,具体设置方式如下:
1
2
3
4
5
6
7
8
9
10
11class User extends Model
{
// 定义与Profile模型的一对一关系
public function profile()
{
return $this->hasOne('Profile', 'user_id', 'id');//返回模型实例
}
}
//关联模型(必须):关联的模型名或者类名
//外键:默认的外键规则是当前模型名(不含命名空间,下同)+_id ,例如 user_id
//主键:当前模型主键,默认会自动获取也可以指定传入我们了解了表与表关联后,实现的查询方案:
1
2
3
4// 主表
$user = User::find(19);
// 访问关联从表
return json($user->profile->hobby);使用 save()方法,可以设置关联修改,通过主表修改附表字段的值:
1
2$user = User::find(19);
return $user->profile->save(["hobby"=>"和蛇妖玩耍!"]);->profile 属性方式可以修改数据,->profile()方法方式可以新增数据:
1
2
3
4// 新增附表数据,先找到主表数据
$user = User::find(1);
// 然后通过profile()方法实现新增
return $user->profile()->save(["hobby"=>"不喜欢吃青椒!"]);
belongsTo 模式
belongsTo 模式,适合附表关联主表,具体设置方式如下:
1
2
3
4
5
6
7
8
9// 注意:此时绑定需要Profile模型创建user()方法执行
belongsTo("关联模型",["外键","关联主键"]);
class Profile extends Model {
public function user()
{
return $this->belongsTo(User::class);
}
}查询方式,和主附查询方式一致:
1
2
3
4// 附表
$profile = Profile::find(1);
// 访问关联主表
return $profile->user->name;使用 hasOne()也能模拟 belongsTo() 来进行查询,这样就可以不用在 Profile 模型进行设置:
1
2
3
4
5
6
7
8
9
10
11// hasWhere
// 注意:参数1的profile是方法名,不是模型名
$user = User::hasWhere("profile", ["id"=>2])->find();
return json($user);
// 闭包方式
$user = User::hasWhere("profile", function ($query) {
$query->where("id", 2);
})->find();
return json($user);
一对多关联查询
hasMany 模式
hasMany 模式,适合主表关联附表,实现一对多查询,具体设置方式如下:
1
2
3// 由于是一对多,需要在附表添加多个相同user_id的数据测试
hasMany("关联模型",["外键","主键"]);
return $this->hasMany(Profile::class,"user_id", "id");查询方案和一对一相同:
1
2
3// 主表一对多
$user = User::find(1);
return json($user->profile);使用->profile()方法模式,可以进一步进行数据的筛选;
1
2
3
4
5
6
7// 主表一对多
$user = User::find(1);
// 进一步筛选数据,保留实际顺序的下标
$data = $user->profile->where("id", ">", 10);
// 进一步筛选数据,下标重新从0开始,需要连缀select()
$data = $user->profile()->where("id", ">", 10)->select();
return json($data);使用 has()方法,查询关联附表的主表内容,比如大于等于 2 条的主表记录;
1
2
3// 参数1:profile是方法名
$user = User::has("profile", ">=", 2)->select();
return json($user);使用 hasWhere()方法,查询附表中,可见兴趣的主表记录;
1
2
3// 查询附表profile中visible为1的兴趣关联主表的记录
$user = User::hasWhere("profile", ["visible"=>1])->select();
return json($user);使用 save()和 saveAll()进行关联新增和批量关联新增,方法如下:
1
2
3
4
5
6
7
8
9
10// 主表数据
$user = User::find(24);
// 新增附表关联数据
$user->profile()->save(["hobby"=>"测试喜欢1", "visible"=>1]);
// 批量新增
$user->profile()->saveAll([
["hobby"=>"测试喜欢2", "visible"=>1],
["hobby"=>"测试喜欢3", "visible"=>1],
]);使用 together()方法,可以删除主表内容时,将附表关联的内容全部删除;
1
2
3// 删除主数据,并清空关联附表数据
$user = User::with("profile")->find(29);
$user->together(["profile"])->delete();特别注意:由于外键约束设置问题,默认情况下,关联操作可能会导致1451错误;
解决方案:在 profile 表中 设置外键 删除和修改时 为:CASCADE即可,详细阅读如下:
1
https://blog.csdn.net/qq_23994787/article/details/86063623
模型预载入和统计
预载入
在普通的关联查询下,我们循环数据列表会执行 n+1 次 SQL 查询;
1
2
3
4
5
6
7// 主表三条记录
$list = User::select([10, 11, 12]);
// 遍历附表
foreach ($list as $user)
{
dump($user->profile);
}上面继续采用普通关联查询的构建方式,打开 trace 调试工具,会得到四次查询;
如果采用关联预载入的方式,将会减少到两次,也就是起步一次,循环一次;
1
2
3
4
5$list = User::with(["profile"])->select([10, 11, 12, 17, 18, 19]);
foreach ($list as $user)
{
dump($user->profile);
}1
2
3// 查看显示结构
$list = User::with(["profile"])->select([1, 10, 22]);
return json($list);关联预载入减少了查询次数提高了性能,但是不支持多次调用;
如果你有主表关联了多个附表,都想要进行预载入,可以传入多个模型方法即可;
1
User::with(["profile", "book"])
上面显示结构中,主表和附表的字段已经非常多了,需要对两个表字段进行筛略:
1
2
3
4
5
6
7
8
9
10
11
12// 注意1:withField对应另一个是withoutField
// 注意2:关联字段一定要包含外键:user_id,否则空
$list = User::field("id,age,gender,details")->with(["profile" => function($query) {
$query->withField(["user_id, hobby"]);
}])->select([1, 10, 22]);
return json($list);
// 或者简单些
$list = User::with("profile")->select();
// 直接字段,隐藏主表,加上profile隐藏附表,除了hidden,还有对应的visible方法
return json($list->hidden(["status", "profile.visible"]));还有一些 预载入缓存、延迟预载入,可以参考手册;
关联统计
使用 withCount()方法,可以统计主表关联附表的个数,输出用 profile_count;
1
2
3
4
5
6// 统计这三条数据关联的附表数据的个数
$list = User::withCount(["profile"])->select([1, 10, 22]);
foreach ($list as $user)
{
echo $user->profile_count."<br>";
}关联统计的输出采用“关联方法名” _count,这种结构输出;
不单单支持 Count,还有如下统计方法,均可支持;
**withMax()、withMin()、withSum()、withAvg()**等;
除了 withCount()不需要指定字段,其它均需要指定统计字段;
1
2
3
4
5// 统计附表关联字段的累加和
$list = User::withSum(["profile"], "visible")->select([1, 10, 22]);
foreach ($list as $user) {
echo $user->profile_sum."<br>";
}对于输出的属性,可以自定义:
1
2User::withSum(["profile"=>"p_s"], "visible")
$user->p_s
多对多关联查询
建立三张表
复习一下一对一,一个用户对应一个用户档案资料,是一对一关联;
复习一下一对多,一篇文章对应多个评论,是一对多关联;
多对多怎么理解,分解来看,一个用户对应多个角色,而一个角色对应多个用户;
那么这种对应关系,就是多对多关系,最经典的应用就是权限控制;
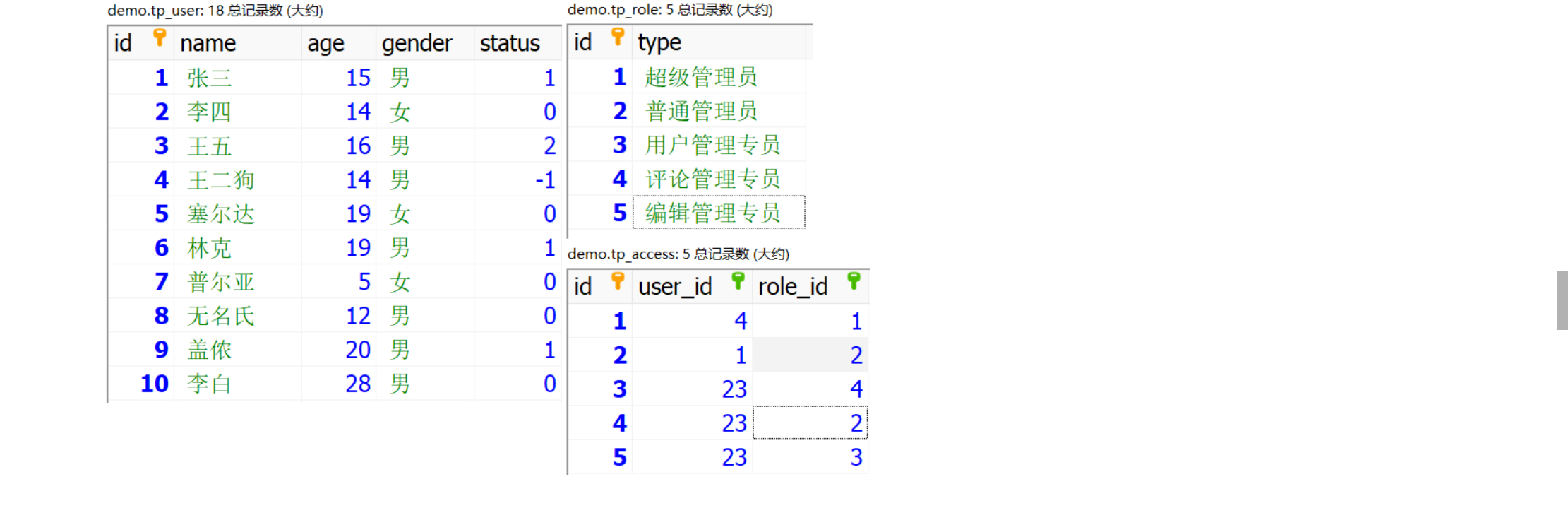
tp_user:用户表;tp_role:角色表;tp_access:中间表;
access 表包含了 user 和 role 表的关联 id,多对多模式;
1
2
3
4
5
6
7class User extends Model {
public function role()
{
// belongsToMany("关联模型","中间表",["外键","关联键"]);
return $this->belongsToMany(Role::class, Access::class);
}
}1
class Role extends Model{}
1
2
3// 这里继承的是Pivot,它本身也继承了Model
// Pivoit是中间表基类,多对多专用模型
class Access extends Pivot{}
权限控制
在控制器段,我们查询一下id为1的用户,并关联查询它的权限:
1
2
3
4
5// 获取一个用户,张三
$user = User::find(1);
// 获取这个用户所有角色
$role = $user->role;
return json($role);当我们要给一个用户创建一个角色时,用到多对多关联新增;
1
2
3
4
5
6// 如果这个角色不存在,则会给角色表增加一条信息
// 并且,会在中间表关联角色和用户
$user->role()->save(["type"=>"测试管理专员"]);
// 也支持批量
$user->role()->saveAll([[...],[...]]);一般来说,上面的这种新增方式,用于初始化角色比较合适;
但是,很多情况下,角色权限是初始化好的,只需要添加中间表,而不是角色表;
那么,我们真正需要就是通过用户表新增到中间表关联即可;
1
2
3
4
5
6
7
8
9
10// 给张三添加一个已经存在的角色,直接传角色ID即可
$user->role()->save(1);
// 或
$user->role()->save(Role::find(1));
$user->role()->saveAll([1,2,3]);
// 或,如果有其它字段,可以通过中括号添加
$user->role()->attach(1);
$user->role()->attach(2, ["details"=>"测试详情"]);除了新增,还有直接删除中间表数据的方法:
1
2
3// 取消掉张三的所有,1,2,6,这里的值是角色的ID,不是中间表ID
$user->role()->detach(1);
$user->role()->detach([2, 6]);
路由
定义
路由入门
路由的作用就是让 URL 地址更加的规范和优雅,或者说更加简洁;
设置路由对 URL 的检测、验证等一系列操作提供了极大的便利性;
路由是默认开启的,如果想要关闭路由,在 config/app.php 配置;
1
2// 是否启用路由
"with_route" => true,路由的配置文件在 config/route.php 中,定义文件在 route/app.php;
我们还回到最初的 Index 控制器,创建一个 details 带 参数的方法;
1
2
3
4public function details($id)
{
return "details ID:".$id;
}1
http://www.tp.com:8000/index/details/id/5
此时,我们在根目录 route 下的 app.php 里配置路由:
1
2
3
4
5
6// 参数1:url/参数
// 参数2:控制器/方法
Route::rule("details/:id", "Index/details");
// 访问地址
http://www.tp.com:8000/details/5rule()方法是默认请求是 any,即任何请求类型均可,第三参数可以限制:
1
2
3Route::rule("details/:id", "Index/xxx", "GET");
Route::rule("details/:id", "Index/xxx", "POST");
Route::rule("details/:id", "Index/xxx", "GET|POST");所有的请求方式均有快捷方式,比如 ::get() 、**::post()** 等,具体查看手册:路由 -> 路由定义;
1
2
3
4// 快捷方式,无须第三参数了
Route::get(...)
Route::post(...)
Route::delete(...)在路由的规则表达式中,有多种地址的配置规则:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// 静态路由
Route::rule("test", "Index/test");
// 带一个参数
Route::rule("details/:id", "Index/details");
// 带两个参数
Route::rule("details/:id/:uid", "Index/details");
// 带可选参数,一般在后面
Route::rule("details/:id/[:uid]", "Index/details");
// 全动态地址,不限定details,url可以是:abc/5/6,后面details也可以动态
Route::rule(":details/:id/:uid", "Index/details");
// 正则规则,完全匹配
Route::rule("details/:id/:uid$", "Index/details");
强制路由
目前来说,路由访问模式和URL访问模式都可以使用,但我们强制路由访问;
开始强制路由,需要在 route.php 里面进行配置:
1
2// 是否强制使用路由
"url_route_must" => true,1
2// 首页也必须设置路由
Route::rule("/", "Index/index");
完全匹配
规则匹配检测的时候默认只是对URL从头开始匹配,只要URL地址开头包含了定义的路由规则就会匹配成功,如果希望URL进行完全匹配,可以在路由表达式最后使用$符号,例如:
1 | Route::get('new/:cate$', 'News/category'); |
这样定义后
1 | http://serverName/index.php/new/info |
会匹配成功,而
1 | http://serverName/index.php/new/info/2 |
则不会匹配成功。
如果是采用
1 | Route::get('new/:cate', 'News/category'); |
方式定义的话,则两种方式的URL访问都可以匹配成功。
如果需要全局进行URL完全匹配,可以在路由配置文件中设置
1 | // 开启路由完全匹配 |
开启全局完全匹配后,如果需要对某个路由关闭完全匹配,可以使用
1 | Route::get('new/:cate', 'News/category')->completeMatch(false); |
路由闭包和变量规则
闭包
闭包支持我们可以通过 URL 直接执行,而不需要通过控制器和方法;
1
2
3
4// 闭包
Route::get("think", function () {
return "hello, ThinkPHP8!";
});闭包支持也可以传递参数和动态规则:
1
2
3
4// 带参数闭包,如果不带:version,那么地址:php?version=8
Route::get("php/:version", function ($version) {
return "PHP".$version;
});
变量规则
系统默认的路由变量规则为\w+,即字母、数字、中文和下划线;
如果你想更改默认的匹配规则,可以修改 config/route.php 配置;
1
2// 默认的路由变量规则
"default_route_pattern" => "[\w\.]+",如果我们需要对于具体的变量进行单独的规则设置,则需要通过 pattern() 方法;
将 details 方法里的 id 传值,严格限制必须只能是数字\d+;
1
2
3
4
5
6
7
8
9// 正则规则 \d+ 限定id为数字
Route::rule("details/:id", "Index/details")
->pattern(["id"=>"\d+"]);
// 多个参数
->pattern([
"id" => "\d+",
"uid" => "\d+"
]);如果让指定的参数统一限定为数字,比如id和uid,也就是全局设置,在app.php顶部设置:
1
2
3
4Route::pattern([
"id" => "\d+",
"uid" => "\d+"
]);不喜欢斜杠怎么办?能换成减号吗?可以的:
1
2
3
4
5// 支持替换斜杠
Route::rule("details-:id", "Index/details");
// 支持组合变量<id>方式
Route::rule("details-<id>", "Index/details");
路由参数.域名.MISS
参数
设置路由的时候,可以设置相关方法进行,从而实施匹配检测和行为执行;
ext 方法作用是检测 URL 后缀,比如:我们强制所有 URL 后缀为.html;
1
2Route::rule("test", "Index/test")->ext("html");
Route::rule("test", "Index/test")->ext("html|shtml");https 方法作用是检测是否为 https 请求,结合 ext 强制 html 如下:
1
Route::rule("test", "Index/test")->ext("html")->https();
如果想让全局统一配置 URL 后缀的话,可以在 config/route.php 中设置;
具体值可以是单个或多个后缀,也可以是空字符串(任意后缀),false 禁止后缀;
1
2// URL伪静态后缀
"url_html_suffix" => "html",denyExt 方法作用是禁止某些后缀的使用,使用后直接报错;
1
2// 可以将url_html_suffix 设置为空测试
Route::rule("test", "Index/test")->denyExt("jpg|gif|png");domain 方法作用是检测当前的域名是否匹配,完整域名和子域名均可;
1
2
3Route::rule("test", "Index/test")->domain("localhost");
Route::rule("test", "Index/test")->domain("new.tp.com");
Route::rule("test", "Index/test")->domain("new");还有ajax/pjax/json检测、filter 额外参数检测、append追加额外参数、option统一管理检测,可参考手册;
1
2
3
4
5Route::rule("test", "Index/test")->option([
"ext" => "html",
"https" => false,
"domain" => "www.tp.com"
]);
域名
如果想限定的某个域名下生效的路由,比如 news.tp.com 可以通过域名闭包方式:
1
2
3
4
5
6
7Route::domain("news.tp.com", function () {
Route::rule("details/:id", "Index/details");
});
// 或
Route::domain("news", function () {
Route::rule("details/:id", "Index/details");
});路由域名也支持:ext、pattern、append 等路由参数方法的操作;
MISS
全局 MISS,类似开启强制路由功能,匹配不到相应规则时自动跳转到 MISS;
1
2
3
4
5
6Route::miss("Error/miss");
// 闭包模式
Route::miss(function () {
return "MISS 404";
});
路由分组.URL生成
分组
路由分组,即将相同前缀的路由合并分组,这样可以简化路由定义,提高匹配效率;
使用 group()方法,来进行分组路由的注册;
1
2
3
4
5
6
7Route::group("index", function () {
Route::rule(":id", "Index/details");
Route::rule(":name", "Index/hello");
})->ext("html")->pattern(["id"=>"\d+"]);
// URL1: http://www.tp.com:8000/index/5.html
// URL2: http://www.tp.com:8000/index/world.html也可以省去第一参数,让分组路由更灵活一些;
1
2
3
4
5
6
7Route::group(function() {
Route::rule("test", "Index/test");
Route::rule("h/:name", "Index/hello");
})->ext("html");
// URL1: http://www.tp.com:8000/test.html
// URL2: http://www.tp.com:8000/h/world.html使用 prefix()方法,可以省略掉分组地址里的控制器;
1
2
3
4
5
6
7Route::group("index", function () {
Route::rule("test", "test");
Route::rule(":name", "hello");
})->prefix("Index/")->ext("html");
// URL1: http://www.tp.com:8000/index/test.html
// URL2: http://www.tp.com:8000/index/world.html
URL生成
使用 url() 助手函数来生成定义好的路由地址,放在在控制器使用;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// 静态不带参数的
Route::rule("test", "Index/test")->ext("html");
// 控制器段获取url:/test.html
return url("Index/test");
// 动态带参数的
Route::rule("details/:id", "Index/details")->ext("html");
// 控制器段获取url:/details/5.html
return url("Index/details", ["id"=>5]);
// url参数一和路由的rule的参数二是一致的,可以通过name方法复刻;
Route::rule("details/:id", "Index/details")->name("de")->ext("html");
// 控制器段获取url:/details/5.html
return url("de", ["id"=>5]);
// 完整带域名的地址:http://www.tp.com:8000/details/5.html
return url("de", ["id"=>5])->domain(true);
return url("de", ["id"=>5])->domain("www.tp.com");在手册 -> 路由 -> URL 生成 有 Route::buildUrl() 源方法,只不过助手函数,更方便;
资源路由
创建资源
资源路由,采用固定的常用方法来实现简化 URL 的功能;
1
Route::resource("blog", "Blog");
系统提供了一个命令,方便开发者快速生成一个资源控制器;
1
php think make:controller Blog
以上的两部操作,创建了一个控制器Blog类,并生成了增删改查操作的方法,而且还实现了全部路由:
标识 请求类型 路由规则 操作方法 index GET blog index create GET blog/create create save POST blog save read GET blog/:id read edit GET blog/:id/edit edit update PUT blog/:id update delete DELETE blog/:id delete
地址URL
资源路由注册好后,所有地址都是全自动生成,具体如下:
1
2
3
4http://www.tp.com:8000/blog //GET 访问的是index方法,用于显示数据
http://www.tp.com:8000/blog/create //GET 访问的是create方法,新增数据的表单页面
http://www.tp.com:8000/blog/5 //GET 访问的是read方法,读取指定id的一条数据
http://www.tp.com:8000/blog/5/edit //GET 访问的是edit方法,读取指定id数据并显示修改表单1
2
3http://www.tp.com:8000/blog //POST 访问的是save方法,用于接收表单提交的新增数据
http://www.tp.com:8000/blog/5 //PUT 访问的是update方法,用于接收表单提交的修改数据
http://www.tp.com:8000/blog/5 //DELETE 访问的是delete方法,用于接收数据删除信息默认的参数采用 id 名称,如果你想别的,比如:blog_id;
1
2//相应的 delete($blog_id)
...->vars(["blog"=>"blog_id"]);也可以通过 only() 方法限定系统提供的资源方法:
1
2// 只允许指定的这些操作
...->only(["index","save","create"]);还可以通过 except() 方法排除系统提供的资源方法:
1
2// only相反操作
...->except(["read","delete","update"])使用 rest() 方法,更改系统给予的默认方法,1.请求方式;2.地址;3.操作;
1
2
3
4
5
6
7Route::rest("create", ["GET", "/add", "add"]);
// 批量
Route::rest([
"save" => ["POST", "", "store"],
"update" => ["PUT", "/:id", "save"],
"delete" => ["DELETE", "/:id", "destory"],
]);支持嵌套资源路由,类似于一对多关联的感觉,实战中用到再操作,详情查看手册:
视图.变量,渲染
视图操作
首先,为了方便后续课程学习,先把路由给关闭了;并创建一个用于测试视图的控制器:
1
2
3
4
5
6
7
8
9
10
11// 是否启用路由
"with_route" => false,
// 视图控制器
class ViewPage extends BaseController
{
public function index()
{
return "view";
}
}由于我们不用模板引擎,直接使用php原生,就需要使用 engine() 方法,载入 test 模板;
1
2
3
4
5
6// 载入原生php模板
return View::engine("php")->fetch("test");
// 模板地址为:view/view_page/test.html
// 或修改配置文件,将Think改为php就可以使用助手函数
return view("test");如果希望模板后缀为 .php,方便 php + html5 混编,在 config/view 设置:
1
2// 模板后缀
"view_suffix" => "php",在 fetch() 方法的第二参数,通过数组方式给模板传递变量:
1
2
3
4
5
6
7
8
9return View::engine("php")->fetch("test", [
"name" => "ThinkPHP8"
]);
// 或
return view("test",[
"name" => "ThinkPHP8"
]);
表单提交
先载入一个表单页面:
1
return View::engine("php")->fetch("input");
创建一个表单:
1
2
3
4<form action="/view_page/save" method="post">
<input type="text" name="username">
<input type="submit" value="提交"></input>
</form>接受数据:
1
2
3
4public function save()
{
return $this->request->post("username");
}
请求对象.变量.信息
请求对象
上一节课中表单提交时,我们接受数据使用了 $this->request->post() 方法,这哪里来的?
因为我们的控制器继承了 BaseController 追踪进去,可以看到 $request 成员字段;
关于这个知识点的源知识点,可以参考:手册 -> 架构 -> 容器和依赖注入,TP6讲过,8不讲了;
在没有继承 BaseController 时,我们需要自己手动注入请求:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20namespace app\controller;
use think\Request;
class Rely
{
protected $request;
// 依赖注入
public function __construct(Request $request)
{
$this->request = $request;
}
public function index()
{
halt($this->request->get());
}
}
// 上面的请求方式比较原始,过于麻烦,不推荐了第二种方式:门面Facade,它相关的知识点在手册 -> 架构 -> 门面:
1
2
3
4
5
6
7
8
9
10namespace app\controller;
use think\facade\Request;
class Rely
{
public function index()
{
halt(Request::get());
}
}第三种方式:继承 BaseController,其实就是第一种,只不过被封装到基类中去了:
1
2
3
4
5
6
7
8
9
10namespace app\controller;
use app\BaseController;
class Rely extends BaseController
{
public function index()
{
halt($this->request->get());
}
}第四种方式:终极方法 request() 助手函数:
1
halt(request()->get());
请求信息
在手册 请求 -> 请求信息 里有全部的请求方法模块,这里列举几个意思一下:
方法 含义 host 当前访问域名或者IP port 当前访问的端口 url 当前完整URL root URL访问根地址 method 当前请求类型 我们三种方法演示一遍,最终选一种你喜欢的即可:
1
2
3
4
5
6
7
8
9// 当前url
echo $this->request->url();
echo Request::url();
echo request()->url();
// 请求方法
echo request()->method();
// 更多的对照手册自行测试即可
请求变量
Request 对象支持全局变量的检测、获取和安全过滤,支持$_GET、$_POST…等;
使用 has() 方法,可以检测全局变量是否已经设置:
1
2// 判断是否有GET模式下id的值
echo request()->has("id", "get");更多方法,参看手册 请求 -> 输入变量, 这里意思几个:
方法 描述 param 获取当前请求变量 get 获取 $_GET 变量 post 获取 $_POST 变量 put 获取 PUT 变量 delete 获取 DELETE 变量 session 获取 SESSION 变量 param() 方法是框架推荐的方法,可以自动识别诸如 get、post等数据信息;
1
2
3
4
5
6
7
8// url: http://www.tp.com:8000/rely/index?id=5
// 可以获取 get 模式 id 的值
echo request()->param("id");
echo request()->get("id");
// url: http://www.tp.com:8000/rely/index/id/5
// 此时,只能是param获取
echo request()->param("id");1
2
3
4// 默认值
request()->param("name") // null,实际上页面也转行成空,判断null也成立
request()->param("name", "") // 空字符串
request()->param("name", "无名氏"); // 无名氏可在 app\Request.php 配置过滤器:
1
2
3
4
5
6
7
8
9
10
11
12
13
14http://www.tp.com:8000/rely/index?name=我<b>你</b>
// 将特殊字符转换HTML实体
protected $filter = ["htmlspecialchars"];
// 如果不想要全局过滤器,可以直接局部
request()->param("name", "", "htmlspecialchars");
// 设置了全局过滤器,但某个不想用
request()->param("name", "", null)
// 使用变量修饰符,可以将参数强制转换成指定的类型;
// /s(字符串)、/d(整型)、/b(布尔)、/a(数组)、/f(浮点);
request()->param("id/d");only()、except() 设置允许和排查可接受的变量:
1
2
3
4
5
6// 允许id和name变量
request()->only(["id","name"]);
// 默认值设置
request()->only(["id"=>1,"name"=>"默认值"]);
// 参数二可设置GET还是POST等
request()->only(["id","name"], "GET");以上所有,都封装到助手函数 input() 里了:
1
2
3
4
5
6input("?get.id"); //判断 get 下的 id 是否存在
input("?post.name"); //判断 post 下的 name 是否存在
input("param.name"); //获取 param 下的 name 值
input("param.name", "默认值"); //默认值
input("param.name", "", "htmlspecialchars"); //过滤器
input("param.id/d"); //设置强制转换
请求类型.输出.重定向
请求类型
Request 对象提供了一个方法 method() 来获取当前请求类型,也提供了判断当前的请求类型:
方法 说明 method 获取当前请求类型 isGet 判断是否GET请求 isPost 判断是否POST请求 isPut 判断是否PUT请求 isDelete 判断是否DELETE请求 isAjax 判断是否AJAX请求 使用请求类型伪装,可以提交 PUT、DELETE 类型:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19// 载入表单模板
public function create()
{
return View::engine("php")->fetch("create");
}
// 表单
<form action="/rely" method="post">
<input type="text" name="name">
<input type="hidden" name="_method" value="PUT">
<input type="submit" value="提交">
</form>
// 判断是否PUT请求
if (request()->isPut()) {
echo input("put.name");
}
// 直接ajax、pjax伪装,在url后续添加?_ajax=1即可,结合前段时再研究
响应输出
响应输出,有好几种:包括 return、json() 和 view() 等等;
默认输出方式是以 html 格式输出,如果你发起 json 请求,则输出 json;
而背后是 response 对象,可以用 response() 输出达到相同的效果;
1
2
3$data = "Hello,TP8!";
// 等同于 return $data;
return response($data);response()方法可以设置第二参数,状态码,或调用 code()方法;
1
2
3
4
5// 参数二,发送状态码
return response($data, 201);
//或
return response($data)->code(201);
// json()和view()均支持状态码
重定向
使用 redirect()方法可以实现页面重定向,需要 return 执行;
1
2
3
4
5
6// 首页
return redirect("/");
// 访问路由页面,外加状态码
return redirect("details/5", 303);
// 访问url生成的地址
return redirect(url("Index/index"));还支持session跳转和记住上一次地址的跳转,实战时再研究;
中间件
定义
定义中间件
中间件的主要用于拦截和过滤 HTTP 请求,并进行相应处理;
这些请求的功能可以是 URL 重定向、权限验证等等;
为了进一步了解中间件的用法,我们首先定义一个基础的中间件;
可以通过命令行模式,在应用目录下生成一个中间件文件和文件夹;
1
php think make:middleware Check
1
2
3
4
5
6
7
8
9
10public function handle($request, \Closure $next)
{
// 拦截请求
if ($request->param("name") == "index")
{
return redirect("../../../../");
}
// 继续往执行
return $next($request);
}然后将这个中间件进行注册,在应用目录下的middleware.php文件中配置;
1
2// 注册中间件
app\middleware\Check::class中间件的入口执行方法必须是:handle()方法,第一参数请求,第二参数是闭包;
业务代码判断请求的 name 如果等于 index,就拦截住,执行中间件,跳转到首页;
但如果请求的 name 是 lee,那需要继续往下执行才行,不能被拦死;
那么就需要$next($request)把这个请求去调用回调函数;
中间件 handle()方法规定需要返回 response 对象,才能正常使用;
而$next($request)执行后,就是返回的 response 对象;
为了测试拦截后,无法继续执行,可以 return response()助手函数测试;
前后置中间件
将$next($request)放在方法底部的方式,属于前置中间件;
前置中间件就是请求阶段来进行拦截验证,比如登录判断、跳转、权限等;
而后置中间件就是请求完毕之后再进行验证,比如写入日志等等;
1
2
3
4
5public function handle($request, \Closure $next)
{
//中间件代码,前置
return $next($request);
}1
2
3
4
5
6public function handle($request, \Closure $next)
{
$response = $next($request);
//中间件代码,后置
return $response;
}1
2
3
4
5
6
7
8// 先执行内容,再执行中间件
$response = $next($request);
// 拦截请求
if ($request->param("name") == "index")
{
return redirect("../../../../");
}
return $response;
中间件操作
路由中间件
创建一个给路由使用的中间件,判断路由的 ID 值实现相应的验证;
1
php think make:middleware Auth
路由方法提供了一个 middleware() 方法,让指定的路由采用指定的中间件;
1
2// 限定这个路由采用了中间件
Route::rule('/', 'Index/index')->middleware(\app\middleware\Auth::class);1
2
3
4
5
6// 导入后,可以省略
use app\middleware\Auth;
use app\middleware\Check;
// 路由采用多个中间件
Route::rule('/', 'Index/index')->middleware([Auth::class, Check::class]);也可以在 config/middleware.php 配置文件加中,配置别名支持;
1
2
3
4
5// 别名或分组
'alias' => [
"Auth" => \app\middleware\Auth::class,
"Check" => \app\middleware\Check::class,
],1
2// 当然,Route::group() 路由分组也支持
Route::rule('/', 'Index/index')->middleware(["Auth", "Check"]);
2. 控制器中间件
如果不用路由,怎么用局部化的中间件呢?当然也可以直接在控制器上定义;
1
2// 这里是别名方式,和路由一样,另外两种均支持
protected $middleware = ["Auth", "Check"];默认是控制器全体方法有效,如果需要限制,还是 only 和 except;
1
2
3
4protected $middleware = [
"Auth" => ["only" => ["hello"]],
"Check" => ["only" => ["index"]]
];