参考
shiro流程分析
环境搭建
该篇文字主要讲解的是流程,所以基础的环境搭建可见:https://drun1baby.top/2022/07/07/Java%E5%BC%80%E5%8F%91%E4%B9%8Bshiro%E5%AD%A6%E4%B9%A0
下面是我的demo结构

比较关键的shiroConfig.java
1 | package org.example.shiro_demo.controller; |
以及UserRealm.java
1 | package org.example.shiro_demo.controller; |
shiro认证流程分析
初始化
ShiroFilterFactoryBean 类实现了 FactoryBean 接口,那么 Spring 在初始化的时候必然会调用 ShiroFilterFactoryBean.getObject() 方法获取实例,实例是哪一个,就是在ShiroConfig中的getShiroFilterFactoryBean方法返回的bean实例
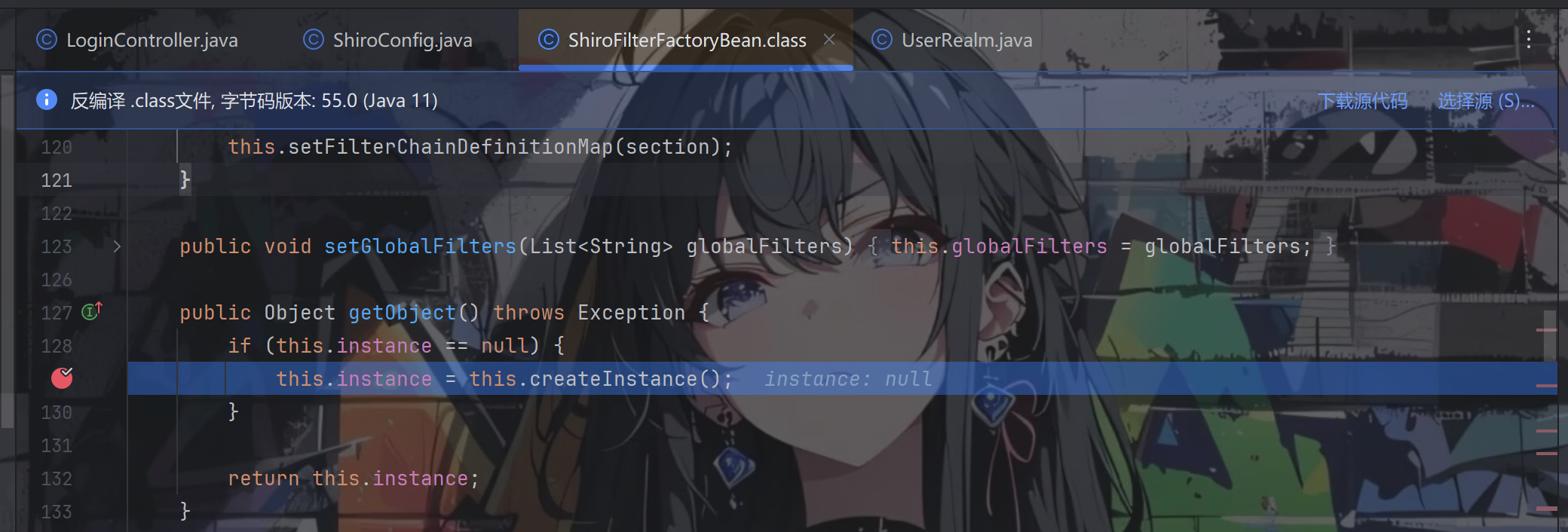
在 getObject() 方法中会调用 createInstance() 方法,跟进
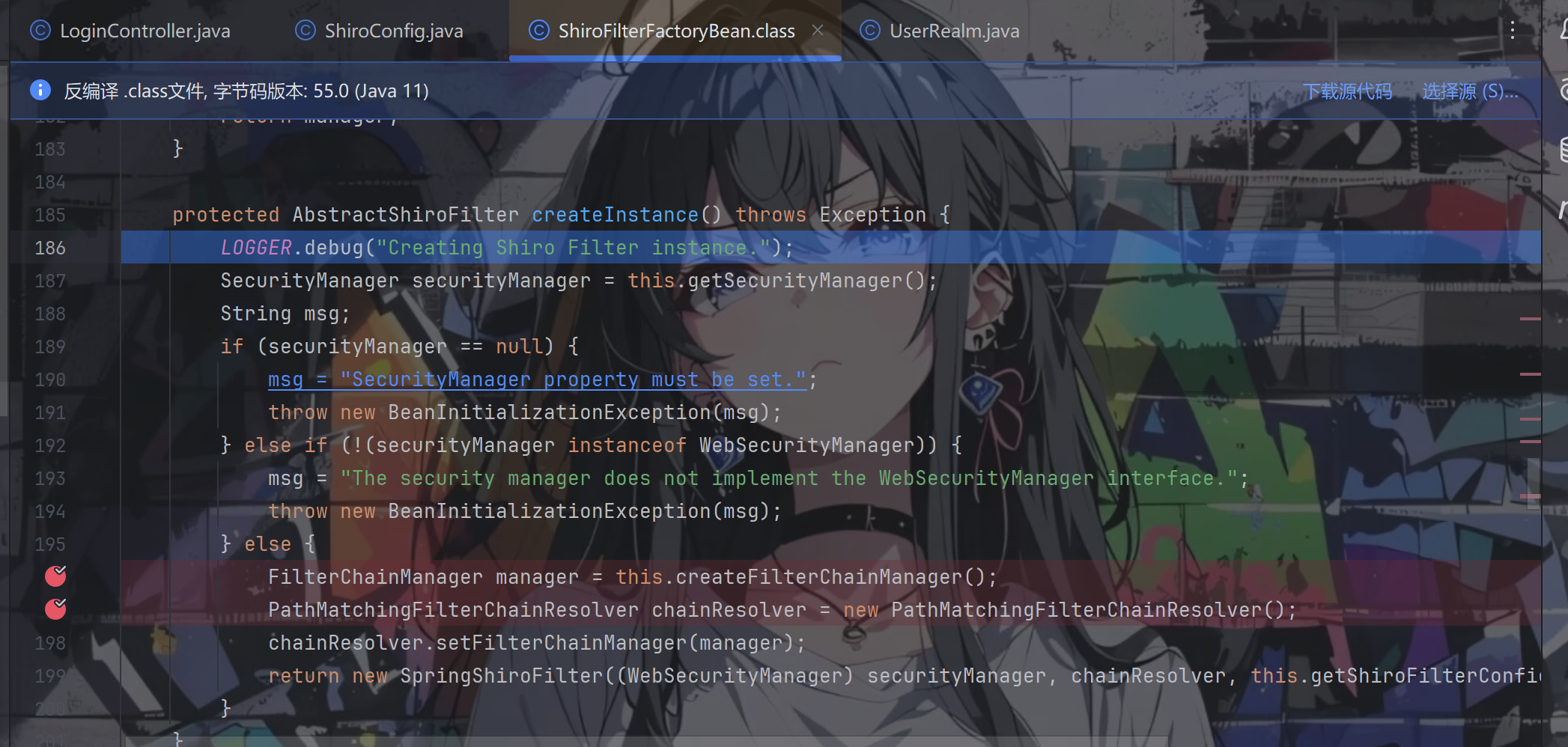
先获取到我们配置的 SecurityManager,这个获取是向上获取的,也就是去找 ShiroConfig 这个文件当中的 SecurityManager,在这里是 ShiroConfig#DefaultWebSecurityManager
接着往下判断 securityManager 是否为 null,以及是否为 WebSecurityManager,如果是的话就抛出异常。如果不是的话,则创建一个 FilterChainManager,这个类的主要功能是链式过滤。我们跟进看一下这个类是怎么被创建出来的,以及其中存储了哪些信息。
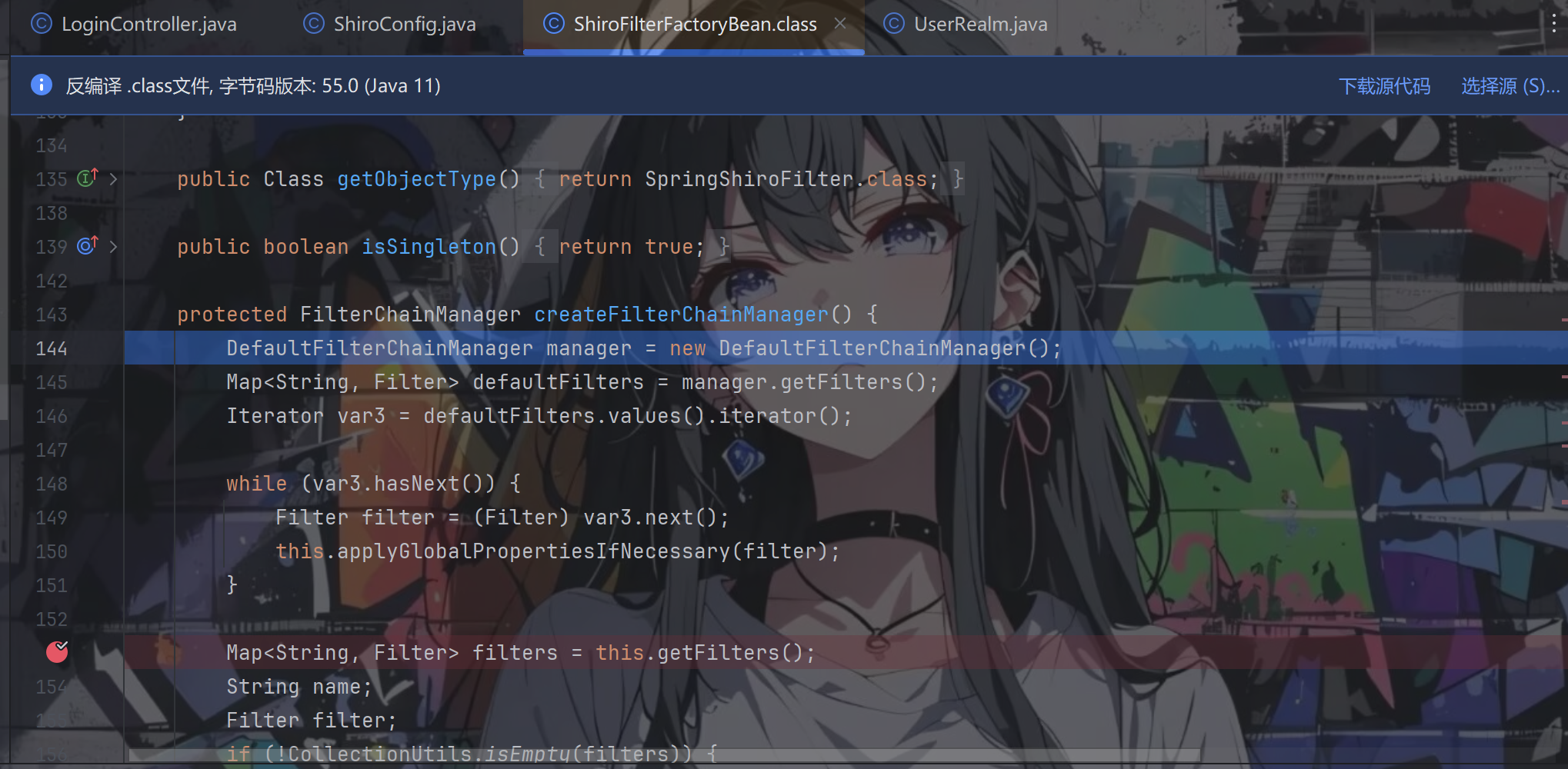
第一步 new 了一个 DefaultFilterChainManager 类,在它的构造方法中将 filters 和 filterChains 两个成员变量都初始化为一个能保持插入顺序的 LinkedHashMap,之后再调用 addDefaultFilters() 方法添加 Shiro 内置的一些过滤器。
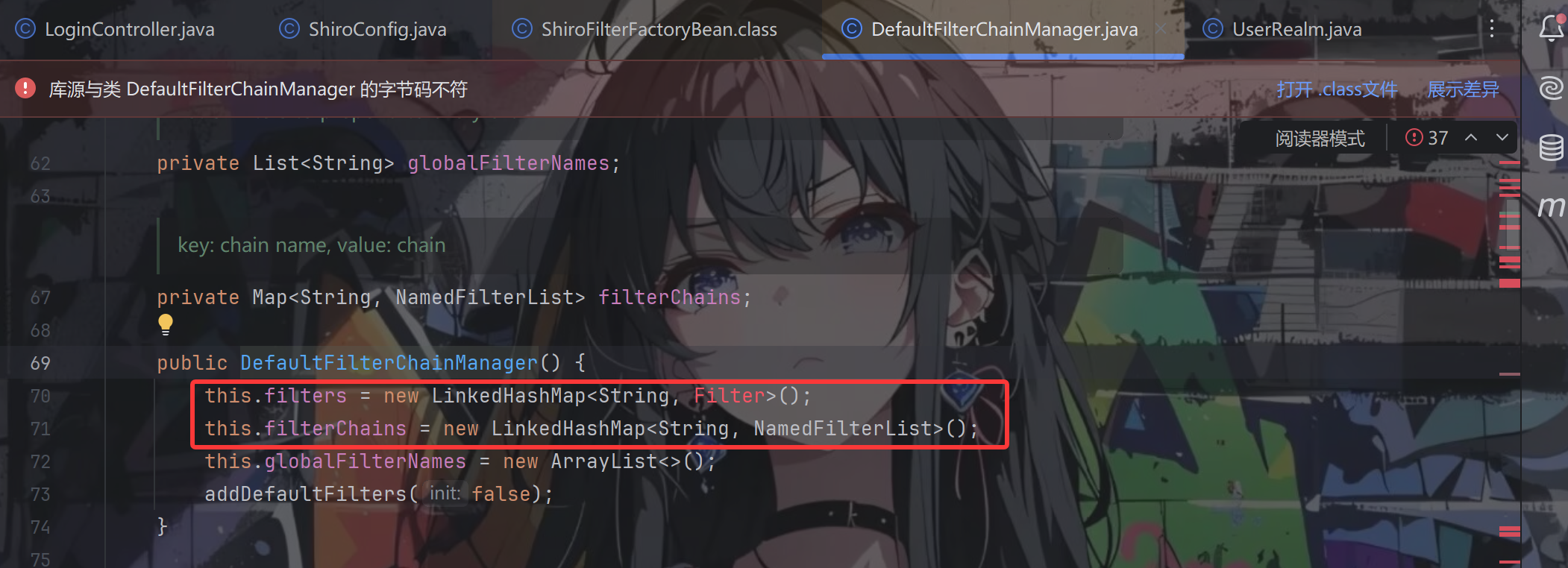
往下,将所有的 filters 保存到了 var3 这个迭代器中,再将 var3 丢进循环里面
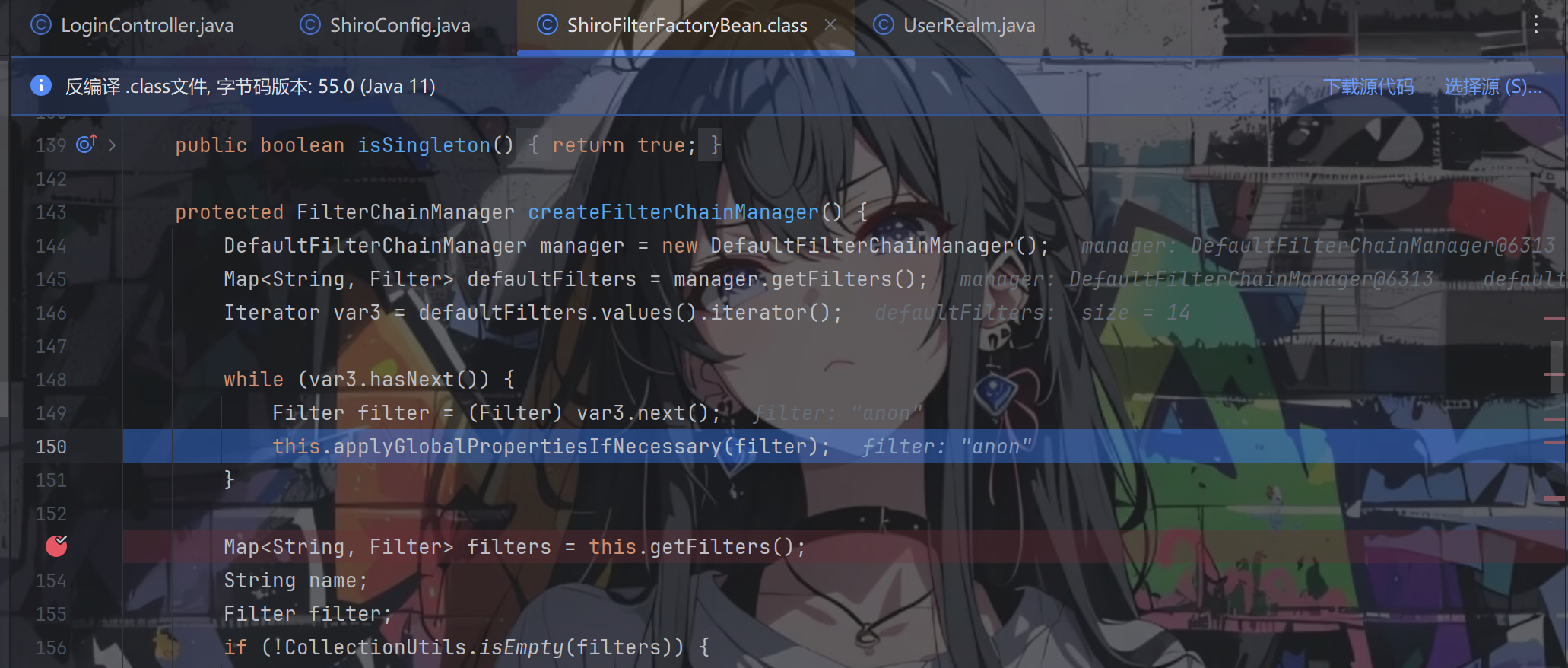
applyGlobalPropertiesIfNecessary() 方法遍历过滤器,并给过滤器添加了很多属性,跟进去看看
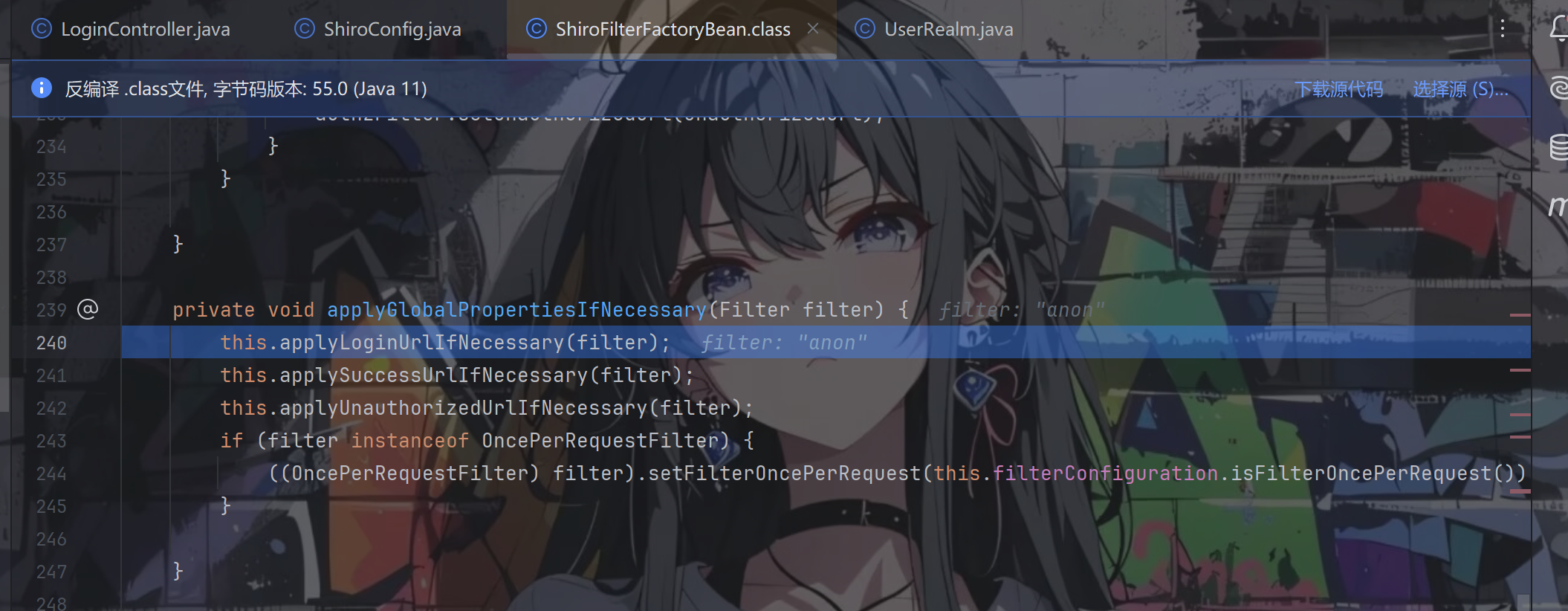
在这个方法中调用了三个方法,三个方法逻辑是一样的,分别是设置 loginUrl、successUrl 和unauthorizedUrl,我们就看第一个 applyLoginUrlIfNecessary,跟进
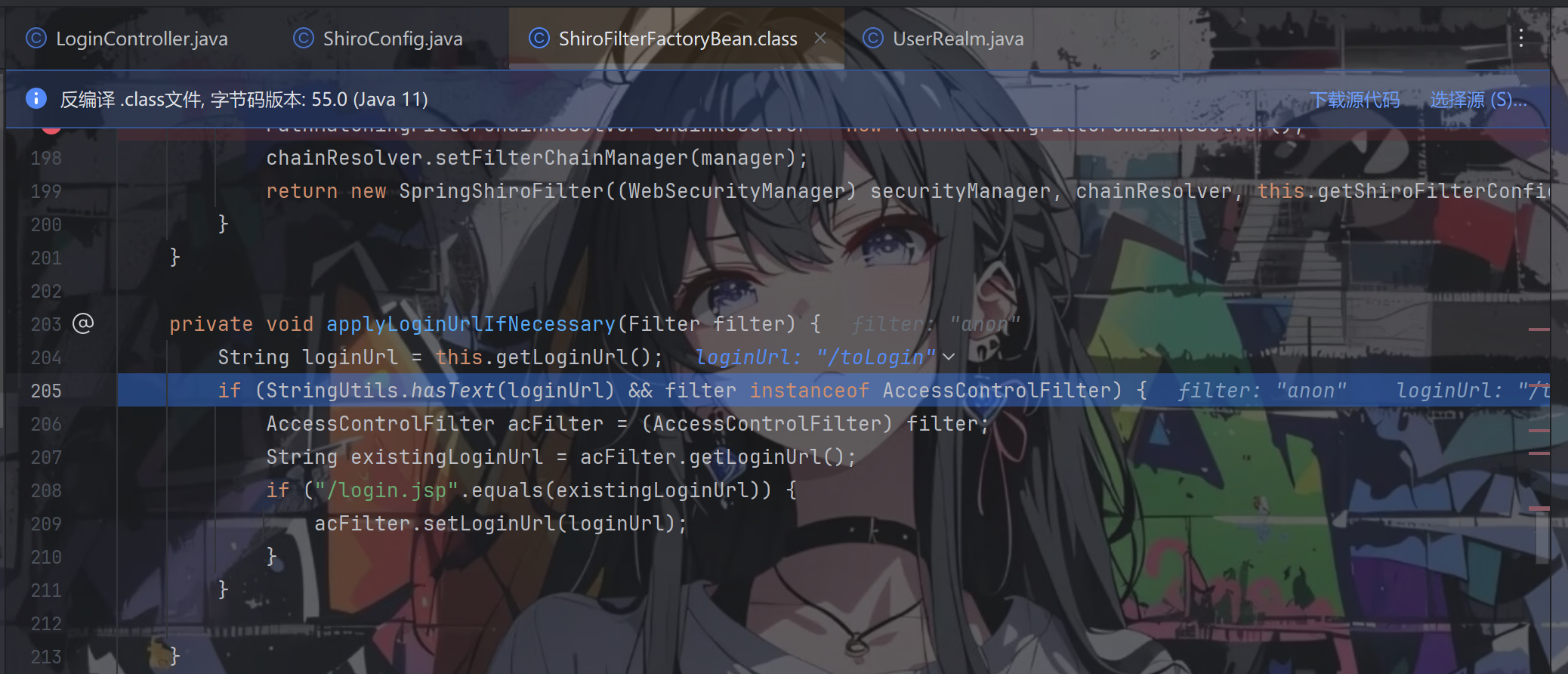
这个方法做的业务是将 loginUrl 赋值给 filter 去,在代码当中的逻辑是这样的;如果我们配置了loginUrl,那么会将 AccessControlFilter 中默认的 loginUrl 替换为我们设置的值,默认的 loginUrl 为 /login.jsp
后面两个方法道理一样,都是将我们设置的参数替换进去,只不过第三个认证失败跳转 URL 的默认值为 null。
这里的 this.getLoginUrl();是从我们 shiroFilter Bean 中,setLoginUrl 的值

回到 org.apache.shiro.spring.web.ShiroFilterFactoryBean#createFilterChainManager 代码中
在迭代器工作结束之后,继续往下看。先获取到自定义的过滤器,将内容保存在 filters 中,filters 变量默认为空,如果我们配置了自定义的过滤器,那么会将其添加到 filters 中。
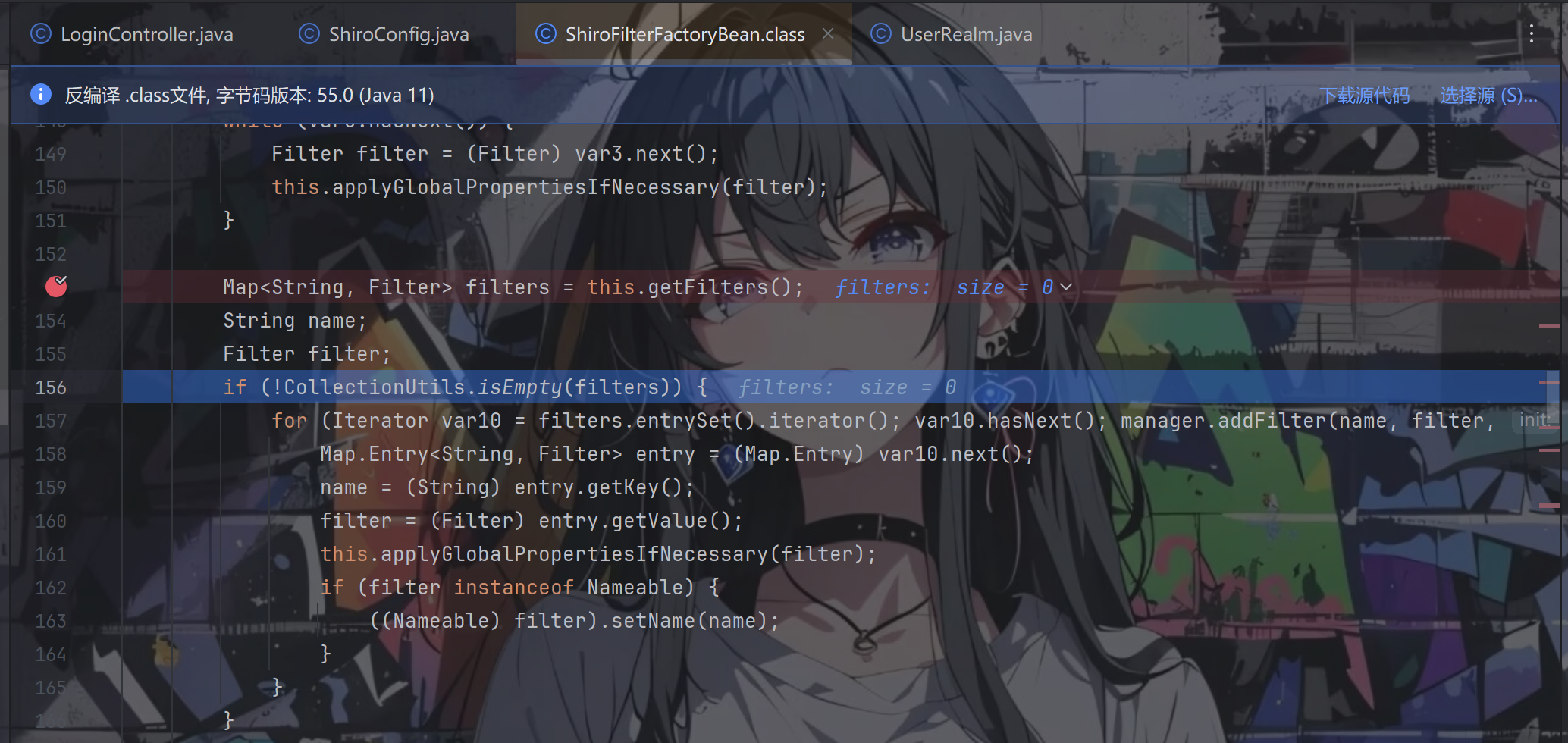
继续往下,通过 getFilterChainDefinitionMap() 方法把自定义过滤器的规则拿出来,并放进迭代器循环
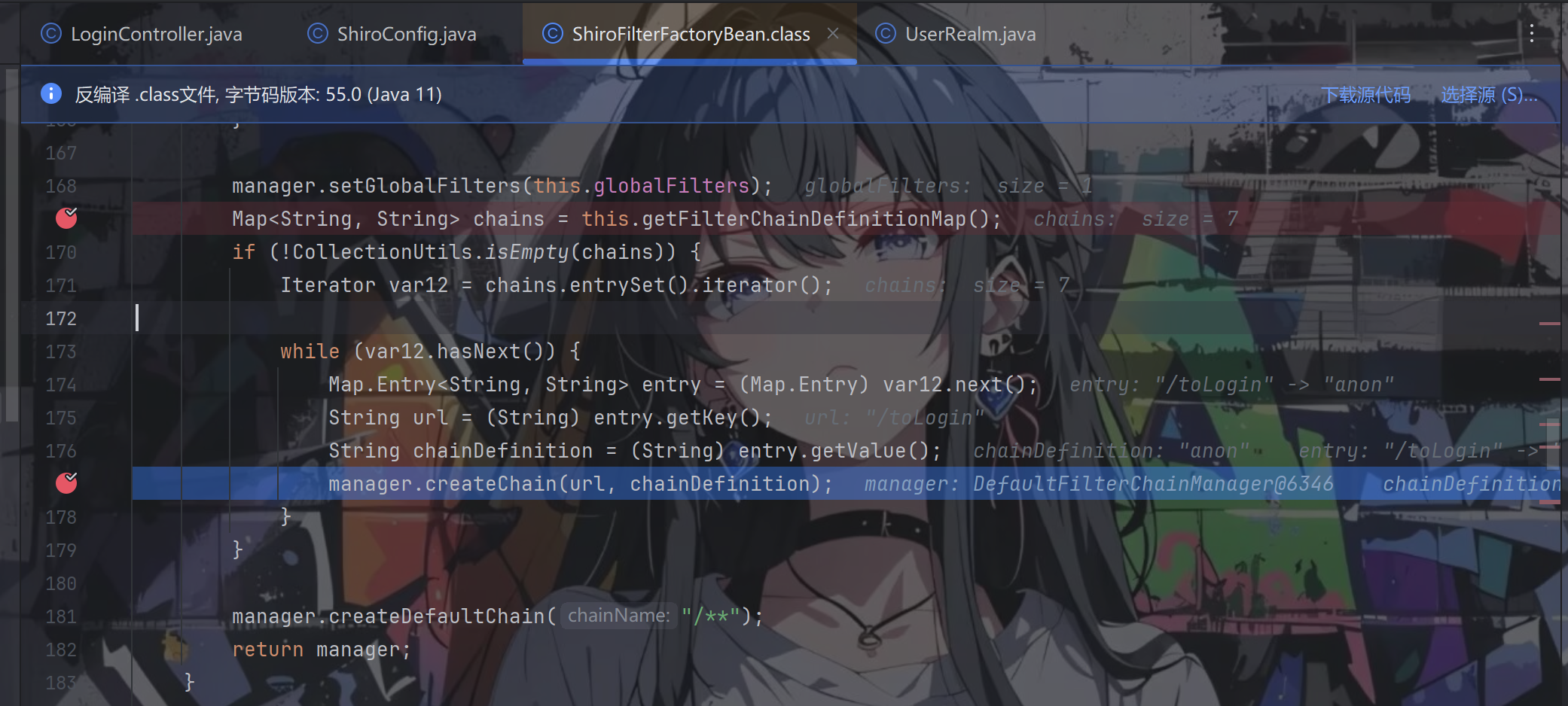
跟进 createChain() 方法,chainName 是我们配置的过滤路径,chainDefinition 是该路径对应的过滤器,通常我们都是一对一的配置,比如:filterMap.put("/login", "anon");,但看到这个方法我们知道了一个过滤路径其实是可以通过传入["filter1","filter2"...]配置多个过滤器的。在这里会根据我们配置的过滤路径和过滤器映射关系一步步配置过滤器执行链,其实这也就是之前说的,shiro 支持链语句表达式
举个例子,在这里我们第一个遇到的过滤路径和过滤器如下
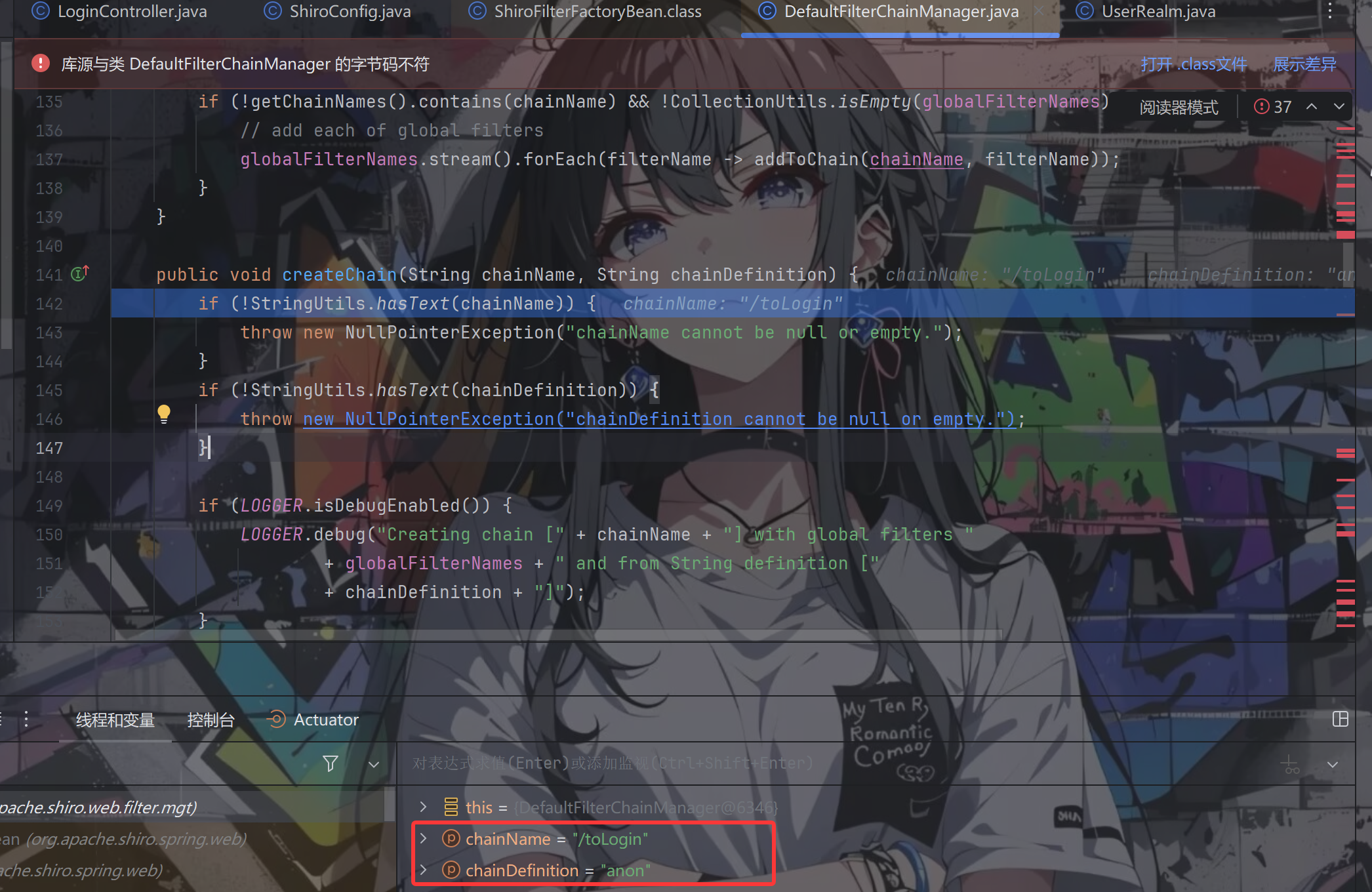
将 shiro 规则拿出来之后,会进行循环迭代,将原本的规则数据 ———— perms[user:update] 转换为 ["perms","user:update"],再调用 addToChain() 方法将规则添加到对应的 chain 中,跟进 addToChain() 方法
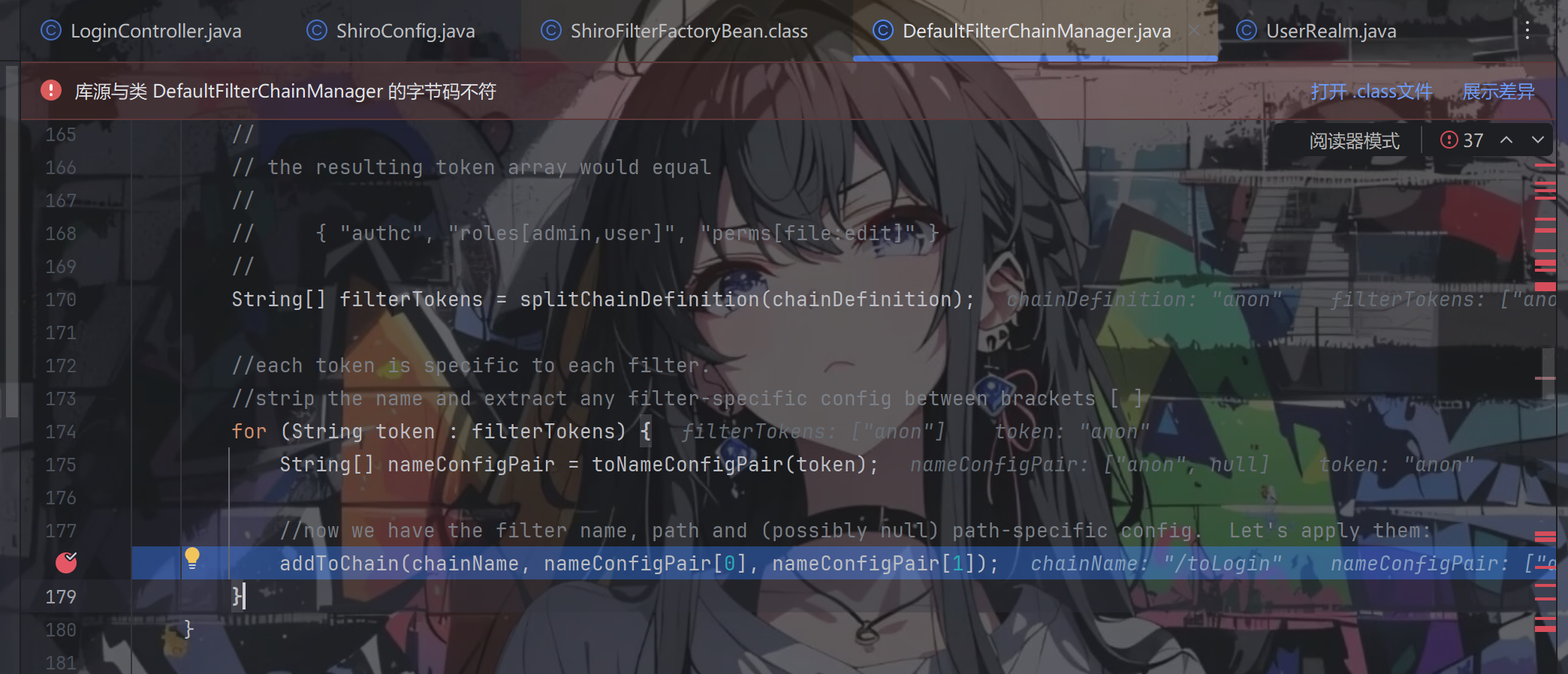
addToChain() 方法先从 filters 中根据 filterName 获取对应过滤器,然后调用 ensureChain() 方法,ensureChain() 方法会先从 filterChains 根据 chainName 获取 NamedFilterList,获取不到就创建一个并添加到 filterChains 然后返回。
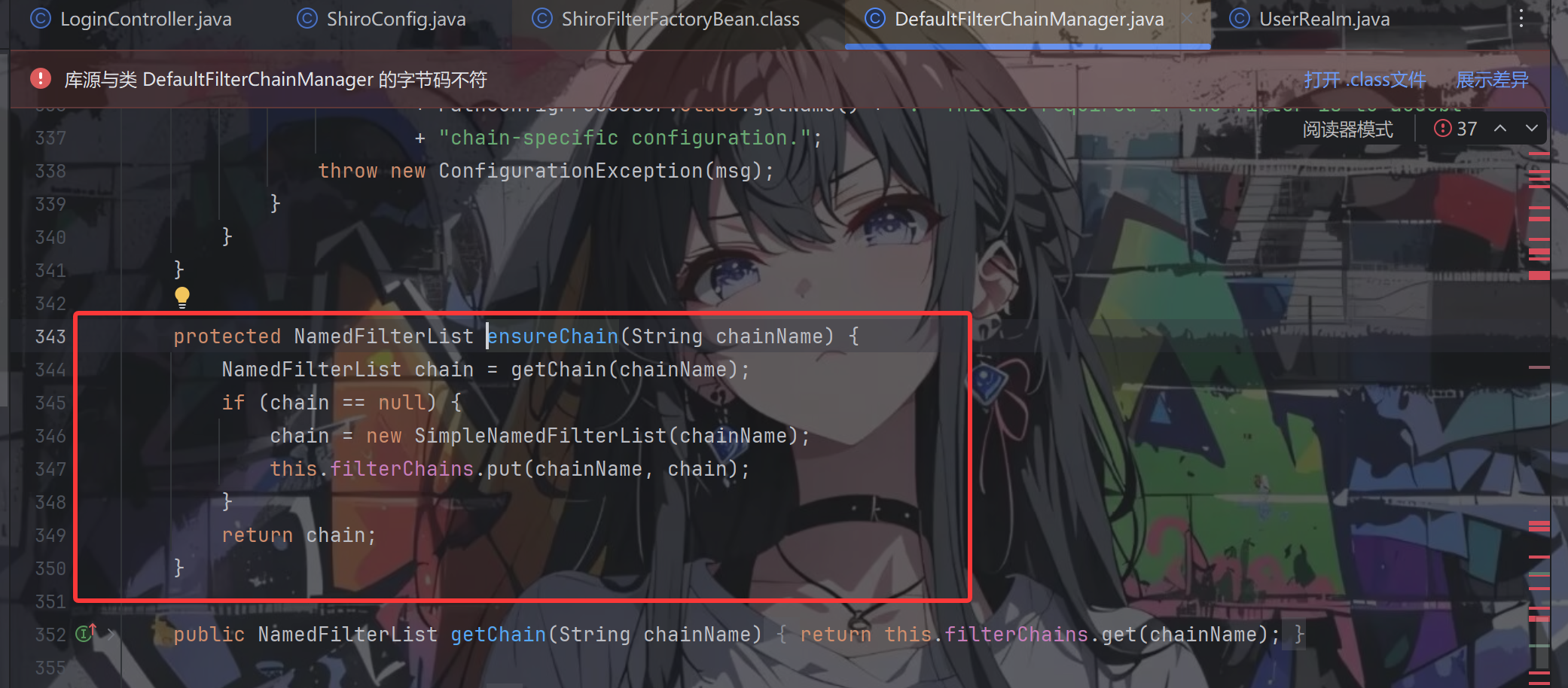
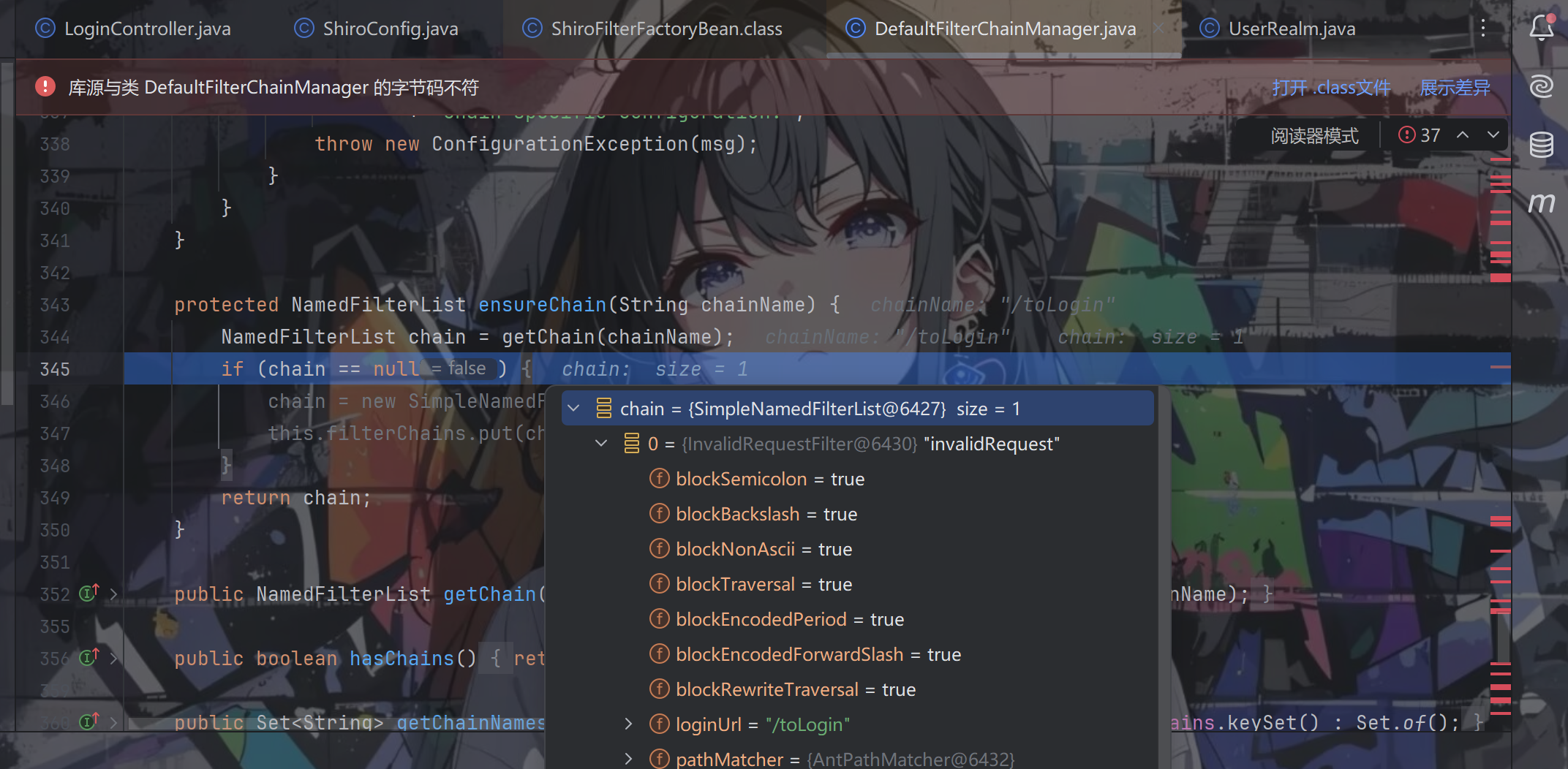
因为过滤路径和过滤器是一对多的关系,所以 ensureChain() 方法返回的 NamedFilterList 其实就是一个有着 name 称属性的 List<Filter>,这个 name 保存的就是过滤路径,List 保存着我们配置的过滤器。获取到 NamedFilterList 后在将过滤器加入其中,这样过滤路径和过滤器映射关系就初始化好了。
至此,createInstance() 方法中的 createFilterChainManager() 方法才算执行完成,它返回了一个 FilterChainManager 实例。之后再将这个 FilterChainManager 注入 PathMatchingFilterChainResolver 中,它是一个过滤器执行链解析器。
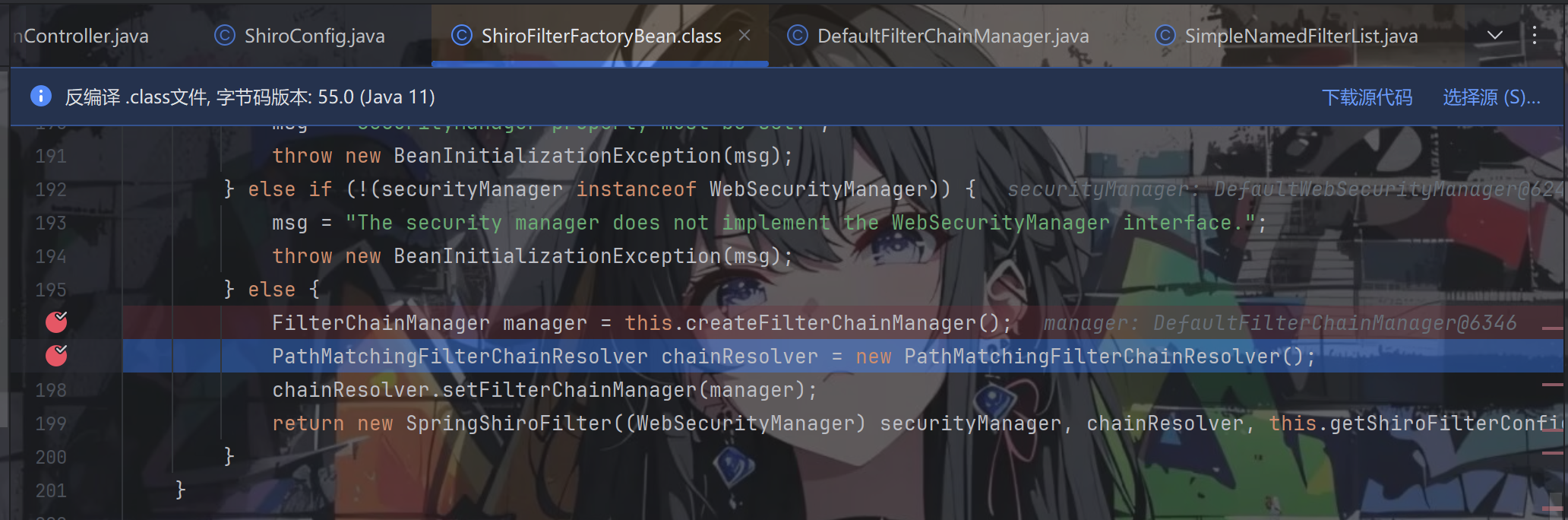
回到 createInstance() 方法下,跟进 new PathMatchingFilterChainResolver(),这里需要提前在 getChain() 方法处下一个断点
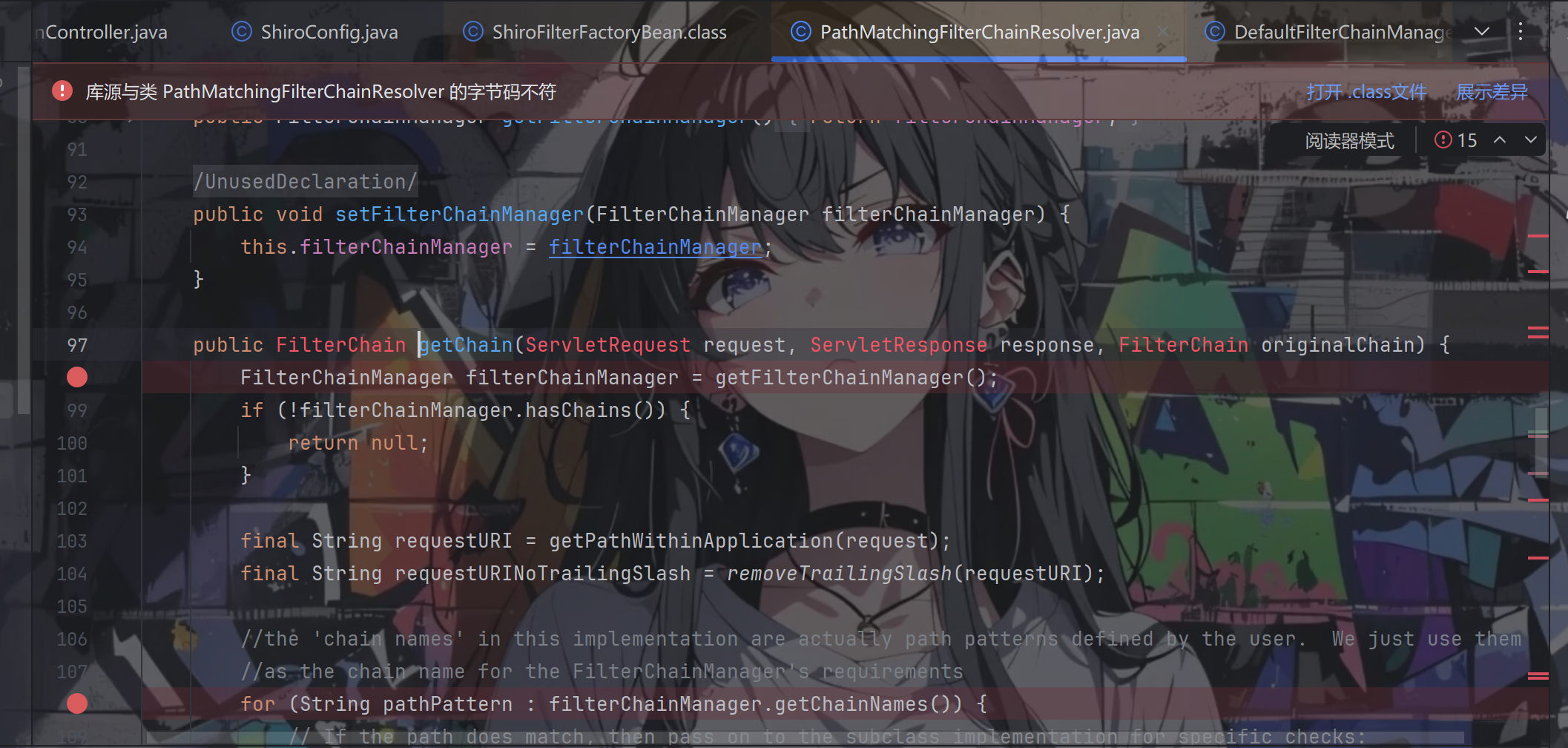
看到形参中 ServletRequest 和 ServletResponse 这两个参数,我们每次请求服务器都会调用这个方法,根据请求的 URL 去匹配过滤器执行链中的过滤路径,匹配上了就返回其对应的过滤器进行过滤。
这个方法中的 filterChainManager.getChainNames() 返回的是根据我们的配置配置生成的执行链的过滤路径集合,执行链生成的顺序跟我们的配置的顺序相同。从前文中我们也提到,在 DefaultFilterChainManager 的构造方法中将 filterChains 初始化为一个 LinkedHashMap。如果第一个匹配的过滤路径就是 /** 那后面的过滤器永远也匹配不上(会直接满足if从句,return回去
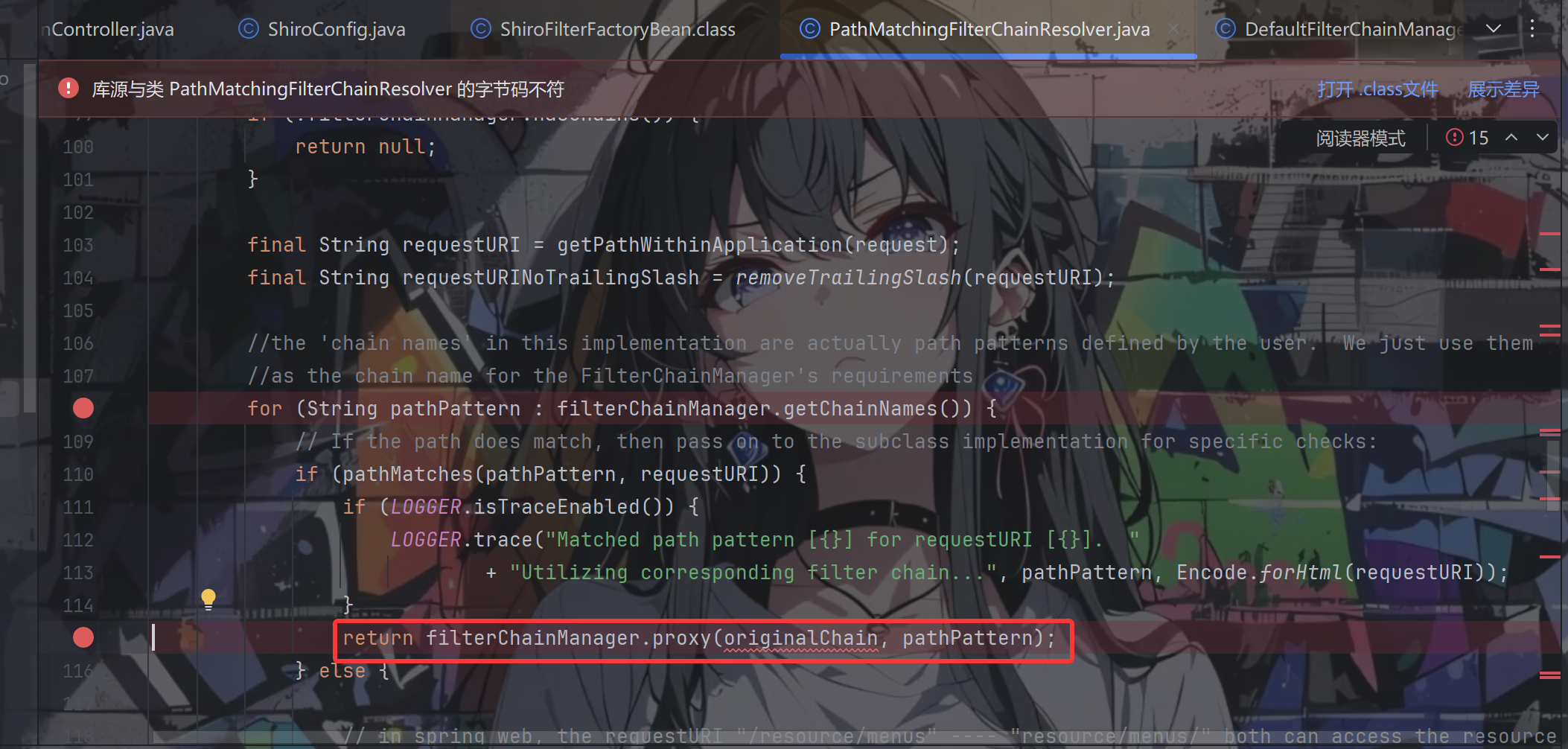
过滤实现与登录检测
如果之前分析过 Tomcat 的流程,这个过滤实现其实相当好理解
Tomcat 在收到请求之后,会进行一系列的 doFilter() 的链式操作,因为这里用到了 shiro 组件,那么 shiro 的某个 Filter 肯定也会被调用进这个 filterChain 当中,OncePerRequestFilter 就是众多 Filter 中的一个。它所实现的 doFilter()方法调用了自身的抽象方法 doFilterInternal(),这个方法在它的子类 AbstractShiroFilter 中被实现了。
而 OncePerRequestFilter 通过一步步调用,最终调用到了上文提到的 PathMatchingFilterChainResolver.getChain() 方法,这一段流程和 Tomcat 实际上差别不大,我这里仅放出调用栈,不作过多的代码跟进。
1 | getChain:98, PathMatchingFilterChainResolver (org.apache.shiro.web.filter.mgt) |
我们去到 OncePerRequestFilter 类的 doFilter() 方法处下个断点,在成功登录并具有 perms:add 权限后,访问。一开始加载的是 SpringShiroFilter 这个类,它是 shiro 与 spring 程序进行整合的默认 Filter,每一个请求都会经过这个 Filter
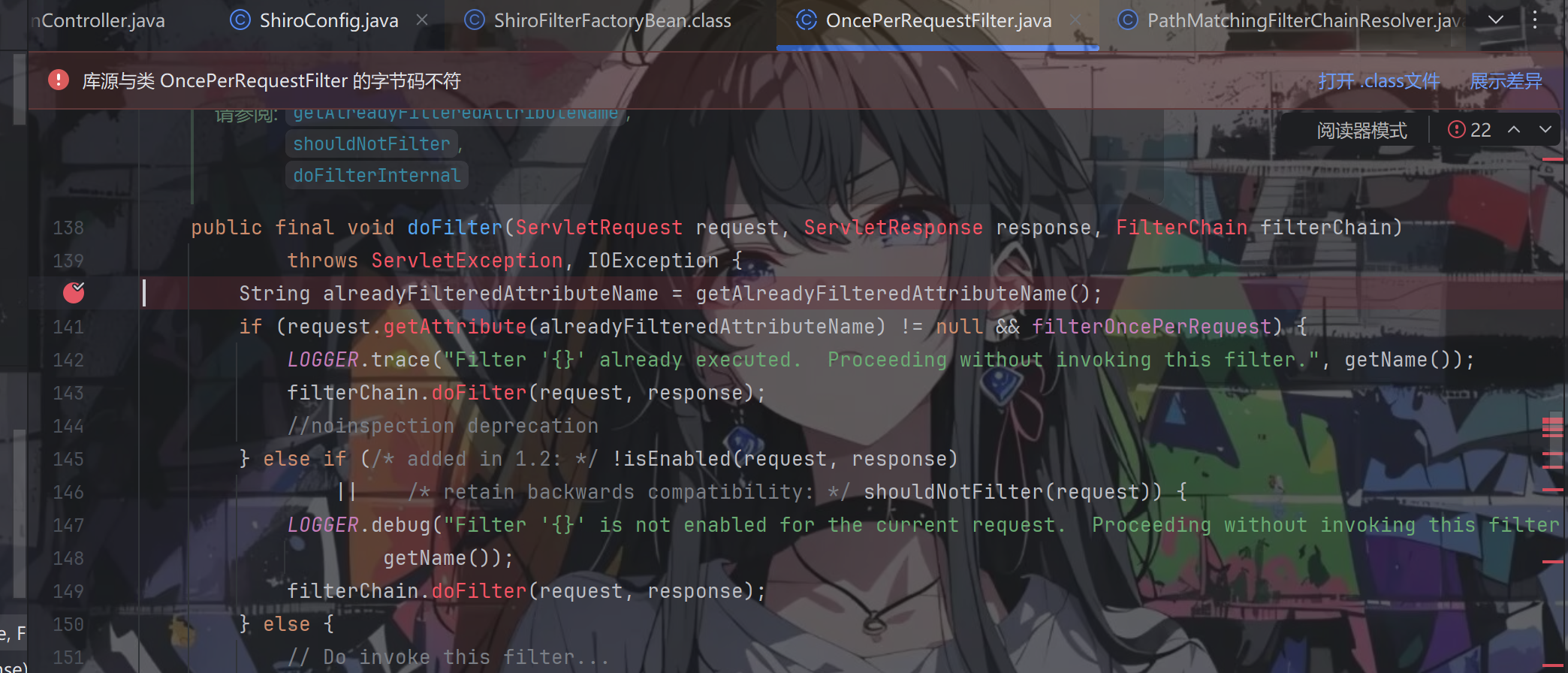
第一段的请求如上面调用栈所示,会最终去到 PathMatchingFilterChainResolver.getChain()
通过 getFilterChainResolver() 就拿到了上面提到的过滤器执行链解析器PathMatchingFilterChainResolver,然后再调用它的 getChain() 匹配获取过滤器,最终过滤器在executeChain() 中被执行。
访问登录页面
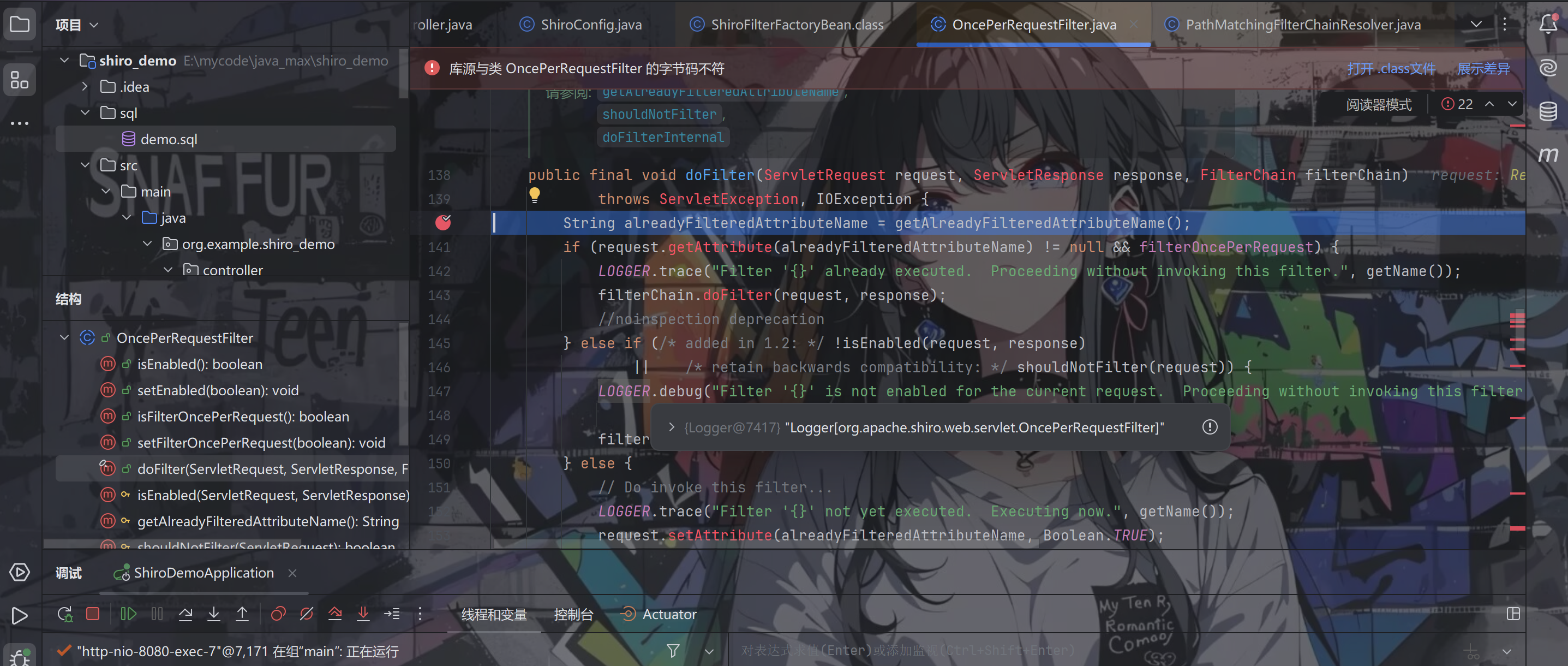
跟进getAlreadyFilteredAttributeName(),可以发现获取到的name就是我们ShiroConfig中的getShiroFilterFactoryBean

后面经过上面已展示的堆栈走到PathMatchingFilterChainResolver.getChain()
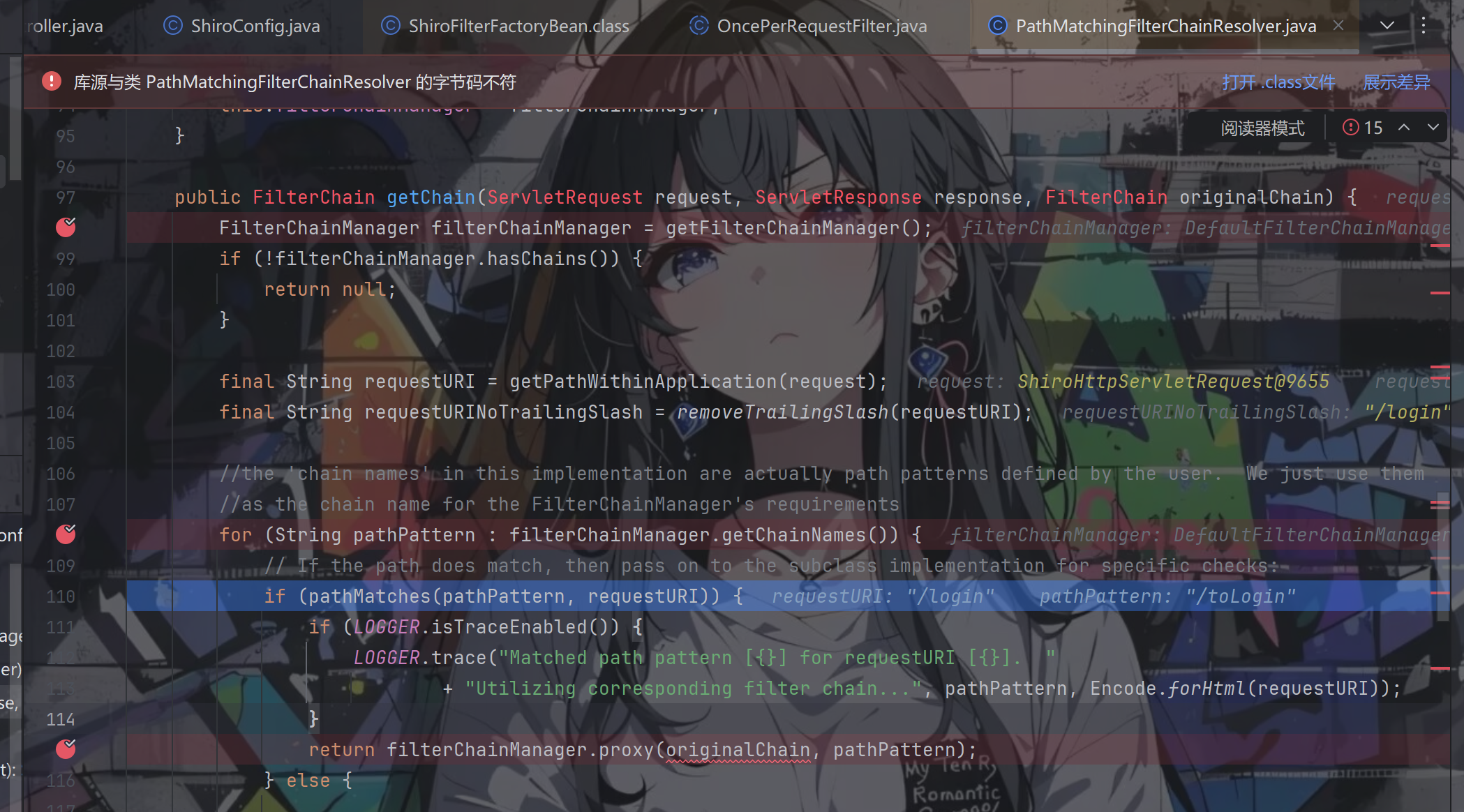
跟进pathMatches方法
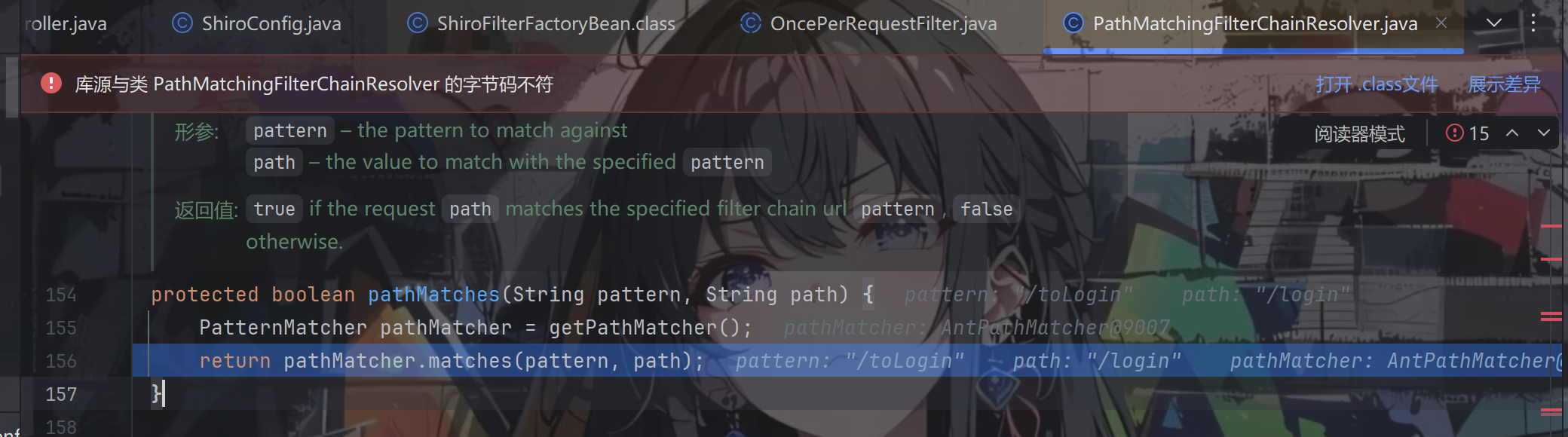
跟进matches方法,一直往下跟,直到在doMatch方法进行路径匹配
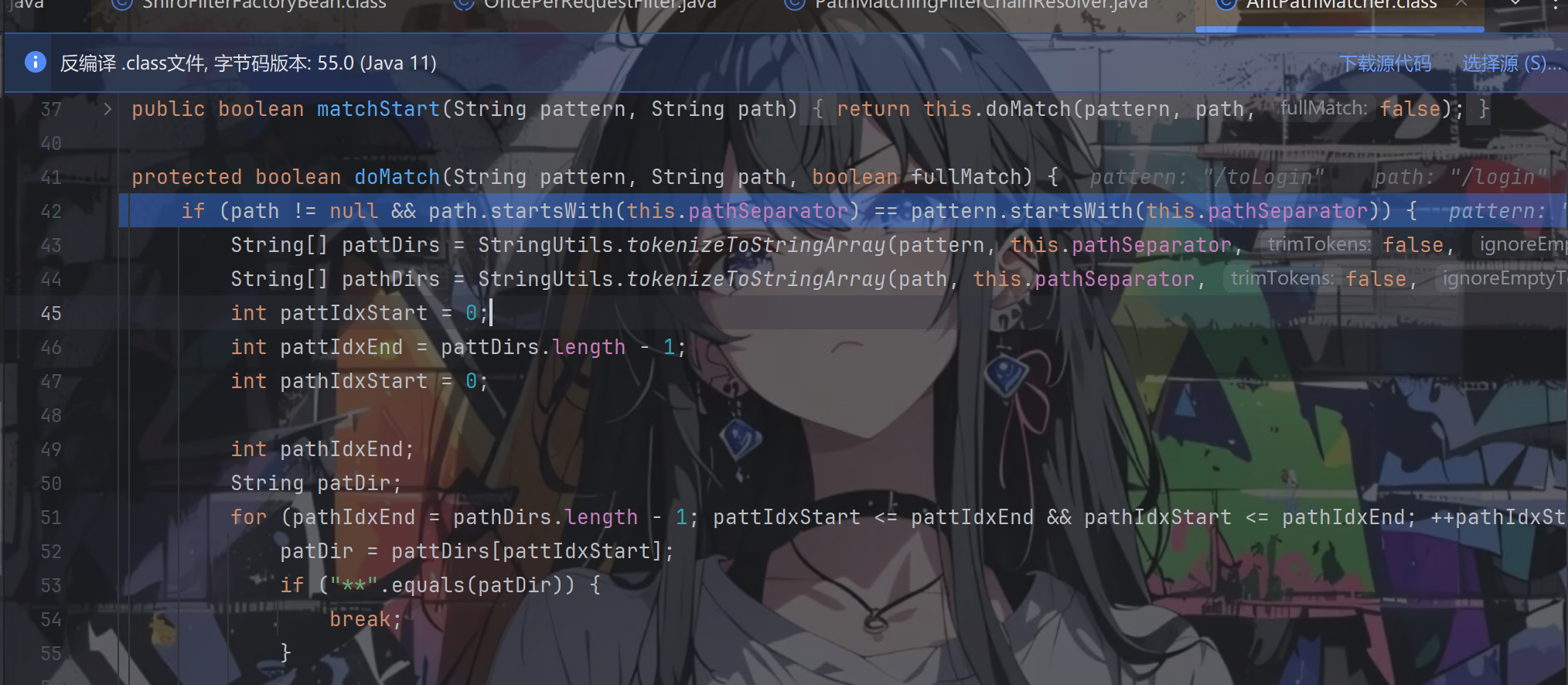
不匹配,返回到PathMatchingFilterChainResolver.getChain()的for循环中,这次成功匹配,return
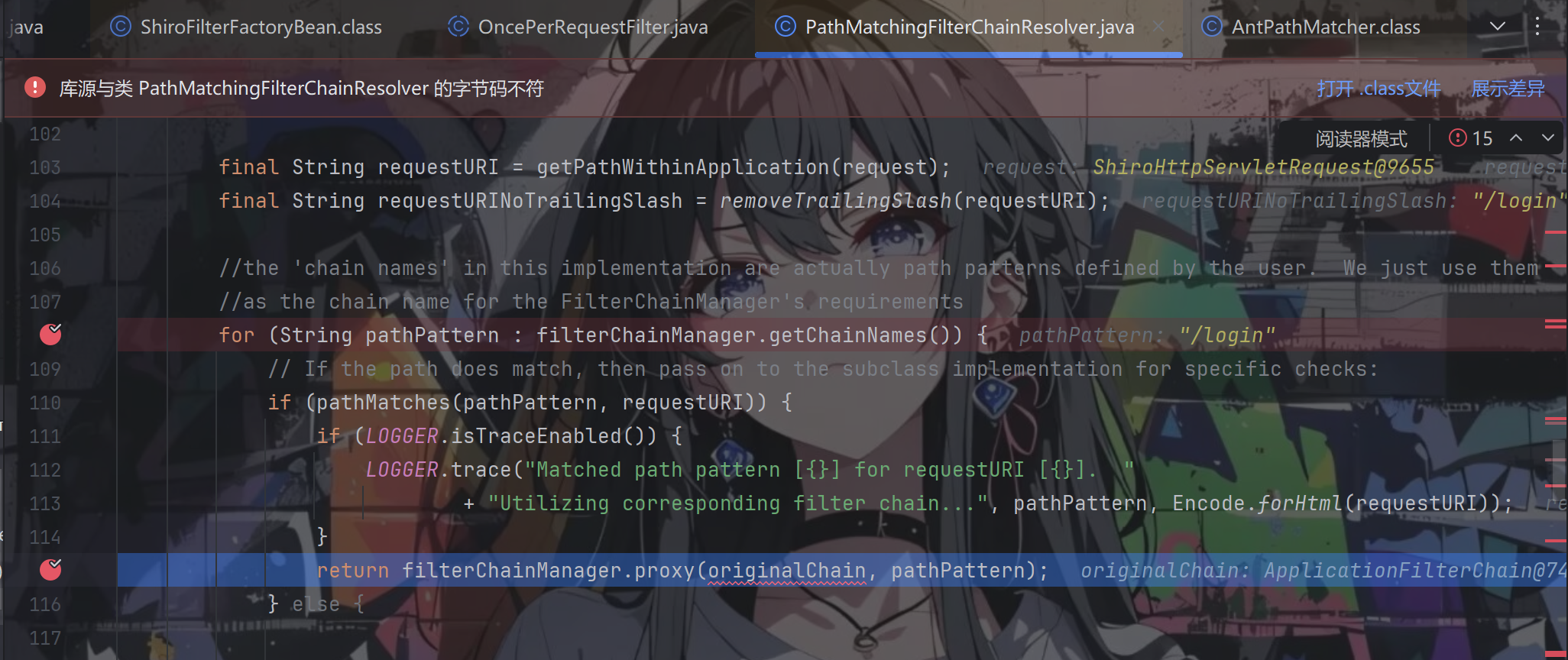
过滤器在excuteChain方法中被执行
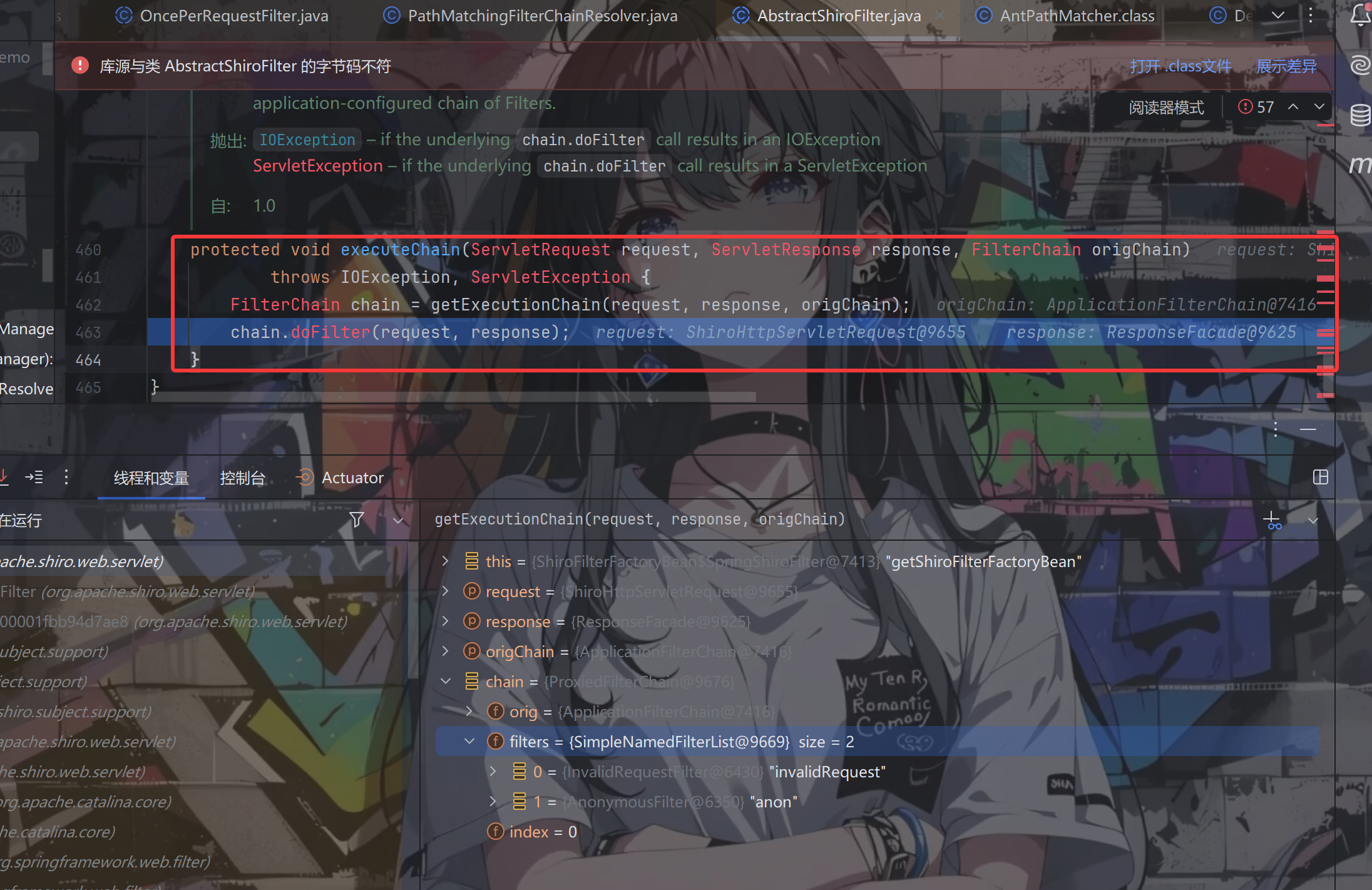
上面是访问登录页面,校验是否能够进行访问;下面是输入账号密码,进行登录操作
会走到LoginController.login方法中,执行subject.login方法
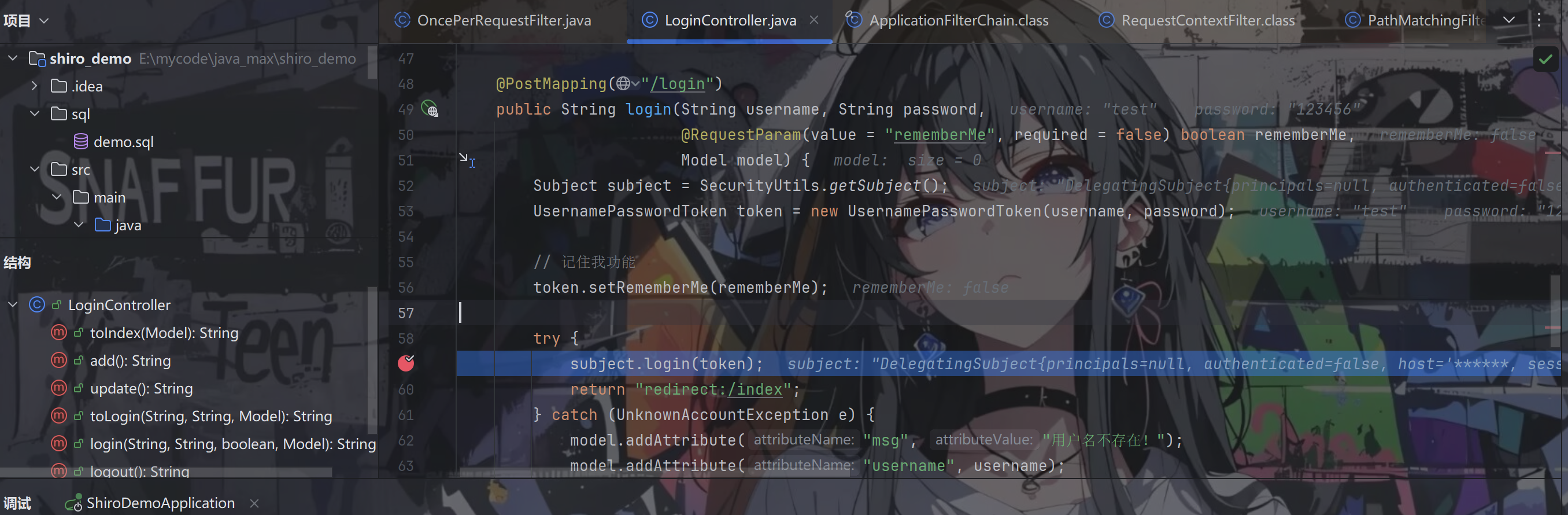
跟进login方法
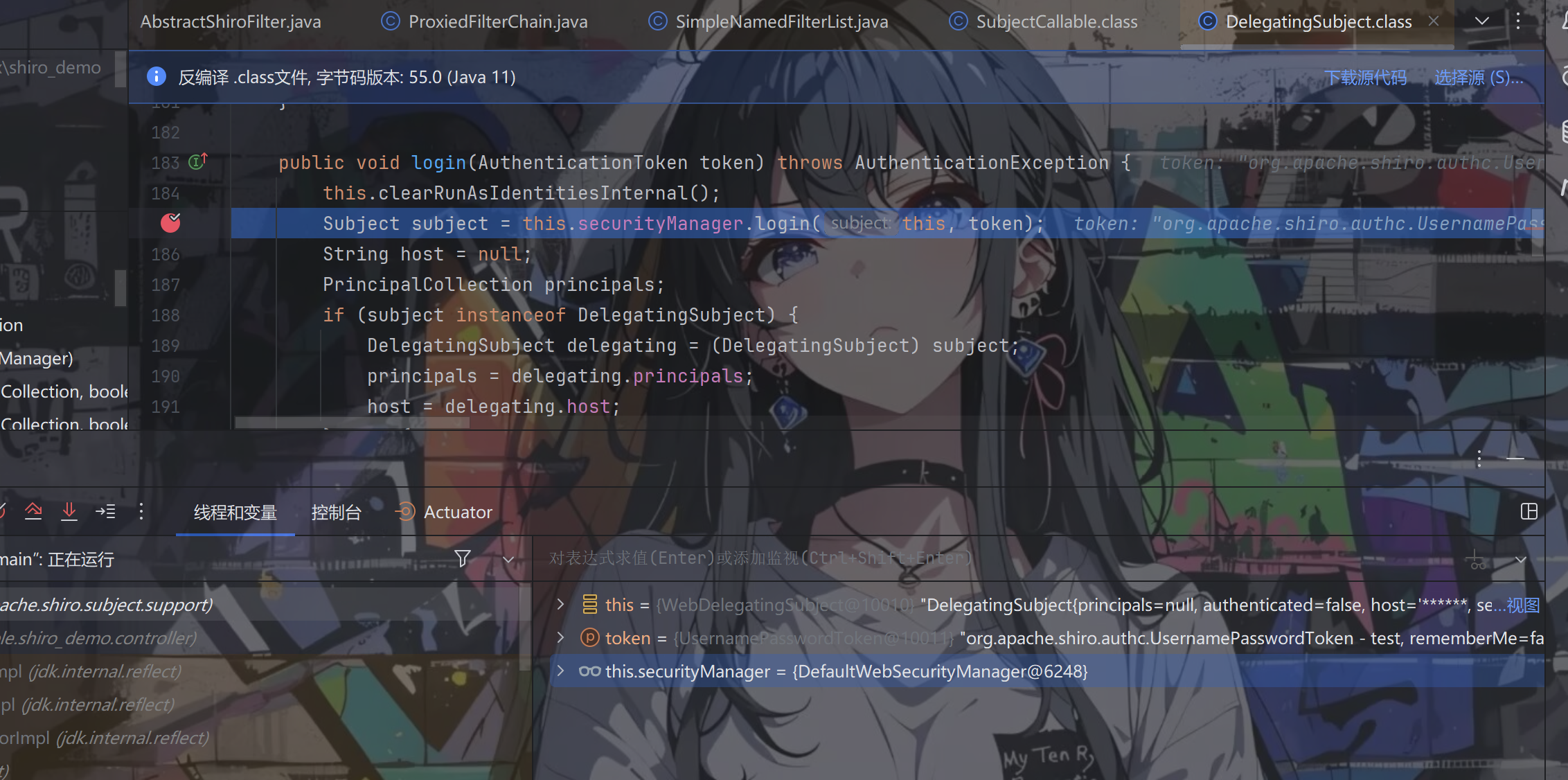
继续跟进this.securityManager.login方法
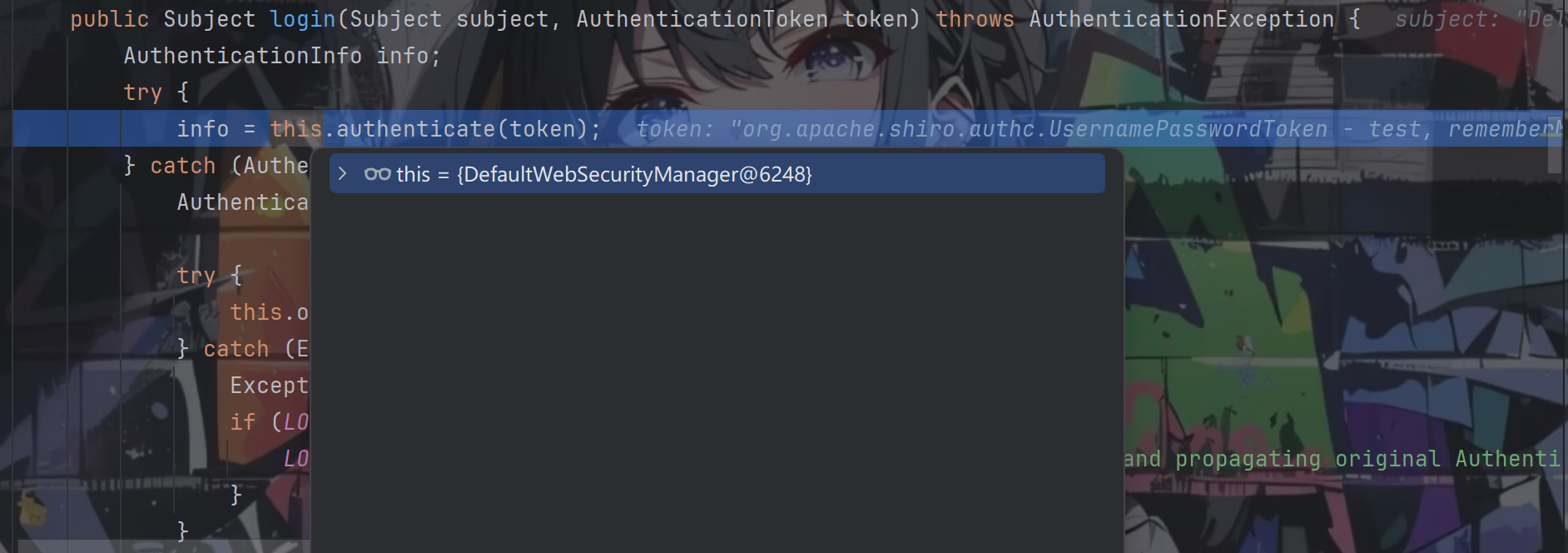
对token进行校验,跟进authenticate方法,然后一直跟进到AbstractAuthenticator.authenticate方法
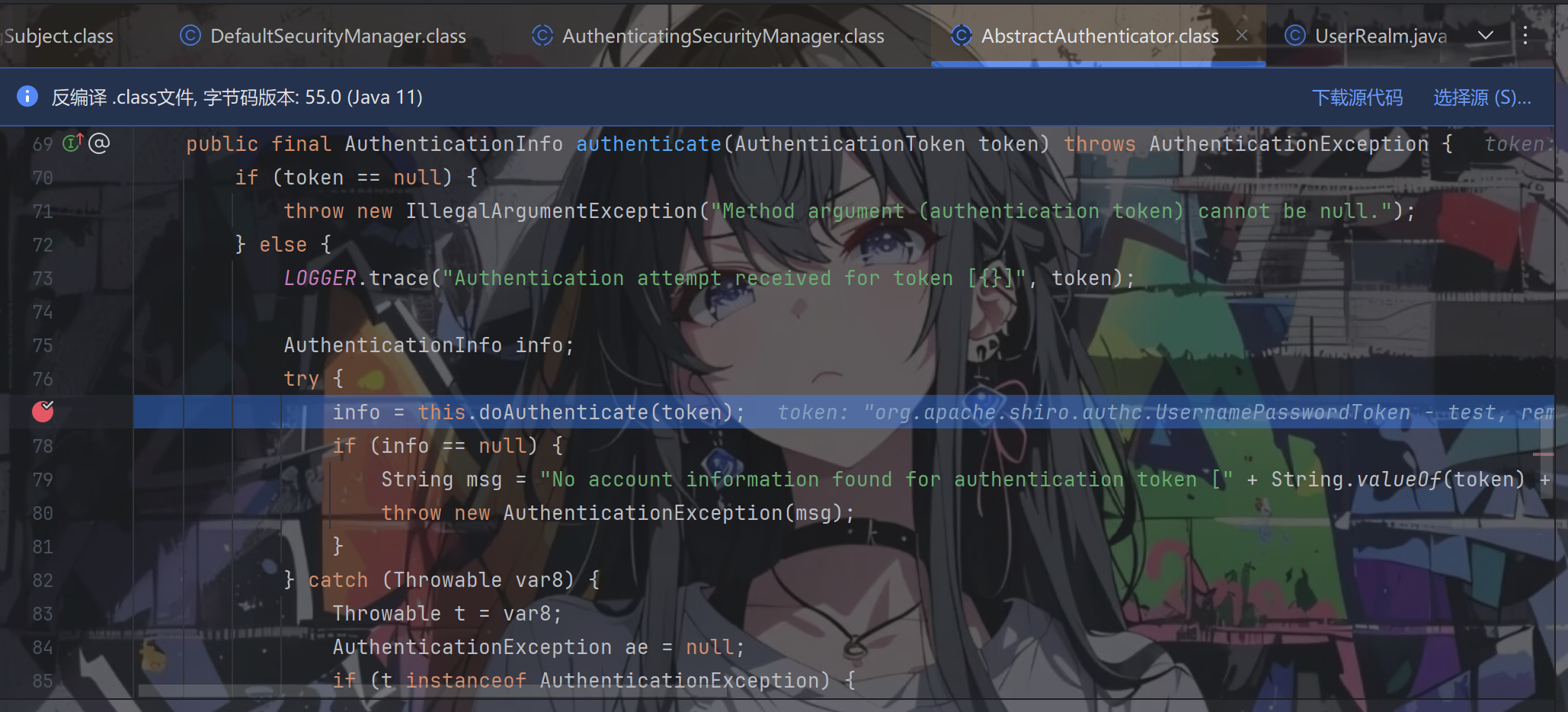
跟进doAuthenticate方法
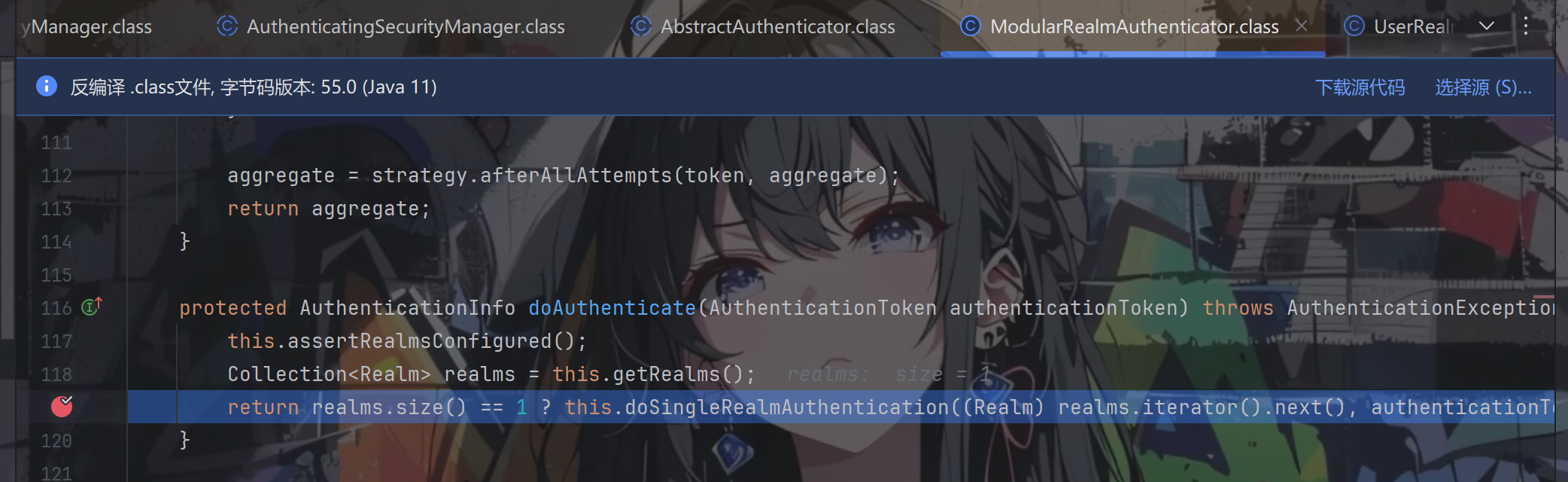
由于在demo中我们就写了一个UserReaml,所以跟进doSingleRealmAuthentication方法
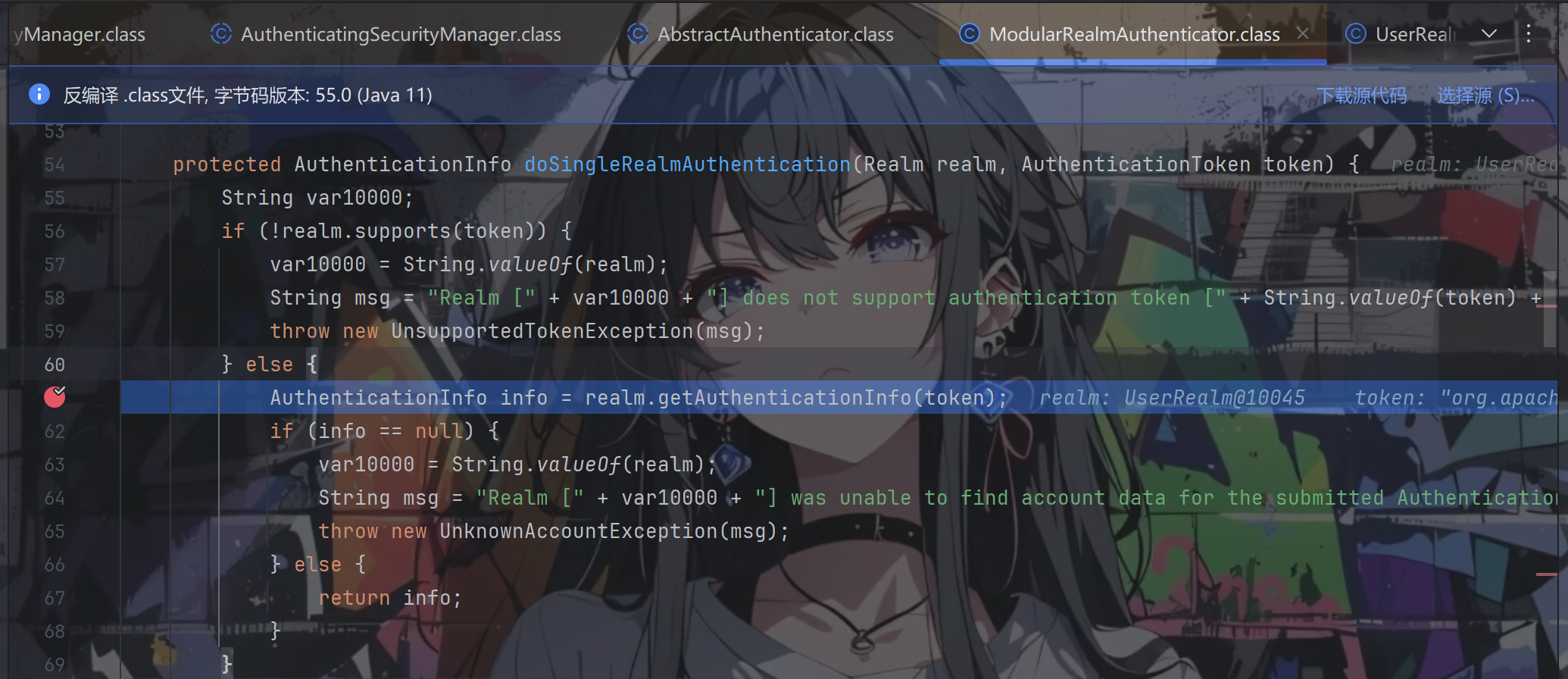
方法内容很清楚了,会执行我们写的UserReaml中的getAuthenticationInfo方法,对token进行校验
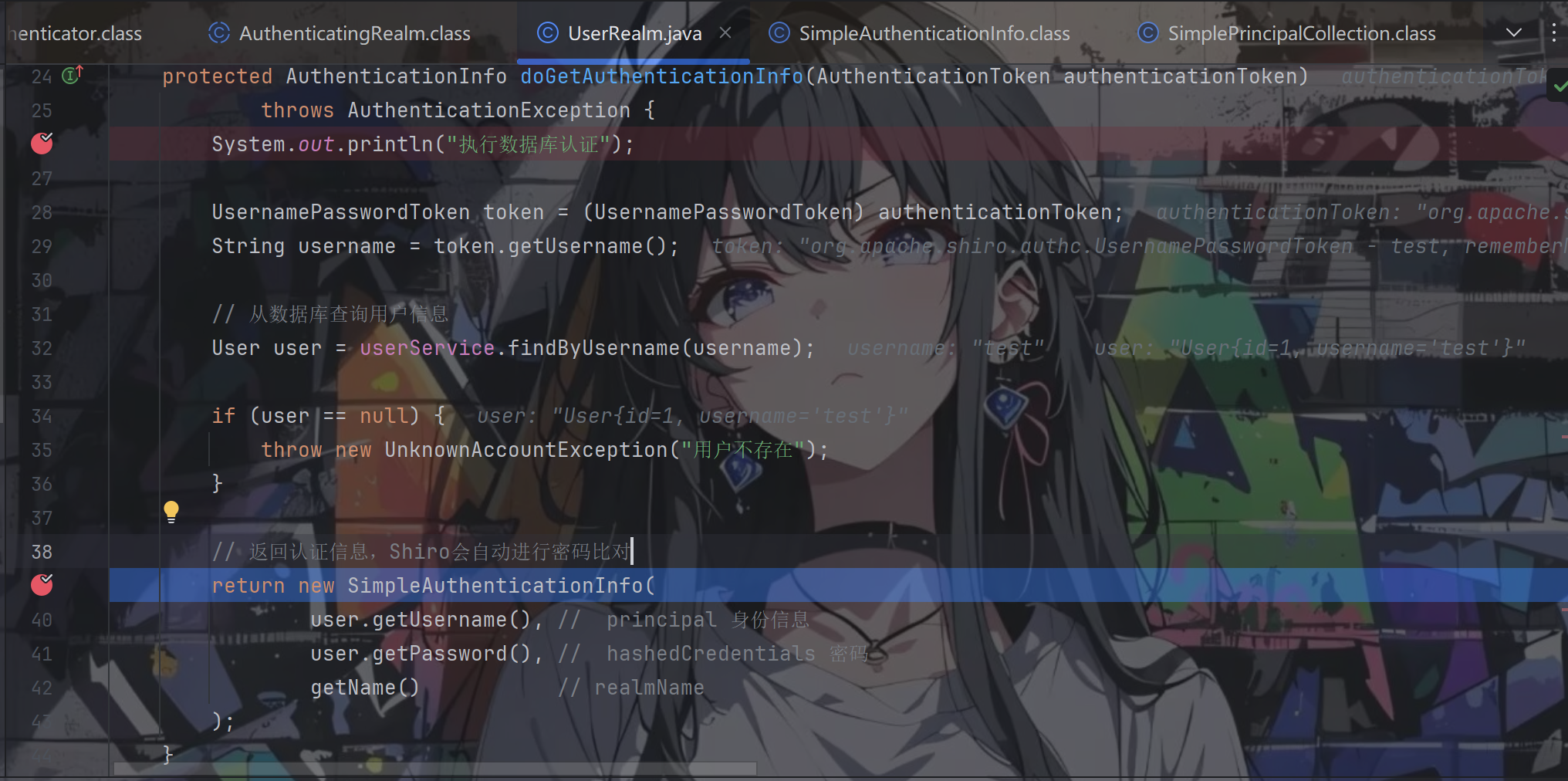
笔者这边好奇怎么进行的自动密码比较,所以跟进new SimpleAuthenticationInfo
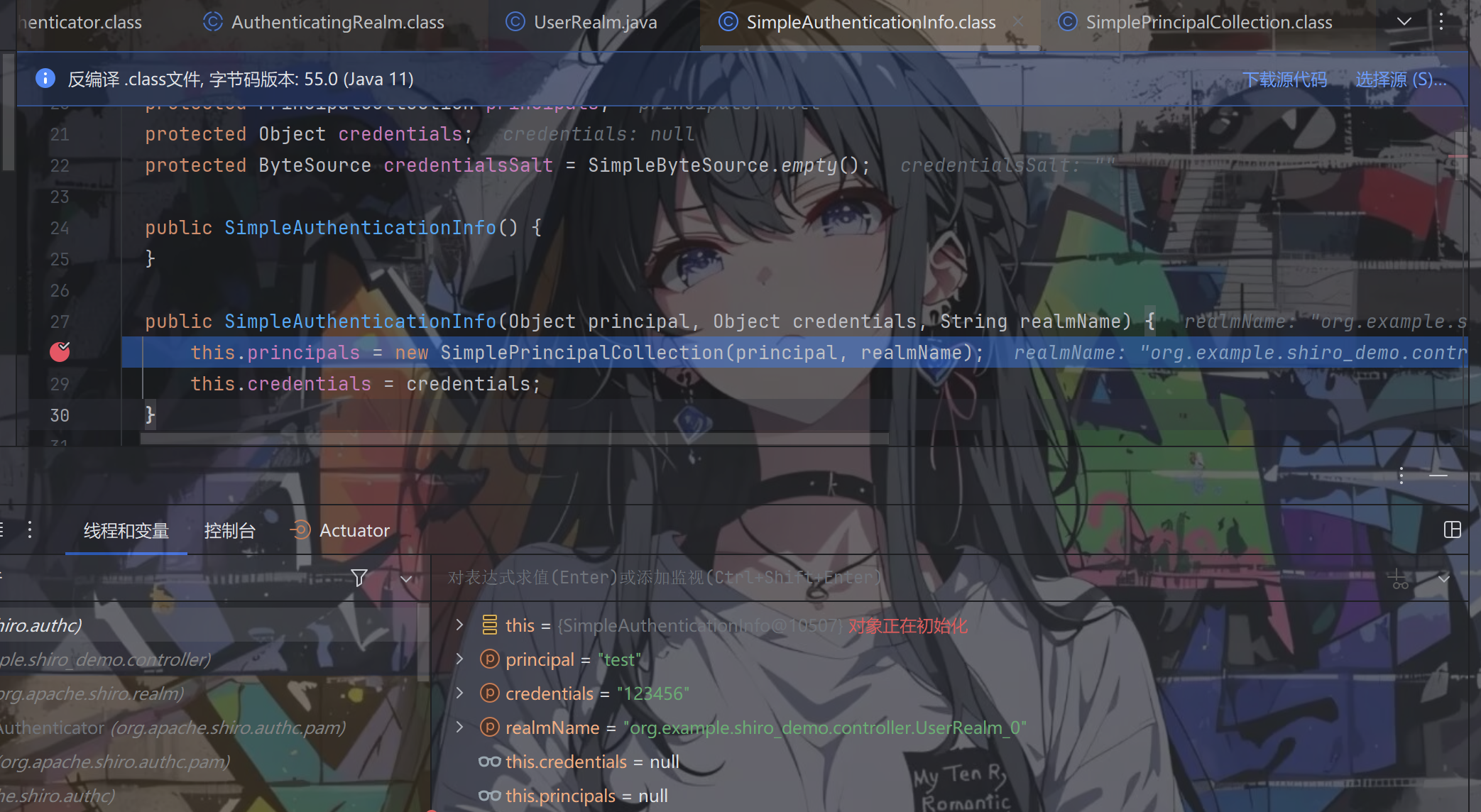
继续跟进
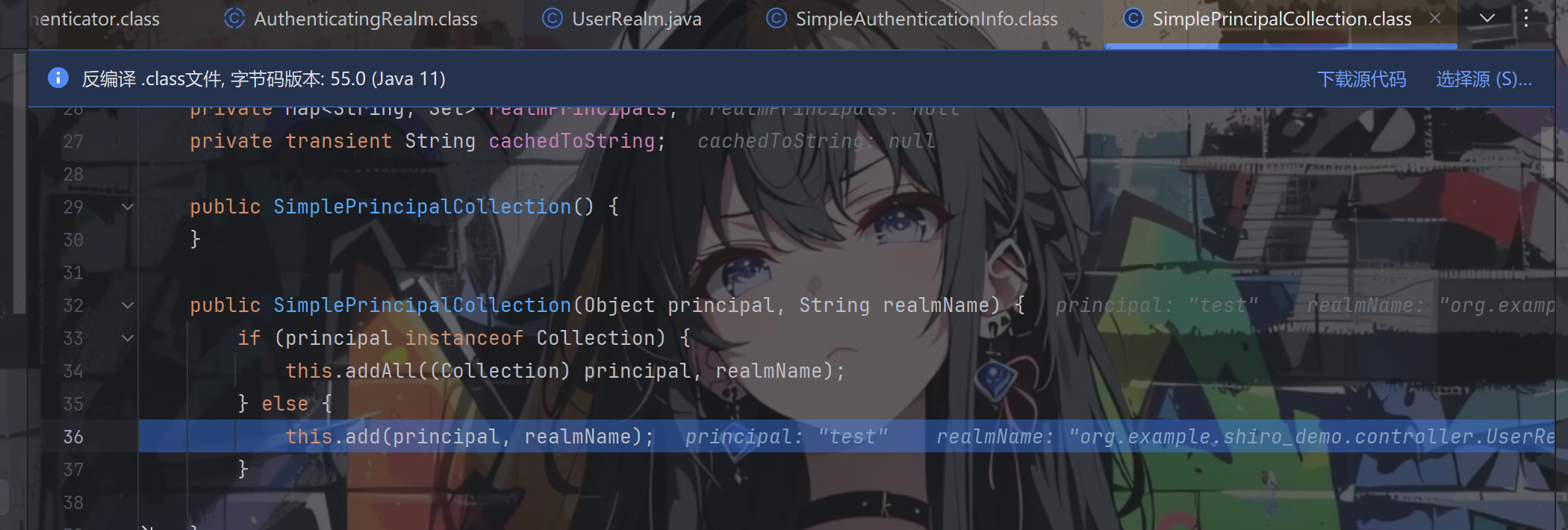
跟进add方法
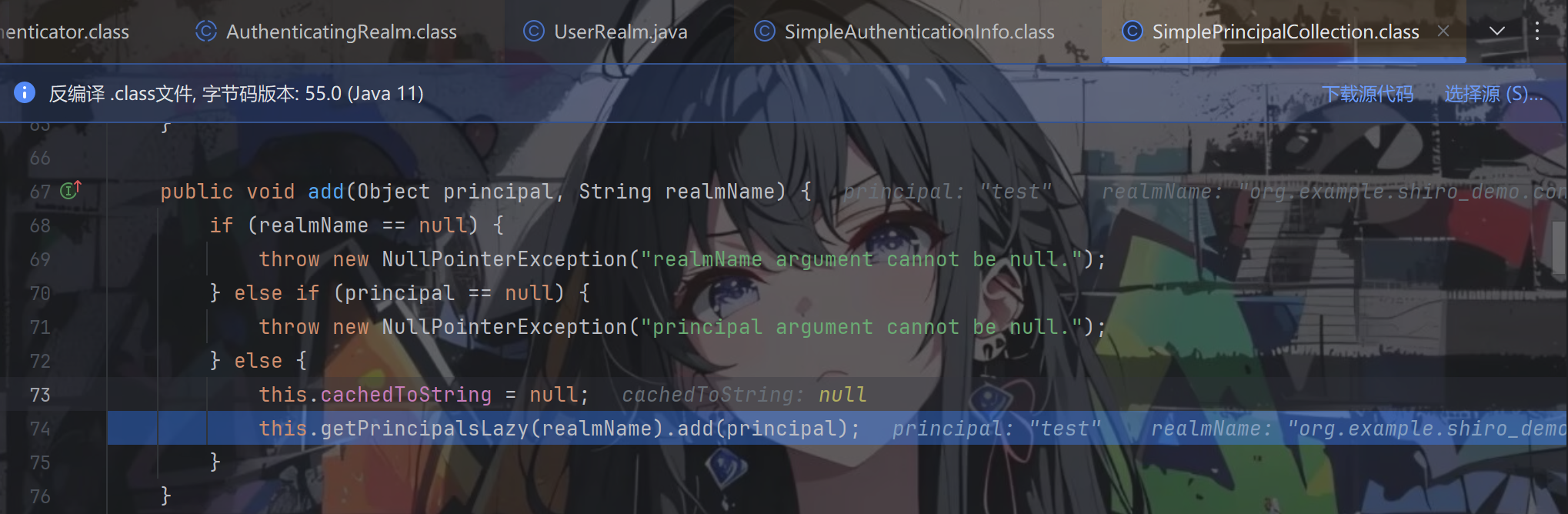
跟进getPrincipalsLazy(realmName)方法,返回的是LinkedHashSet类型
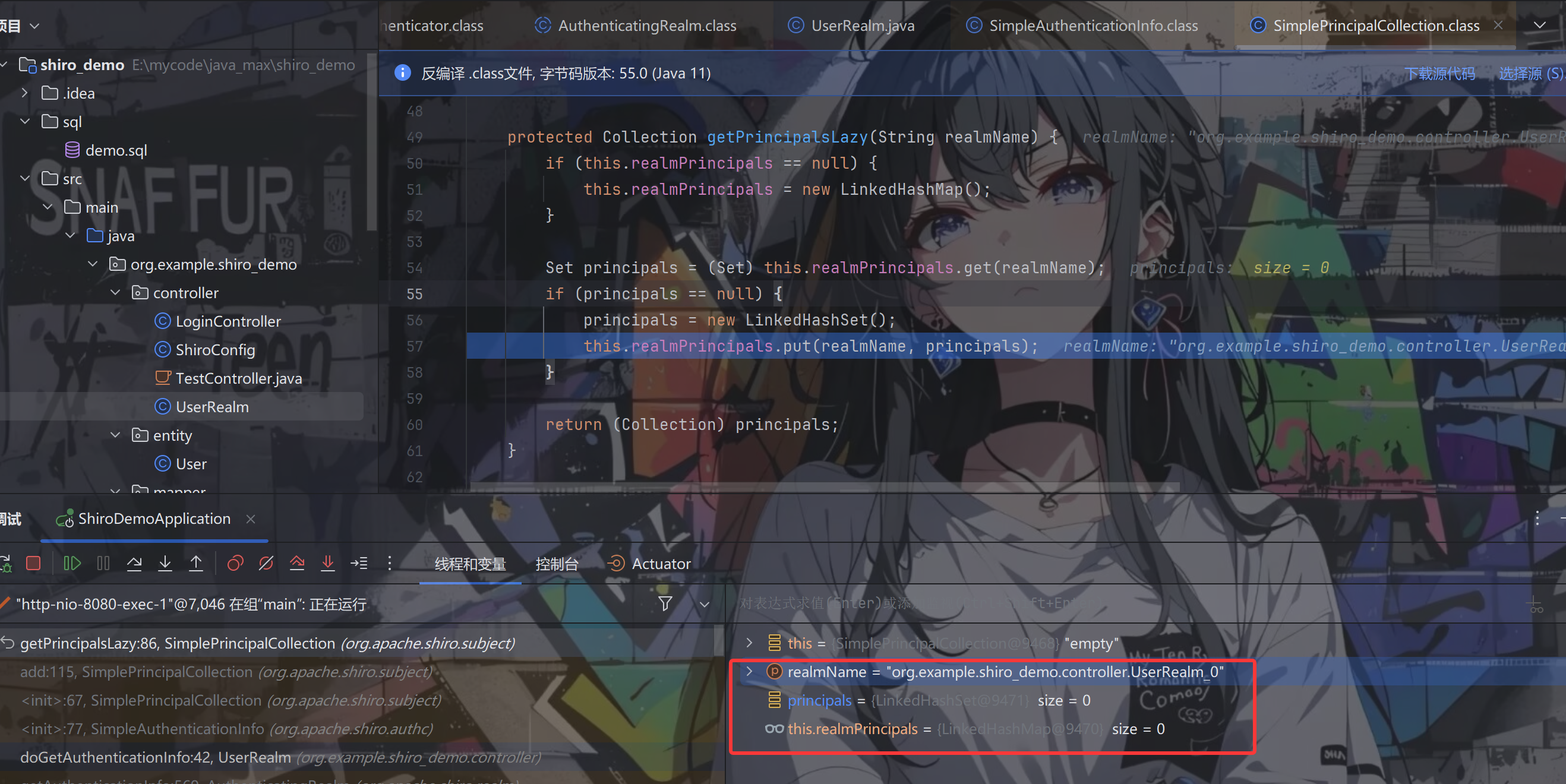
创建完了之后便一路返回到AuthenticatingRealm.getAuthenticationInfo方法
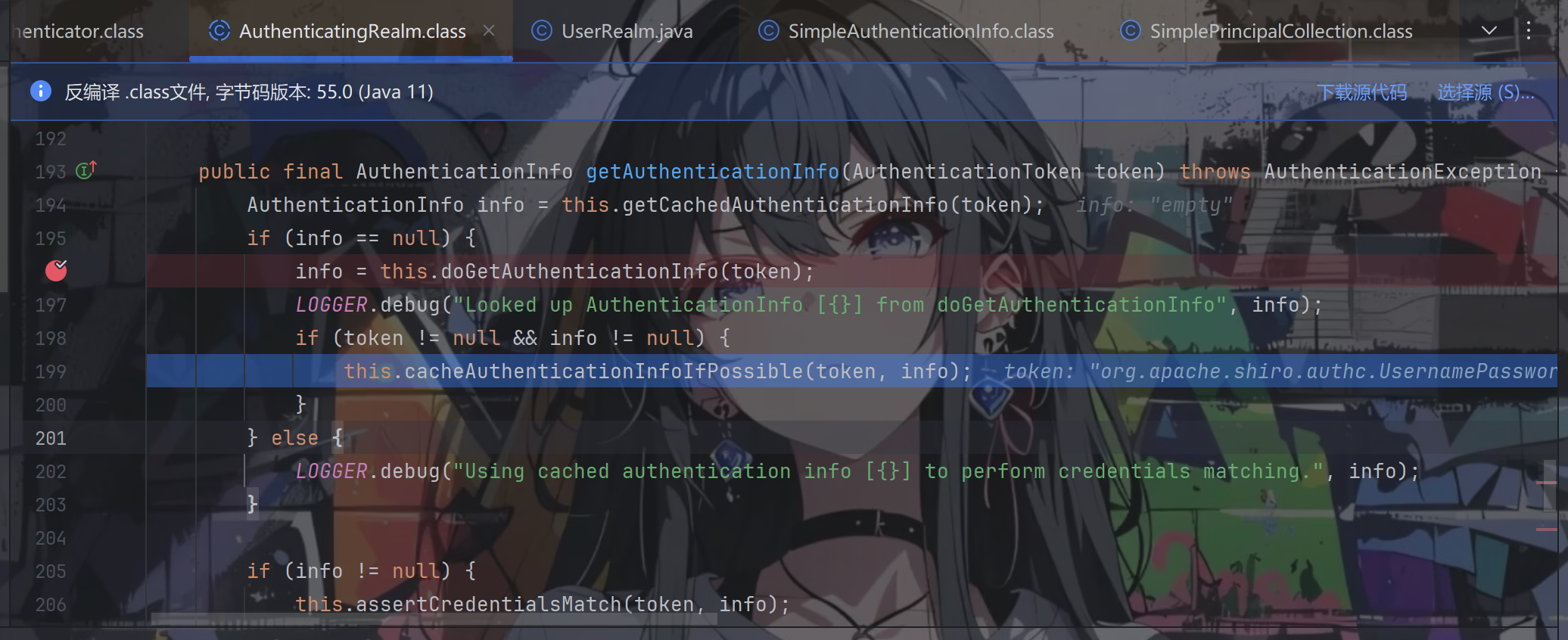
跟进cacheAuthenticationInfoIfPossible方法,可以看到token中是我们输入的密码,info中是数据库中该账号的真正密码
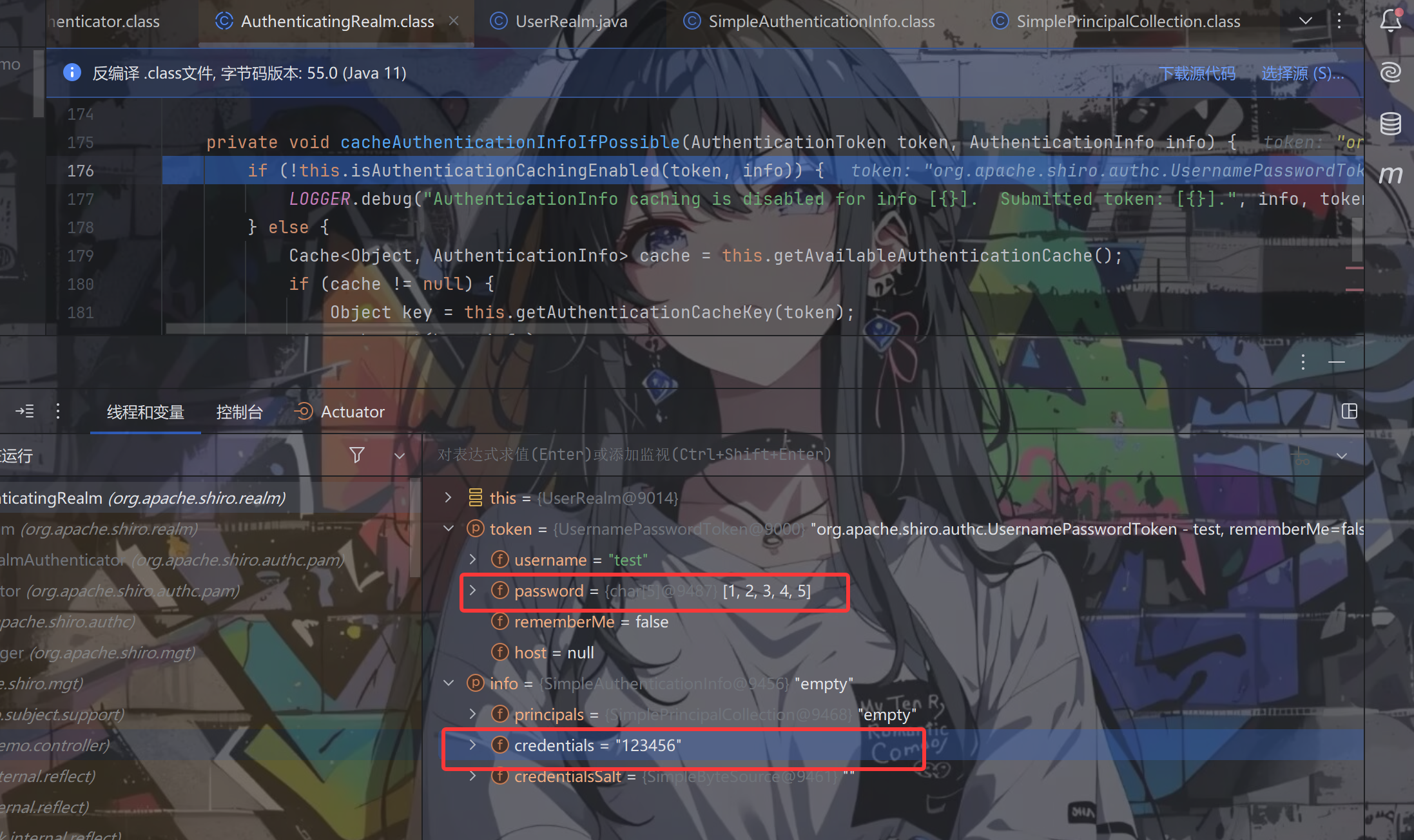
跟进isAuthenticationCachingEnabled方法,一直跟进
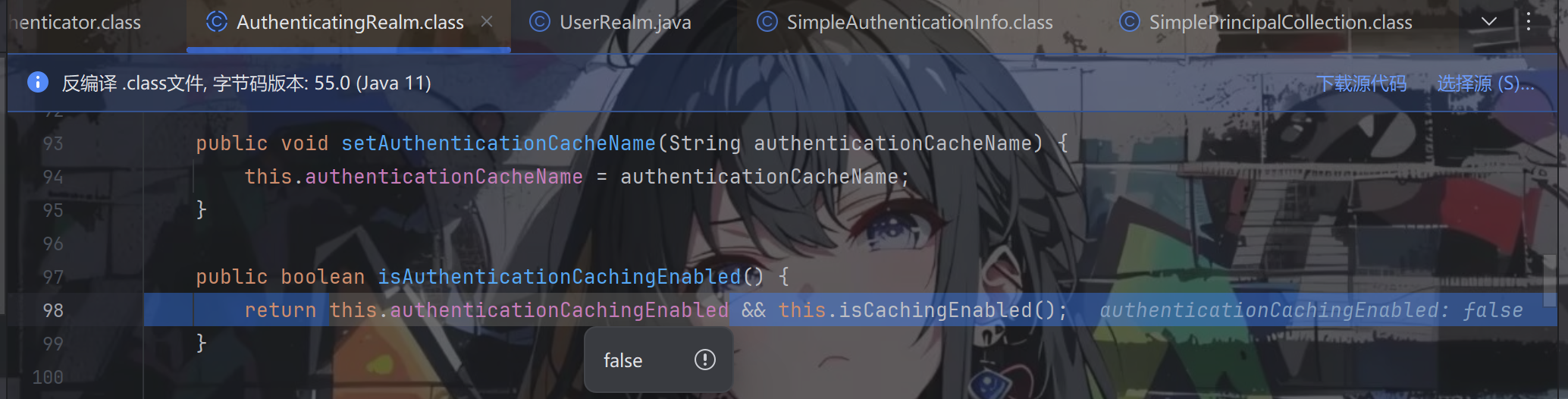
其中this.authenticationCachingEnabled默认为false,返回false
其实就是跟你说没有缓存,回到AuthenticatingRealm.getAuthenticationInfo方法,往下走
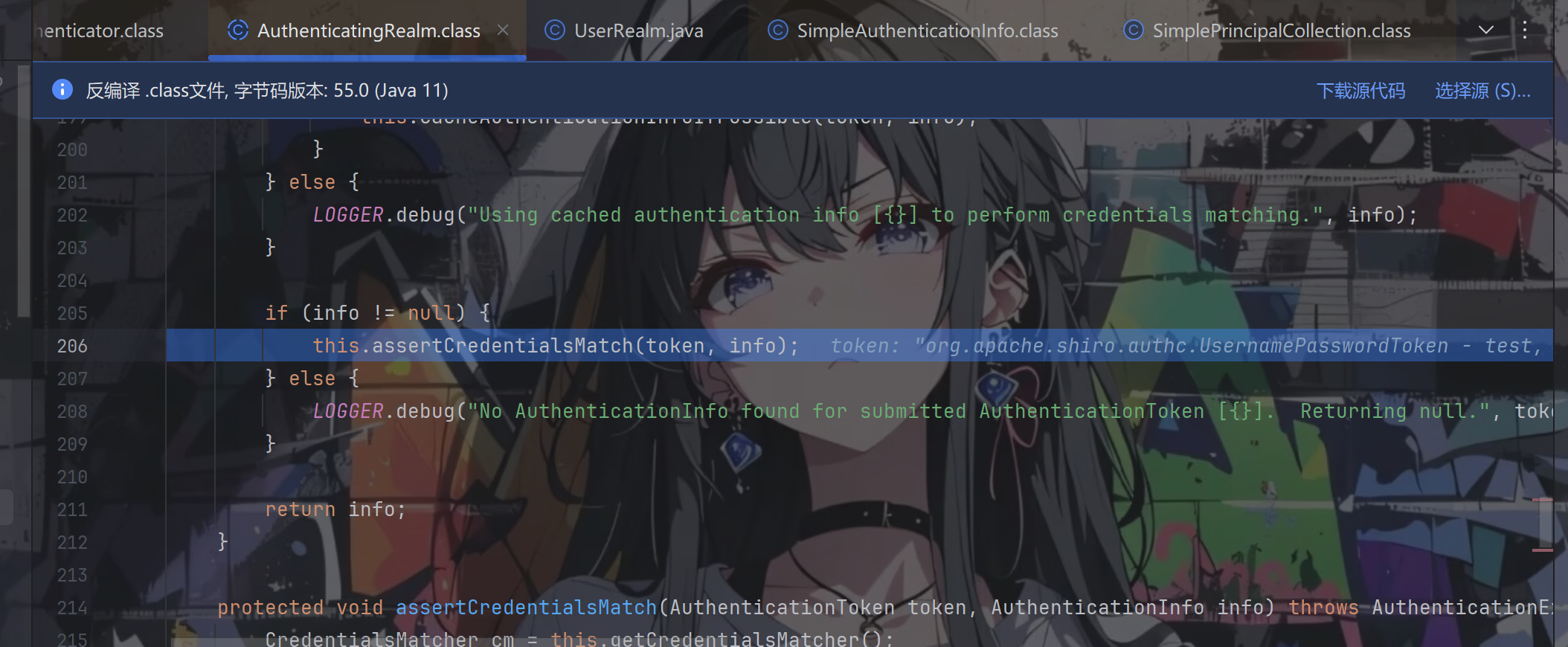
跟进assertCredentialsMatch方法
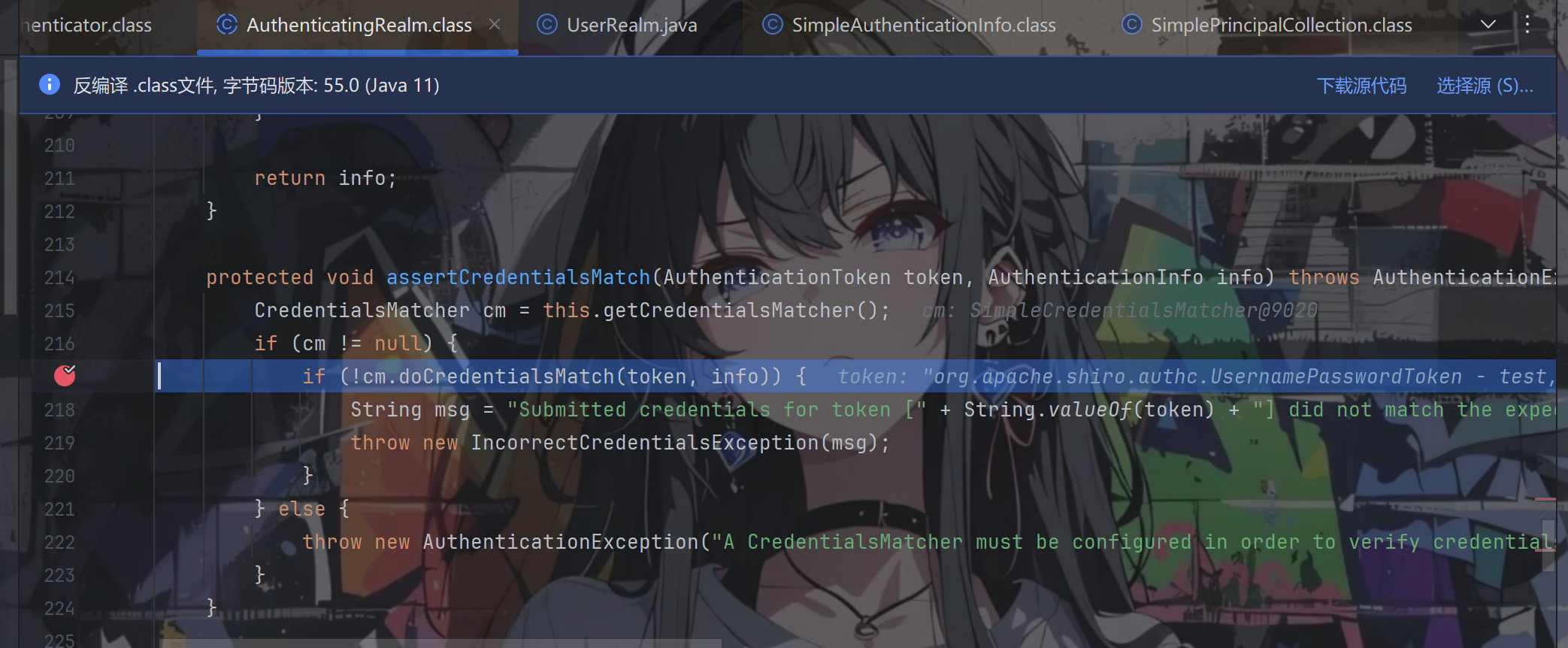
跟进doCredentialsMatch方法
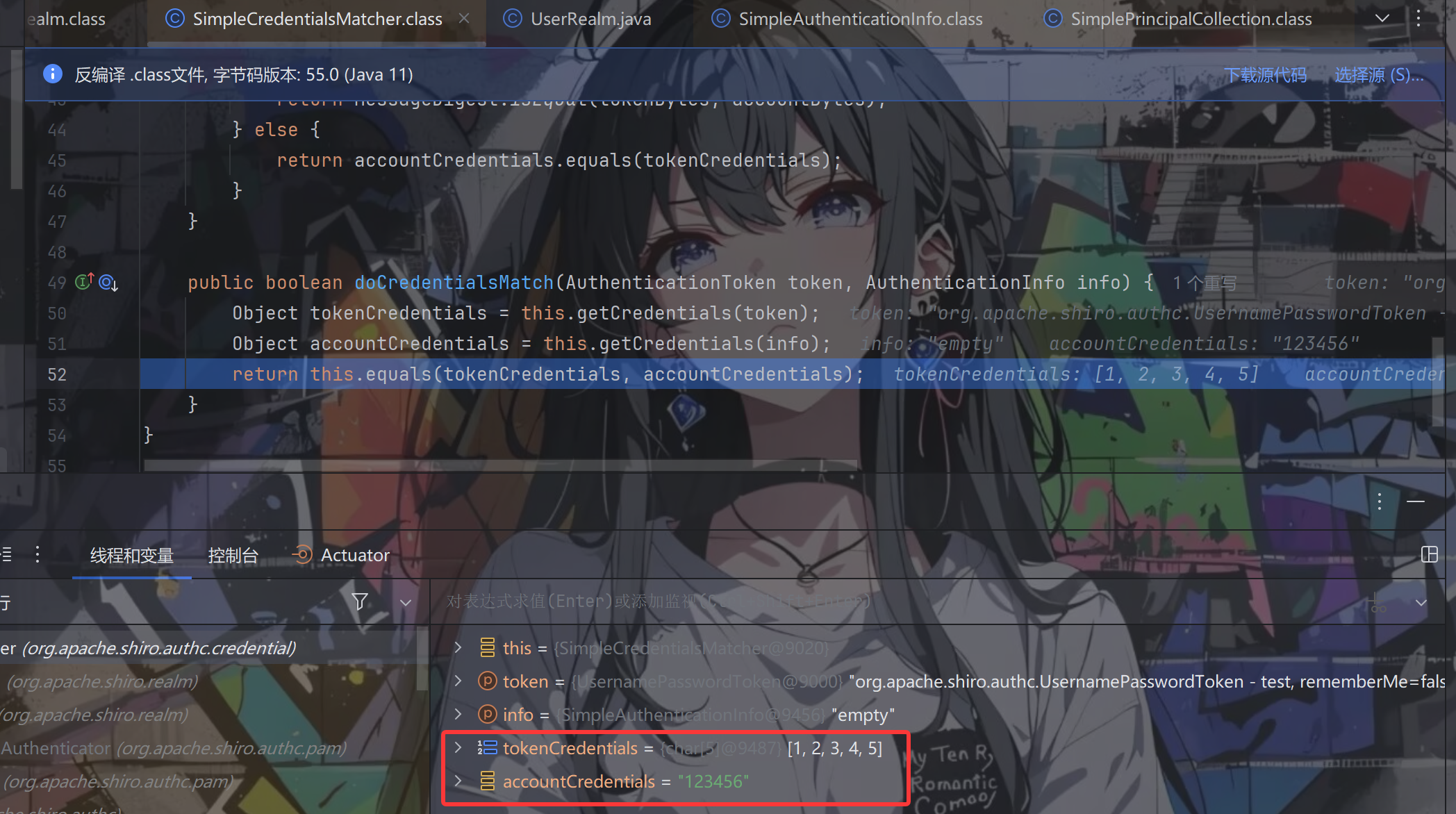
我们可以看到就是在这里面进行密码比对,看是否相等,这里明显不对,返回false
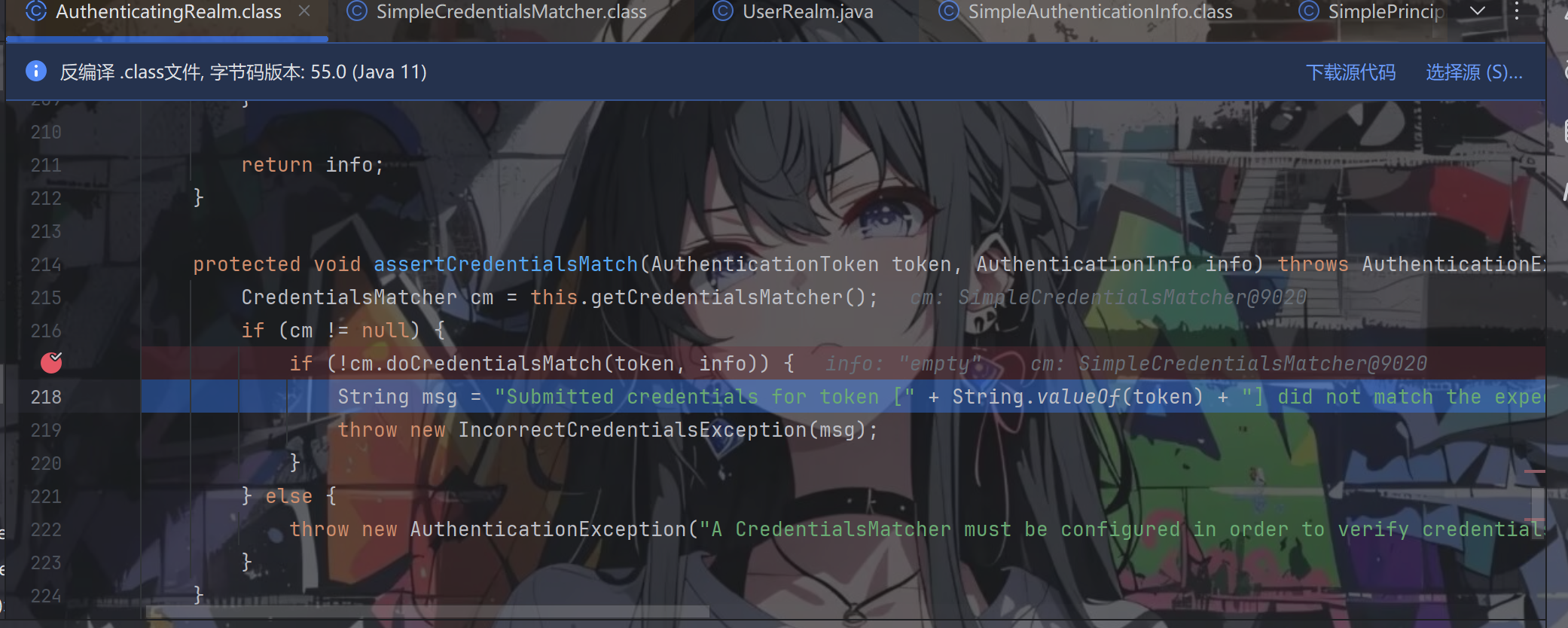
进入if从句,报错密码不正确,登录失败
登录正确的步骤也类似,这边就不继续写下去了
Shiro 权限绕过漏洞
| CVE编号 | 漏洞说明 | 漏洞版本 |
|---|---|---|
| CVE-2010-3863 | 未能对传入的 url 编码进行 decode 解码 | shrio <=1.0.0 |
| CVE-2016-6802 | Context Path 路径标准化导致绕过 | shrio <1.3.2 |
| CVE-2020-1957 | Spring 与 Shiro 对于 “/“ 和 “;” 处理差异导致绕过 | Shiro <= 1.5.1 |
| CVE-2020-11989 | Shiro 二次解码导致的绕过以及 ContextPath 使用 “;” 的绕过 | shiro < 1.5.3 |
| CVE-2020-13933 | 由于 Shiro 与 Spring 处理路径时 URL 解码和路径标准化顺序不一致 导致的使用 “%3b” 的绕过 | shiro < 1.6.0 |
| CVE-2020-17510 | 由于 Shiro 与 Spring 处理路径时 URL 解码和路径标准化顺序不一致 导致的使用 “%2e” 的绕过 | Shiro < 1.7.0 |
| CVE-2020-17523 | Shiro 匹配鉴权路径时会对分隔的 token 进行 trim 操作 导致的使用 “%20” 的绕过 | Shiro <1.7.1 |
| CVE-2021-41303 | Shiro 匹配鉴权路径时会经过多重比较 | Shiro =1.7.1 |